import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import scipy
from scipy import optimize, stats, signal, interpolate, integrate, linalg
정규분포(Normal Distribution)
- 평균
60, 표준편차 15를 갖는 정규분포에 500개의 데이터를 생성한 후 데이터의 기본 통계 정보(평균, 표준편차, 최소값, 최대값)를 출력하는 코드를 작성하세요.
data = np.random.normal(loc=60, scale=15, size=500)
DescribeResult(nobs=500, minmax=(17.371887113855024, 102.01757033697038), mean=60.16439166661173, variance=202.4669475100948, skewness=-0.01988836442802157, kurtosis=0.03347222642531866)
- 평균
50, 표준편차 10을 갖는 정규분포에서 특정 값 x = 65의 확률 밀도 함수(PDF)값을 계산하고 출력하는 코드를 작성하세요.
stats.norm.pdf(65, loc=50, scale=10)
- 평균
70, 표준편차 8을 갖는 정규분포에서 (1) 특정 값 x = 80이하일 확률을 CDF로 계산하고 (2) 상위 5%에 해당하는 점수를 PPF로 계산하여 출력하는 코드를 작성하세요.
print(stats.norm.cdf(80, loc=70, scale=8))
print(stats.norm.ppf(0.95, loc=70, scale=8))
0.8943502263331446
83.15882901561177
기술통계(Descriptive Statistics)
- 주어진 데이터에서 평균과 중앙값의 차이를 계산하는 코드를 작성하세요.
np.random.seed(42)
data = np.random.normal(loc=50, scale=10, size=100)
df = pd.DataFrame(data, columns=["value"])
np.mean(df['value']) - np.median(df['value'])
- 데이터에서 이상값(Outlier)을 찾아 제거한 후 원래 데이터와 이상값 제거 후 데이터의 평균을 비교하는 코드를 작성하세요. 이상값은 IQR(사분위 범위)를 사용하여 탐지하세요.
np.random.seed(42)
data = np.random.normal(loc=50, scale=10, size=100)
df = pd.DataFrame(data, columns=["value"])
Q1 = np.percentile(df['value'], 25)
Q3 = np.percentile(df['value'], 75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
outliers = df[(df['value'] < lower_bound) | (df['value'] > upper_bound)]
print(len(outliers))
print(outliers.reset_index())
1
index value
0 74 23.802549
- 데이터의 왜도(Skewness)와 첨도(Kurtosis)를 계산하여 데이터의 분포 특성을 분석하는 코드를 작성하세요.
np.random.seed(42)
data = np.random.normal(loc=50, scale=10, size=100)
df = pd.DataFrame(data, columns=["value"])
skew = df['value'].skew()
kurt = df['value'].kurtosis()
print(skew, kurt)
-0.1779481426259557 -0.10097745347286446
가설검정(Hypothesis Testing)
- 단일 표본 t-검정(One-Sample t-test)을 수행하여 샘플 데이터의 평균이 특정 값과 유의미한 차이가 있는지 검정하는 코드를 작성하세요. (평균
50, 표준 편차 5를 따르는 정규 분포에서 30개의 데이터를 생성하고, 해당 데이터가 평균 52와 차이가 있는지 확인하세요.)
np.random.seed(42)
sample_data = np.random.normal(loc=50, scale=5, size=30)
t_stat, p_value = stats.ttest_1samp(sample_data, 52)
print(f"t-통계량: {t_stat}")
print(f"p-값: {p_value}")
t-통계량: -3.5793224601074907
p-값: 0.0012367258279248469
- 카이제곱 검정(Chi-Square Test)을 수행하여 관측된 데이터와 기대값이 유의미한 차이가 있는지 확인하는 코드를 작성하세요.
observed = np.array([50, 60, 90])
expected = np.array([66, 66, 66]) * (observed.sum() / np.sum([66, 66, 66]))
chi2_stat, p_value = stats.chisquare(f_obs=observed, f_exp=expected)
print(f"카이제곱 통계량: {chi2_stat}")
print(f"p-값: {p_value}")
카이제곱 통계량: 13.0
p-값: 0.0015034391929775717
- 분산 분석(ANOVA, Analysis of Variance)을 수행하여 여러 그룹의 평균이 서로 다른지 검정하는 코드를 작성하세요.
np.random.seed(42)
group_1 = np.random.normal(loc=50, scale=10, size=30)
group_2 = np.random.normal(loc=55, scale=10, size=30)
group_3 = np.random.normal(loc=60, scale=10, size=30)
anova_stat, p_value = stats.f_oneway(group_1, group_2, group_3)
print(f"분산 분석 통계량: {anova_stat}")
print(f"p-값: {p_value}")
분산 분석 통계량: 12.20952551797281
p-값: 2.1200748140507065e-05
통계적 시각화(Statistical Visualization)
NumPy를 사용하여 평균 70, 표준편차 20을 따르는 정규분포 데이터 1,000개를 생성한 후, Matplotlib을 활용하여 박스플롯을 그리는 코드를 작성하세요.
np.random.seed(42)
data = np.random.normal(loc=70, scale=20, size=1000)
plt.boxplot(data)
plt.show()
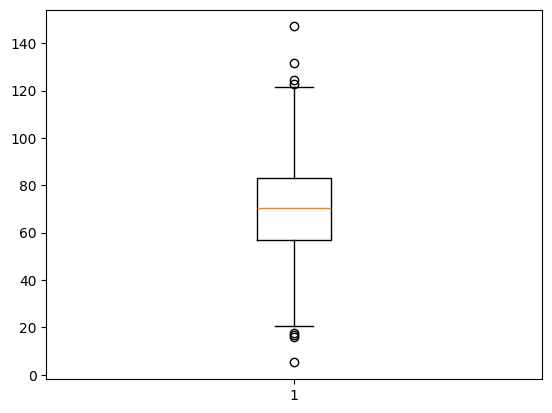
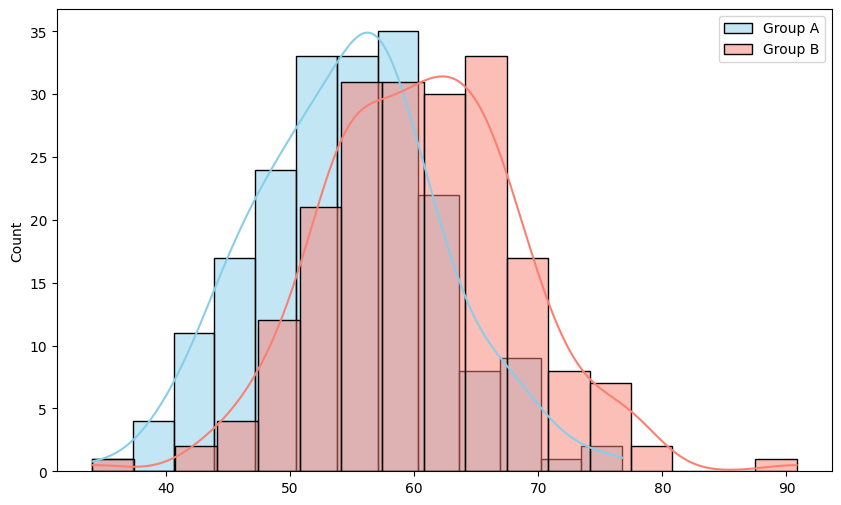
- 평균이 각각
55와 60이고, 표준편차가 8인 두 개의 그룹(A, B) 데이터를 생성한 후, 두 그룹의 데이터 분포를 Seaborn을 활용하여 KDE(커널 밀도 함수)와 함께 히스토그램으로 시각화하세요. 이후 두 그룹 간 평균 차이가 유의미한지 t-검정을 수행하는 코드를 작성하세요.
np.random.seed(42)
group_A = np.random.normal(loc=55, scale=8, size=200)
group_B = np.random.normal(loc=60, scale=8, size=200)
plt.figure(figsize=(10, 6))
sns.histplot(group_A, kde=True, color='skyblue', label='Group A', alpha=0.5)
sns.histplot(group_B, kde=True, color='salmon', label='Group B', alpha=0.5)
plt.legend()
plt.show()
t_stat, p_value = stats.ttest_ind(group_A, group_B)
print(f"t-통계량: {t_stat}")
print(f"p-값: {p_value}")
t-통계량: -7.834368710058932
p-값: 4.335288307834178e-14
- 광고 A를 본 500명 중 120명이 클릭하였고, 광고 B를 본 500명 중 150명이 클릭을 한 데이터가 있습니다. 이 데이터를 바탕으로 카이제곱 검정을 수행하여 광고 A와 B의 클릭률 차이가 유의미한지 분석하고, Seaborn의 barplot을 사용하여 클릭률을 비교하는 그래프를 그리는 코드를 작성하세요.
observed_data = pd.DataFrame({
"Ad_A": [120, 380],
"Ad_B": [150, 350]
}, index=["Click", "No Click"])