OnTheTop Service
프로젝트 소개
OnTheTop
- 데스크 테리어에 관심있는 사람들을 위해 생성형 AI 기반으로 퍼스널 데스크 특가 정보를 제공
- 사용자의 데스크 셋업 이미지를 분석해 어울리는 아이템 이미지를 생성하고 클릭하면 바로 구매할 수 있는 쇼핑 링크를 제공
주요기능
- 사용자가 업로드한 책상 이미지를 AI가 분석하여 데스크 환경을 인식하고 어울리는 데스크 아이템을 추천
- 추천된 아이템을 Diffusion 모델을 기반으로 추천 데스크 셋업 이미지 생성
- 생성된 이미지를 기반으로 추천된 아이템을 구매할 수 있는 쇼핑 링크 제공
- 다양한 Style LoRA를 적용하여 MSPainting Style, Oil Painting Style, Cartoon Style 등 이미지 스타일 변경 기능 제공
AI Server Architecture
Folder
OTT_AI_Server
├── app
│ ├── core
│ │ ├── config.py
│ │ └── logging_config.py
│ ├── main.py
│ ├── routers
│ │ ├── __init__.py
│ │ ├── healthcheck.py
│ │ └── info.py
│ ├── services
│ │ ├── __init__.py
│ │ ├── backend_notify.py
│ │ ├── desk_classify.py
│ │ ├── gpt_api.py
│ │ ├── groundig_dino.py
│ │ ├── masking.py
│ │ ├── naverapi.py
│ │ ├── sam.py
│ │ └── sdxl_inpainting.py
│ ├── shutdown.py
│ ├── startup.py
│ └── utils
│ ├── clear_cache.py
│ ├── delete_image.py
│ ├── load_image.py
│ ├── mapping.py
│ ├── queue_manager.py
│ ├── s3.py
│ └── upscaling.py
├── README.md
├── requirements.txt
└── scripts
├── ai-server.service
├── start-ai.sh
└── stop-ai.sh
Base Model
- Base Model로 Stable Diffusion XL 선정
- 다른 AI 모델들에 비해 적은 VRAM을 차지하며 생성 속도 또한 빠르기 때문에 가성비가 좋다.
- LoRA를 이용한 Fine Tuning이 가능하여 원하는 이미지 생성이 가능하다.
- 다른 AI 모델과의 비교는 Github Wiki 참조
Stable Diffusion XL
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis에 따르면 SDXL은 이전 Stable Diffusion 모델에 비해 세 배 더 큰 규모의 UNet 백본을 포함하며 2개의 텍스트 인코더를 사용해 더 나은 성능을 보여준다. 또한 후작업(refinement)모델이 도압되어 prompt 일관성과 고화질 유지를 모두 달성할 수 있다고 한다.
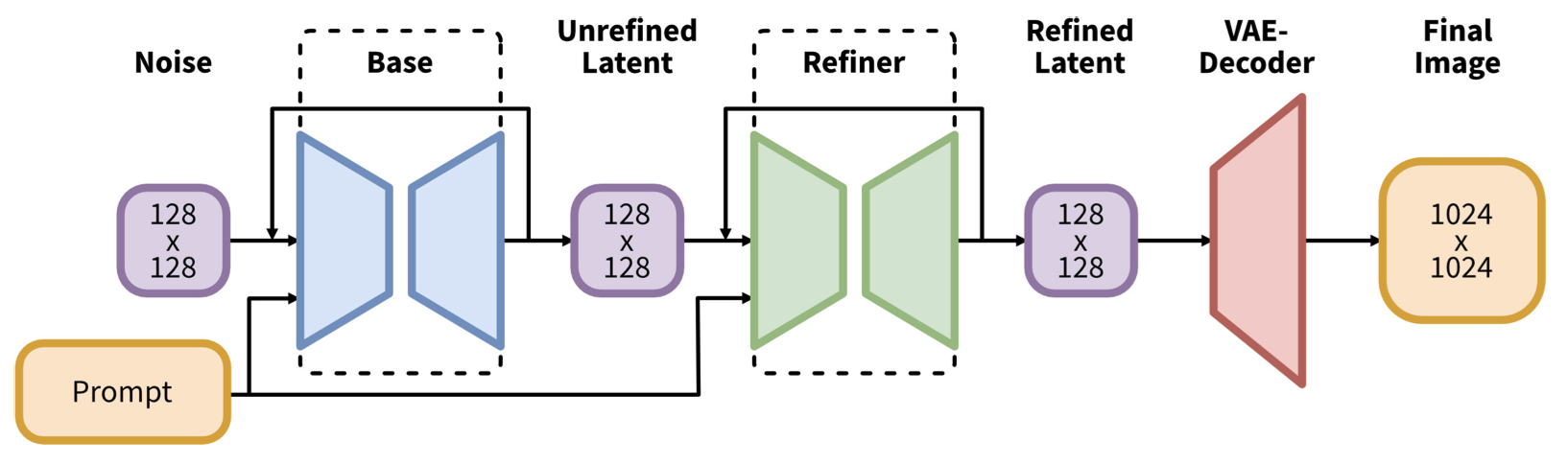
SDXL의 아키텍처를 보면 Base 부분은 UNet 기반의 확산 모델로 Prompt와 Noise를 입력받아 Unrefiend Latent를 생성한다. Unrefined Latent는 아직 세부 디테일이 부족한 상태로 Refiner Model를 통해 세부 묘사 및 시각적 품질을 개선하는 방식으로 작동된다. 마지막으로 VAE-Decoder를 통해 latent 공간을 실제 이미지 공간으로 복원하게 되며 여기서 128x128 latent를 1024x1024 해상도로 업스케일 된다.
UNet
UNet이라는 이름이 붙여진 이유는 구조가 ‘U’자 형태를 띄기 때문이다. 기본적으로는 오토인코더와 같은 인코더-디코더 기반 모델에 속한다.
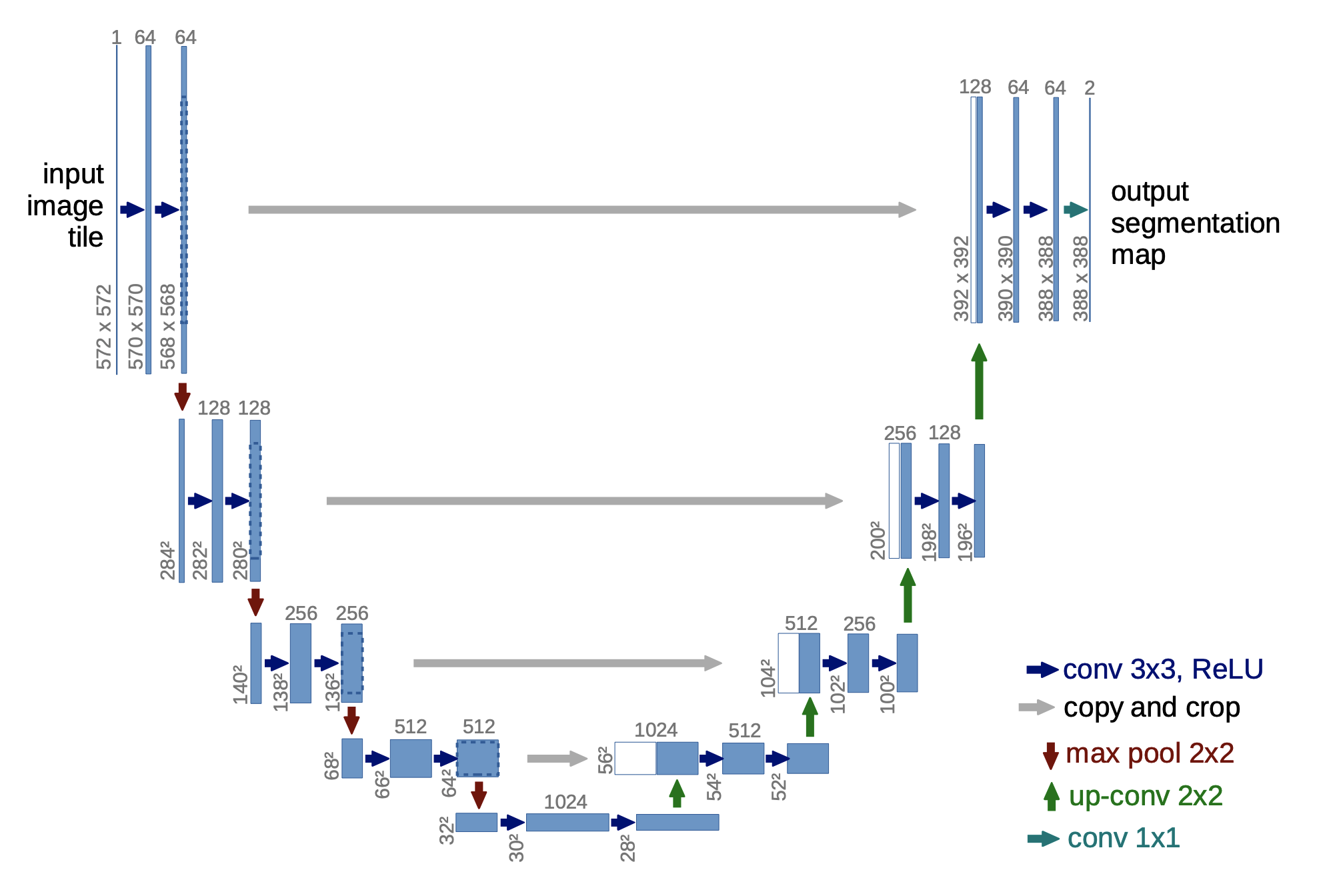
UNet은 크게 Contracting Path(축소 경로)와 Expansive path(확장 경로)로 이루어진다. Contracting path는 일반적인 CNN과 유사하며 이미지의 정보 추출의 목적이다. Expanding path는 Up-convolution을 사용해 해상도를 증가시키며 정확학 경계 정보 유지와 세밀한 Feature 복원이 주 목적이다.
Stable Diffusion XL의 UNet Block의 구조는 아래와 같다.
conv_in
down_blocks:
DownBlock2D:
(ResnetBlock2D) x 2
Downsample2D
CrossAttnDownBlock2D:
(ResnetBlock2D
Transformer2DModel (BasicTransformerBlock x 2) ) x 2
Downsample2D
CrossAttnDownBlock2D:
(ResnetBlock2D
Transformer2DModel (BasicTransformerBlock x 10) ) x 2
mid_blocks:
ResnetBlock2D
Transformer2DModel
ResnetBlock2D
up_blocks:
CrossAttnUpBlock2D:
(ResnetBlock2D
Transformer2DModel (BasicTransformerBlock x 10) ) x 3
Upsample2D
CrossAttnUpBlock2D:
(ResnetBlock2D
Transformer2DModel (BasicTransformerBlock x 2) ) x 3
Upsample2D
UpBlock2D:
(ResnetBlock2D) x 3
out
Stable Diffusion의 UNet 구조의 특징은 Self-Attention과 Cross-Attention의 개념이 사용된다.
두 개념은 일반적으로 Transformer 기반에서 사용되는 개념으로 Self-Attention은 자기 자신과의 관계에 주목하며, Cross-Attention은 두 입력 간의 관계에 주목하게 된다. Stable Diffusion에서는 Self-Attention은 이미지 latent 내부의 위치 간 관계를 파악해 자연스러운 구조, 질감을 형성하며 Cross-Attention은 텍스트 임베딩과의 관계를 통해 텍스트 조건에 맞는 이미지를 생성하게 된다.
LoRA
일반적으로 사전학습 된 LLM은 Full-Fine tuning 방식은 모든 파라미터 업데이트로 인해 계산 비용, GPU 메모리, 저장 공간 부담이 크다. GPT-3가 175B 이므로 Full-Fine tuning을 한다면 약 1750억개의 파라미터를 저장해야한다.
LoRA는 기존 모델의 가중치를 학습 중 직접 수정하지 않고 보정행렬을 삽입하여 fine tuning하는 방법이다.
사전학습된 모델 가중치 $W$는 동결하고 작은 저차원 행렬 $A (r \times k)$와 $B (d \times r)$를 추가학습하여
\(\Delta W = BA, W' = W + \Delta W\)
형태로 표현할 수 있다.
Stable Diffusion에서는 UNet내부 Attention에 적용되며 선형 projection 레이어에만 적용된다.
\(W_qx \Rightarrow \left ( W_q + \frac{\alpha}{\gamma}B_q A_q \right )x\)
위의 수식과 같은 방식으로 $Q$, $K$, $V$, $O$(Out projection)에 $\Delta W$가 붙게 된다.
기존의 Weight의 구조가 $Q = x \cdot W_q$라면
.load_lora_weight() 메서드 적용후에는 $Q = x \cdot W_q + (x \cdot A_q)B_q$의 구조가 된다.
LoRA 학습
- LoRA의 경우 kohya_ss를 사용하여 Custom 학습 하였다.
- 학습 이미지의 경우 GPT-4o 이미지 생성 기능을 이용해 깔끔한 Desksetup 기반 이미지 121장(1024x1024)을 추출하여 학습에 사용하였다.
- 이미지 예시



Desk Classify
- Desk Classify 목적 설명
- CNN 학습 및 경량화 과정
- Desk Classify가 가져온 이점
Grounding DINO
- Grounding DINO 목적 설명 YOLO와의 비교
- Grounding DINO의 Output 값 등 설명
SAM2.1
- SAM2 논문 소개하며 SAM2 기능 설명
- Segmentation 설명 및 단점 등 설명
- Mask Image 처리 과정 설명 등
Major Update
- 주요 업데이트 설명 및 트러블 슈팅 과정을 설명
Test Version
- CNN 도입 과정 설명
V1
- LoRA학습 및 img2txt -> txt2img pipeline 설명
V2
- Inpainting 도입과정 설명 및 Grounding DINO, SAM2.1을 이용한 Auto Masking Process 설명
- Style LoRA 적용
V3
- Redis를 응용한 Multi-GPU