Feature Map 기반 CNN 모델 최적화
1. 서론
최근 다양한 CNN(Convolutional Neural Network) 기반의 이미지 분류 모델들이 제안되며 이미지 인식 분야에서 뛰어난 성능을 보이고 있다. 하지만 이러한 모델들은 구조의 복잡성이나 파라미터 수에 따라 연산 비용과 메모리 사용량에 큰 차이를 보이며, 특히 데이터셋의 특성에 따라 성능 및 효율성이 달라질 수 있다.
실제 응용 환경에서는 모델의 경량화 또한 중요한 과제로 떠오르고 있다. 모바일 기기, 임베디드 시스템, 자동화 기계 등에서는 모델의 정확도뿐만 아니라 처리 속도와 자원 효율성이 중요한 요소로 작용하기 때문이다.
따라서 본 프로젝트에서는 ‘Rice Image Dataset’을 활용하여 여러 CNN 기반 모델들이 해당 데이터셋에서 어떤 성능을 보이는지 비교하고 모델별 특징 및 효율성을 분석하고자 한다. 특히, 이미지 분류 과정에서 생성되는 Feature map을 시각화함으로써 각 모델이 어떤 방식으로 이미지를 인식하고 구분하는지 직관적으로 이해하고자 하였다.
이를 통해 더 이상 특징을 제대로 추출하지 못 하는 Layer를 일부 제거하거나 Filter의 수를 줄임 성능저하 없이 예측 효율성을 개선할 수 있는 가능성도 살펴보고자한다. 이러한 분석을 통해 단순 정확도 비교를 넘어서 실제 응용에 적합한 효율적인 모델을 선정하기 위한 방법을 살펴보고자 한다.
(1) 모델 경량화
모델 경량화가 필요한 이유는 다양하지만 비용적 문제가 크다. 모델이 크고 계산량이 많아질수록 전력 소비량이 늘어나고 열 발생량도 높아진다. 심지어 최근에는 스마트폰, IoT 기기 등에도 탑재하고자 노력 중이다. 따라서 모델이 가볍고 성능은 뒤떨어지지 않는 것이 중요하다.
모델 경량화의 Solution은 Pruning, Quantization, Knowledg Distillation 등 다양하게 존재한다. 하지만 본 프로젝트에서는 Filter를 통과한 Featrue Map을 시각화하여 불필요한 Filter를 삭제해봄으로써 모델 경량화를 하고자 한다.
또한 모델을 경량화하다보면 일반화 성능이 좋아지는 부수적인 이득을 볼 수 있다. 따라서 모델을 경량화 해보면서 각 모델의 일반화 성능을 살펴볼 것이다.
(2) Feature Map

CNN은 Convolution Layer를 통해 이미지의 주요 특징을 추출하며 이때, 각 필터를 통과한 결과가 Feature Map으로 생성된다. 이후 이 Feature Map은 Pooling Layer를 거쳐 중요한 특징을 강조하고 불필요한 정보를 축소하게 된다. 이러한 과정을 반복한 후에는, 최종적으로 Fully Connected Layer에 전달되어 우리가 흔히 알고 있는 인공신경망(ANN) 구조처럼 분류 작업을 수행하게 된다.
예를 들어 고양이 사진을 CNN구조인 VGG16에 통과시키면 아래와 같은 Feature Map을 얻을 수 있다.
이미지 출처 LifeofPy, CNN의 정의, 이미지의 feature map 기능과 kernel(filter)의 개념
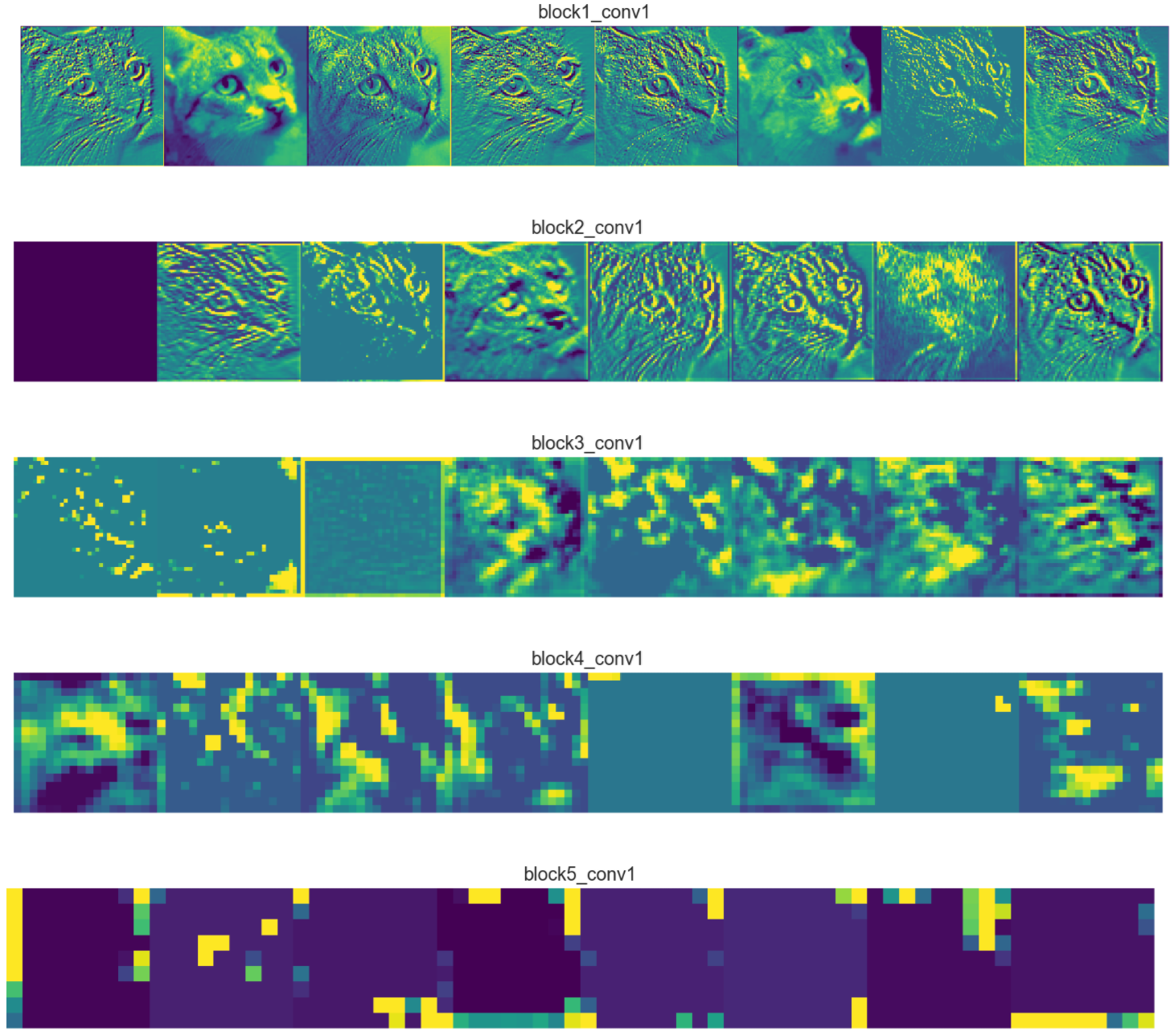
하지만 본 프로젝트에서 사용하는 ‘Rice Image Dataset’의 경우 CNN의 층이 깊어질수록 불필요한 특징이 잡힐 수 있다. 해당 Dataset을 VGG16에 통과시킨 후의 Feature Map의 차이를 보면 아래와 같다.

위의 Feature Map은 VGG16의 첫 번째 Convolution Layer를 통과한 이미지이다.

해당 Feature Map은 VGG16의 마지막 Convolution Layer를 통과한 이미지이다. 모든 Filter에 대한 Featrue Map을 출력한 것은 아니지만 대부분의 Filter가 특징을 추출하지 못한 채 모두 검정색임을 알 수 있다. 해당 현상은 Fully Connected Layer에서 문제가 발생할 수 있다.
(3) Feed Forward 관점
Convolution → ReLU → MaxPooling 형태의 CNN 층을 수식으로 표현하면 아래와 같다.
$X \in \mathbb{R}^{C_{in}\times H \times W}$
$W \in \mathbb{R}^{C_{out}\times C_{in} \times K’ \times K}$
$b_i \in \mathbb{R}$
출력 채널 $i$, 위치 $(m, n)$에서의 convolution 출력은 아래의 식과 같다.
ReLU는 음수를 0으로 만들고 양수는 그대로 유지하므로 아래의 식과 같다.
$2 \times 2$ 커널에서의 Max Pooling은 아래의 식과 같다.
Feature Map의 모든 값이 0일 경우, 다음과 같이 출력된다.
이처럼 Feature Map이 0으로 채워져 있을 경우, ReLU 및 Pooling을 통과한 이후에도 출력값은 여전히 0이다.
Fully Connected Layer는 $y = Wx + b$로 표현되므로
모든 입력값 $x = 0$ 이라면, 출력 $y$는 오직 bias$(b)$에만 의존하게 된다.이 상황에서는 실제 이미지로부터 추출한 특징이 전혀 반영되지 않으며 모델은 유의미한 학습이 불가능하게 된다.
결국 이는 모델이 정답을 무작위로 선택하는 것과 유사한 상태로 이어질 수 있다.
(4) Backpropagation 관점
Backpropagation의 관점에서 보면, Fully Connected Layer(FCL)의 입력값이 모두 $x=0$ 인 경우, Convolution Layer의 필터는 업데이트되지 않게 된다.
FCL을 $y = \phi(Wx+b)$로 표현할 수 있을 때, $x = 0$이면 $y = \phi(b)$가 된다. 해당 상황에서 FCL의 가중치 $W$에 대한 손실함수의 기울기를 구하면 다음과 같다.
\(\frac{\partial L}{\partial W} = \frac{\partial L}{\partial y} \cdot \phi '(b) \cdot x^{T} = 0\)
따라서 FCL의 가중치는 학습되지 않으며 오직 bias의 영향만 받게 된다.
입력 $X$에 대하여 Convolution → ReLU → Pooling 순으로 연산이 이루어진다고 할 때, Convolution Layer의 weight $W_{conv}$에 대한 기울기는 다음과 같이 chain rule로 표현된다.
\(\frac{\partial L}{\partial W_{conv}} = \frac{\partial L}{\partial A} \cdot \frac{\partial A}{\partial Z} \cdot \frac{\partial Z}{\partial W_{conv}}\)
앞서 구한 바와 같이 $\frac{\partial L}{\partial W} = 0$이므로 $\frac{\partial Z}{\partial W_{conv}} = 0$ 이다. 이로인해 Convolution Layer의 필터 역시 학습되지 않게 된다. 결국 bias만 업데이트 되며 의미 없는 학습이 반복될 뿐이다.
이론적으로도 마지막 Feature Map의 모든 값이 0인 경우에는 학습이 이루어지지 않으며 이는 실험적으로도 관찰 가능하다. 본 프로젝트에서는 Feature Map을 grayscale로 출력하였기 때문에 모든 채널(R, G, B)이 동시에 0인지를 정확히 시각적으로 판단하기는 어렵지만, GoogLeNet을 이용해 이를 간접적으로 확인할 수 있었다.
GoogLeNet의 대표적인 특징은 1×1 Convolution 연산이다. 이 연산은 Feature Map의 공간적 크기를 유지하면서 채널 수를 줄이는 역할을 한다. 즉, RGB 각각의 특성이 하나의 채널로 압축되는 구조로, 학습이 충분히 진행되지 않은 경우 Feature Map 전체가 0으로 수렴할 가능성도 상대적으로 높아진다.
또한 GoogLeNet은 총 27개의 Layer로 구성된 깊은 구조이기 때문에, 학습이 불안정하거나 정보가 사라질 경우 Feature Map이 0으로 소멸될 위험성도 다른 모델보다 더 클 수 있다.
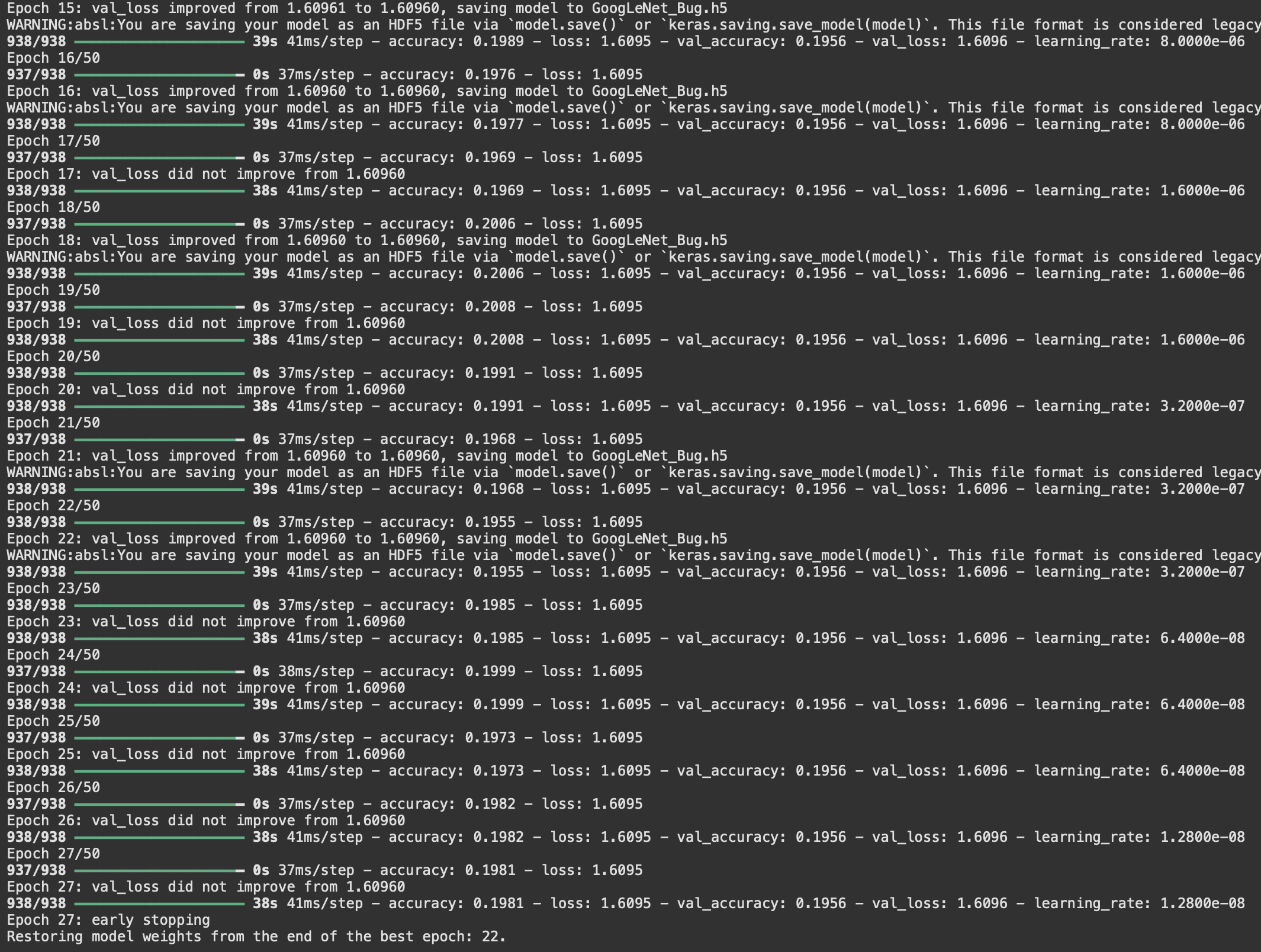
아래의 내용은 실제 weight를 초기화 해보면서 학습을 시도한 결과 얻은 GoogLeNet 학습 결과이다. 학습 로그에서 확인할 수 있듯이 학습이 진행되는 동안 ‘val_accuracy’는 0.1956, ‘val_loss’는 1.6096에서 변하지 않고 반복되었다. 이는 Backpropagation이 정상적으로 이루어지지 않고 bias만 업데이트 되는 현상이 발생했을 가능성이 크다.
학습 불가 Colab Link, 프로젝트 Colab Link 두 링크를 통해 비교해보면 코드는 같은 걸 알 수 있다.
Cross-Entropy Loss는 아래와 같이 정의된다.
\(L = -\sum _ {i=1} ^{C} y_{i} \cdot \log(\hat{y}_{i})\)
모델이 모든 클래스를 동일한 확률로 예측한다면 각 클래스의 예측 확률은 $\hat{y}_{i} = \frac{1}{C}$이다. 그리고 Cross-Entropy는 정답 클래스에만 적용되므로 $L = \log(C)$가 된다. 즉, 무작위 추측 시의 Cross-Entropy Loss는 $\log(C)$가 된다.
따라서 Class수가 5일 때, 무작위 추측 시 Cross-Entropy Loss는 $\log(5) \approx \ln(5) \approx 1.609$이다. 따라서 ‘val_loss’가 1.609에서 멈춰 있다는건 모델이 학습을 하지 못하고 무작위로 예측하고 있다는 강력한 증거이다.
2. 데이터셋 설명
본 프로젝트에서 사용한 데이터셋은 Kaggle의 ‘Rice Image Dataset’으로 Murat Koklu에 의해 제공되었다.
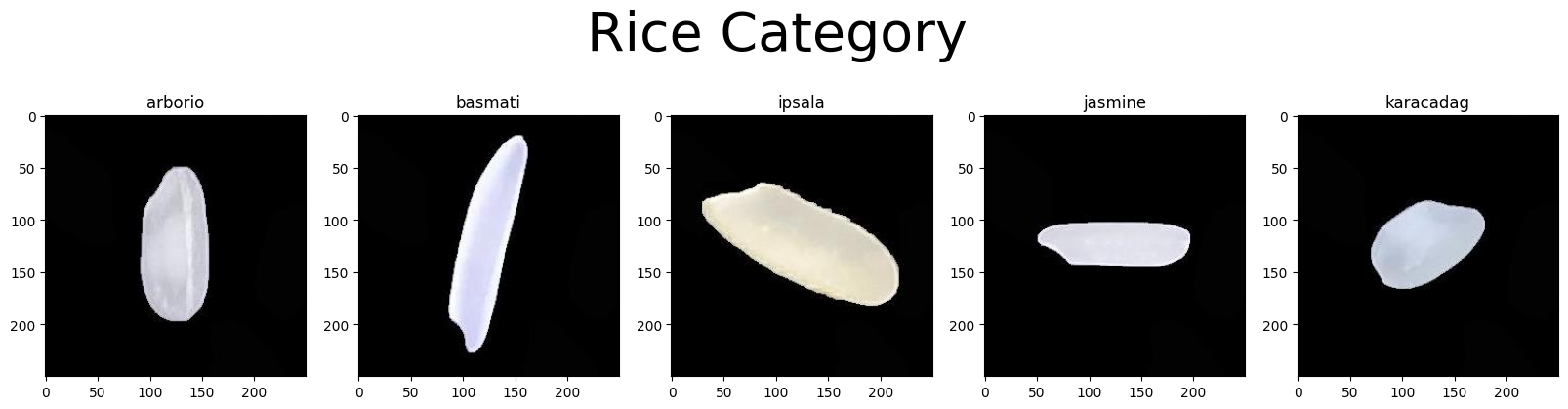
해당 데이터셋은 Arborio, Basmati, Ipsala, Jasmine, Karacadag로 총 5가지 class로 구분되어 있으며 각 데이터는 15,000개로 총 75,000개의 .jpg 이미지로 구성되어있다.
각 이미지는 250x250 픽셀 크기를 가지며 검은 배경 위에 단일 쌀알이 위치한 형태로 구성되어 있다. 이미지들은 쌀알 이외의 잡음은 없고 배경과 객체가 명확히 구분되도록 전처리 되어있어 이미지 분류 모델 학습에 적합한 데이터이다.
(1) Data Load
- Kaggle을 이용한 Data Load
!kaggle datasets download -d nuratkokludataset/rice-image-dataset
!unzip rice-image-dataset.zip -d rice_dataset
- Dataset 확인
해당 데이터는 folder로 class화 해놓았기 때문에 folder별로 class index를 붙여주어야 한다.
dataset_path = '.../rice_dataset/Rice_Image_Dataset'
class_folders = [f.name for f in os.scandir(dataset_path) if f.is_dir()]
num_classes = len(class_folders)
print("Class Folders:", class_folders)
print("Number of Classes:", num_classes)
Class Folders: ['Ipsala', 'Arborio', 'Karacadag', 'Jasmine', 'Basmati']
Number of Classes: 5
path = pathlib.Path(dataset_path)
arborio = list(path.glob('Arborio/*.jpg'))
basmati = list(path.glob('Basmati/*.jpg'))
ipsala = list(path.glob('Ipsala/*.jpg'))
jasmine = list(path.glob('Jasmine/*.jpg'))
karacadag = list(path.glob('Karacadag/*.jpg'))
print(f'Arborio: {len(arborio)}')
print(f'Basmati: {len(basmati)}')
print(f'Ipsala: {len(ipsala)}')
print(f'Jasmine: {len(jasmine)}')
print(f'Karacadag: {len(karacadag)}')
rborio: 15000
Basmati: 15000
Ipsala: 15000
Jasmine: 15000
Karacadag: 15000
basmati_img = img.imread(basmati[0])
arborio_img = img.imread(arborio[0])
ipsala_img = img.imread(ipsala[0])
jasmine_img = img.imread(jasmine[0])
karacadag_img = img.imread(karacadag[0])
fig,ax = plt.subplots(ncols=5, figsize=(20,5))
fig.suptitle ('Rice Category', fontsize=40)
ax[0].set_title("arborio")
ax[1].set_title("basmati")
ax[2].set_title("ipsala")
ax[3].set_title("jasmine")
ax[4].set_title("karacadag")
ax[0].imshow(arborio_img)
ax[1].imshow(basmati_img)
ax[2].imshow(ipsala_img)
ax[3].imshow(jasmine_img)
ax[4].imshow(karacadag_img)
plt.show()
3. 모델 구성
(1) CNN
-
일반적인 CNN으로 Convolution → ReLu → MaxPooling 으로 3개 층으로 쌓아보았으며 필터의 개수는 32 → 64 → 128 개를 사용하여 Feature Map을 시각화 하였다.
def cnn(input_shape, num_classes): inputs = tf.keras.Input(shape=input_shape) x = tf.keras.layers.Conv2D(32, (3,3), activation='relu', padding='same')(inputs) x = tf.keras.layers.MaxPooling2D((2,2))(x) x = tf.keras.layers.Conv2D(64, (3,3), activation='relu', padding='same')(x) x = tf.keras.layers.MaxPooling2D((2,2))(x) x = tf.keras.layers.Conv2D(128, (3,3), activation='relu', padding='same')(x) x = tf.keras.layers.MaxPooling2D((2,2))(x) x = tf.keras.layers.Flatten()(x) x = tf.keras.layers.Dense(128, activation='relu')(x) outputs = tf.keras.layers.Dense(num_classes, activation='softmax')(x) model = tf.keras.Model(inputs, outputs) return model cnn = cnn(input_shape = img_size + (3, ), num_classes=5) cnn.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy']) cnn.summary()
Model Summary
| Layer (type) | Output Shape | Param # |
|---|---|---|
| input_layer (InputLayer) | (None, 224, 224, 3) | 0 |
| conv2d (Conv2D) | (None, 224, 224, 32) | 896 |
| max_pooling2d (MaxPooling2D) | (None, 112, 112, 32) | 0 |
| conv2d_1 (Conv2D) | (None, 112, 112, 64) | 18,496 |
| max_pooling2d_1 (MaxPooling2D) | (None, 56, 56, 64) | 0 |
| conv2d_2 (Conv2D) | (None, 56, 56, 128) | 73,856 |
| max_pooling2d_2 (MaxPooling2D) | (None, 28, 28, 128) | 0 |
| flatten (Flatten) | (None, 100352) | 0 |
| dense (Dense) | (None, 128) | 12,845,184 |
| dense_1 (Dense) | (None, 5) | 645 |
Total params: 12,939,077 (49.36 MB)
Trainable params: 12,939,077 (49.36 MB)
Non-trainable params: 0 (0.00 B)
Model Evaluation
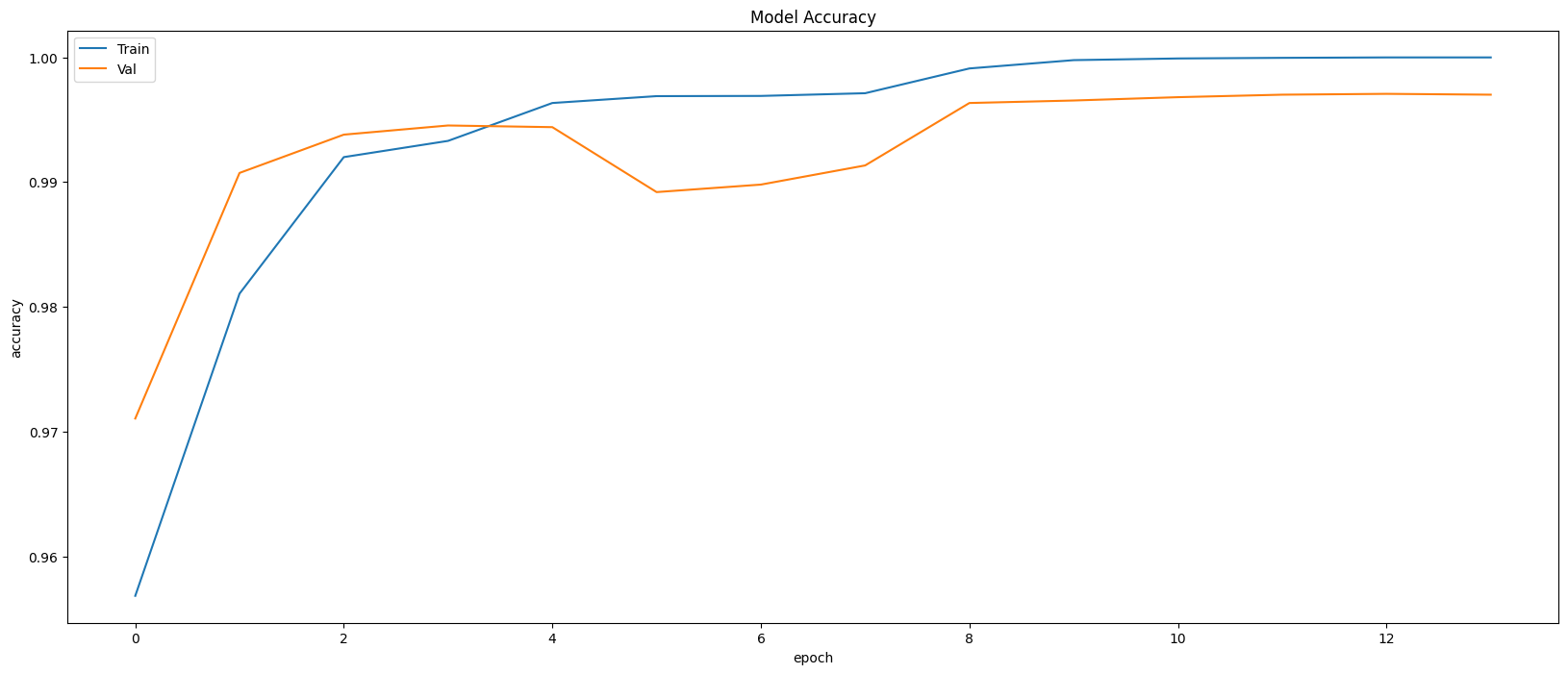
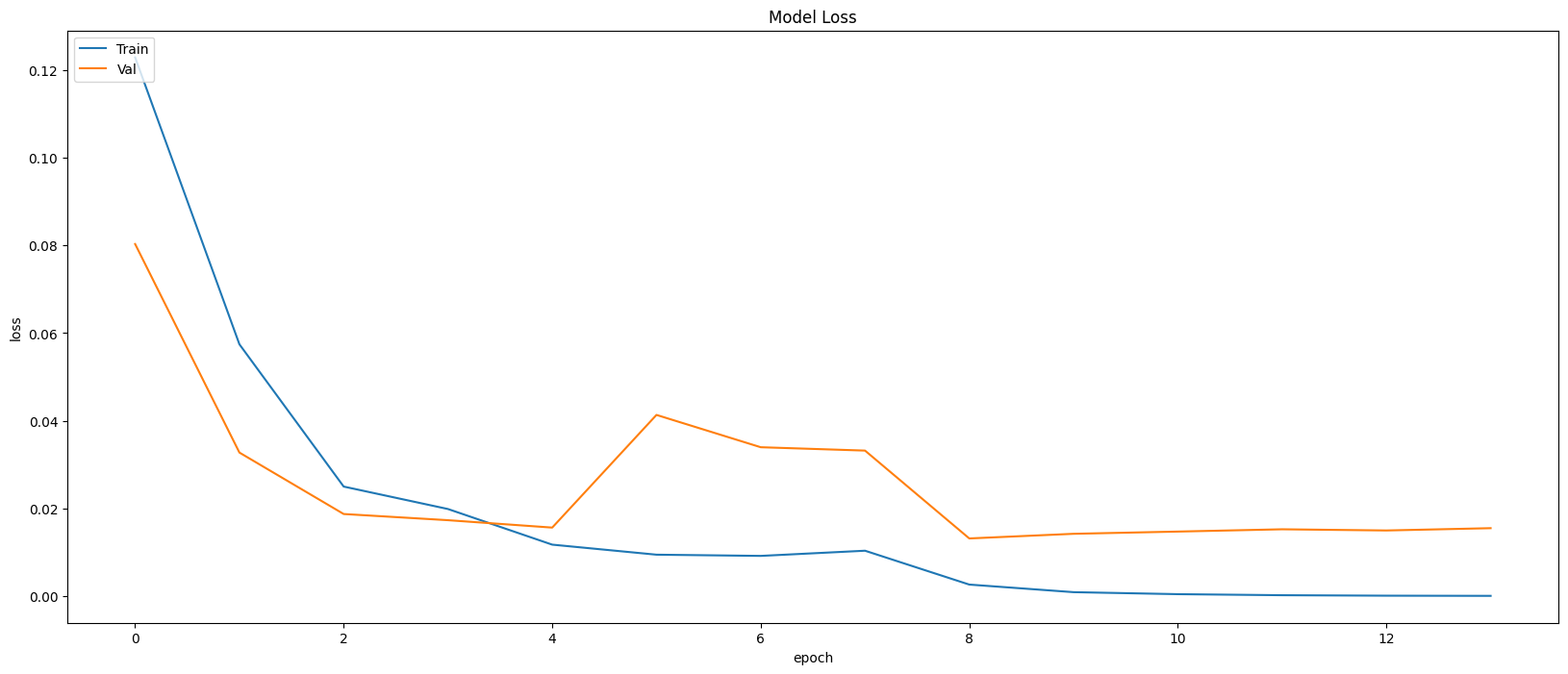
Restoring model weights from the end of the best epoch: 9.
Best score인 9번 째 epoch의 evaluation은 아래와 같다.
Train Accuracy: 0.9986
Train Loss: 0.0040
Validation Accuracy: 0.9963
Validation Loss: 0.0132
Feature Map 시각화



부분적으로 Filter를 거친 후 Feature Map이 검은색인 경우가 많다. 이는 계산에 큰 영향을 미치지 않을 것이라 판단되어 Filter의 개수를 줄여 개선을 경량화를 해보고자 한다.
(2) CNN 경량화
-
일반적인 CNN으로 Convolution → ReLu → MaxPooling 으로 2개 층으로 쌓아보았으며 필터의 갯수는 8 → 16 개를 사용하여 이전과 다르게
strides추가하여 Feature Map의 크기를 줄여보았다.def cnn_light(input_shape, num_classes): inputs = tf.keras.Input(shape=input_shape) x = tf.keras.layers.Conv2D(8, (3,3), activation='relu', strides = (2,2), padding='same')(inputs) x = tf.keras.layers.MaxPooling2D((2,2), strides = (2,2))(x) x = tf.keras.layers.Conv2D(16, (3,3), activation='relu', strides = (2,2), padding='same')(x) x = tf.keras.layers.MaxPooling2D((2,2), strides = (2,2))(x) x = tf.keras.layers.Flatten()(x) x = tf.keras.layers.Dense(16, activation='relu')(x) outputs = tf.keras.layers.Dense(num_classes, activation='softmax')(x) model = tf.keras.Model(inputs, outputs) return model
Model Summary
| Layer (type) | Output Shape | Param # |
|---|---|---|
| input_layer_1 (InputLayer) | (None, 224, 224, 3) | 0 |
| conv2d_3 (Conv2D) | (None, 112, 112, 8) | 224 |
| max_pooling2d_3 (MaxPooling2D) | (None, 56, 56, 8) | 0 |
| conv2d_4 (Conv2D) | (None, 28, 28, 16) | 1,168 |
| max_pooling2d_4 (MaxPooling2D) | (None, 14, 14, 16) | 0 |
| flatten_1 (Flatten) | (None, 3136) | 0 |
| dense_2 (Dense) | (None, 16) | 50,192 |
| dense_3 (Dense) | (None, 5) | 85 |
Total params: 51,669 (201.83 KB)
Trainable params: 51,669 (201.83 KB)
Non-trainable params: 0 (0.00 B)
Model Evaluation
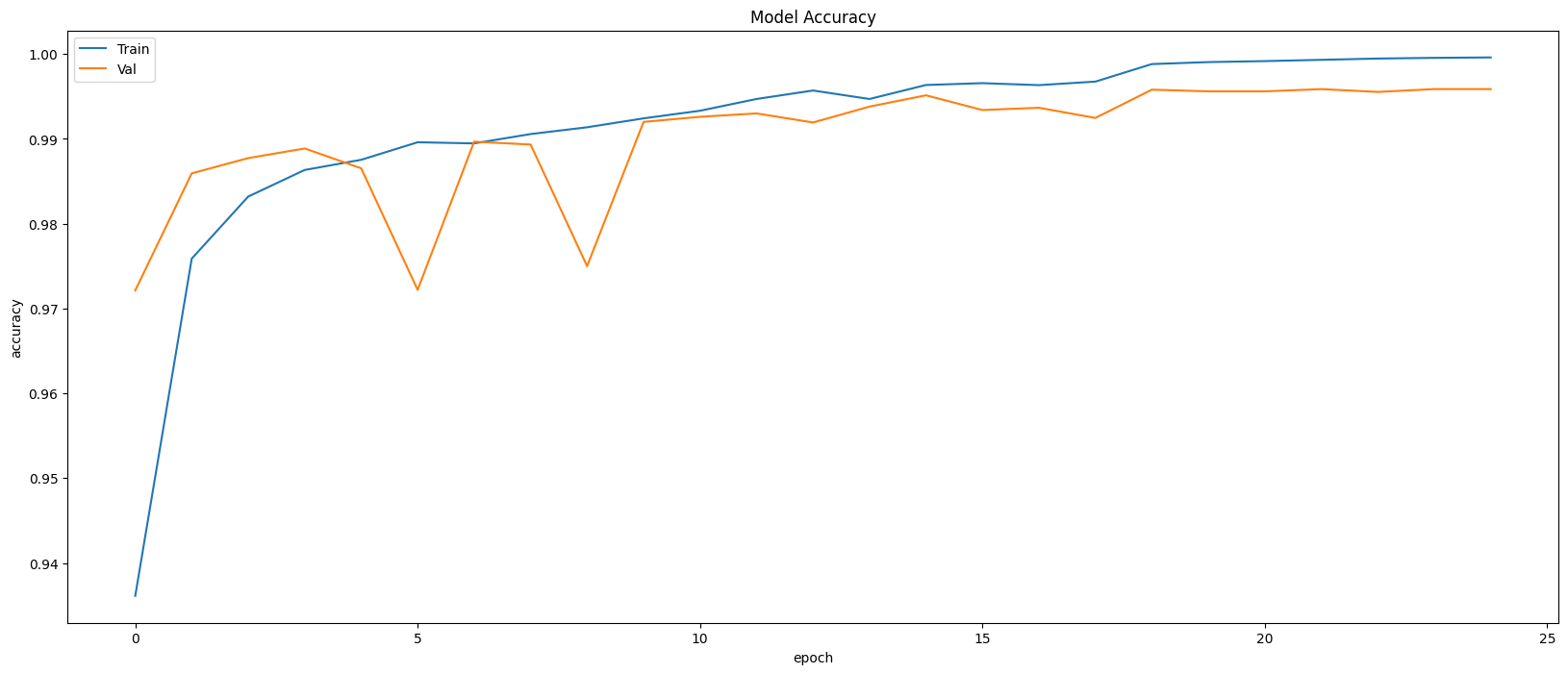
Restoring model weights from the end of the best epoch: 19.
Best score인 19번 째 epoch의 evaluation은 아래와 같다.
Train Accuracy: 0.9986
Train Loss: 0.0044
Validation Accuracy: 0.9970
Validation Loss: 0.0108
Feature Map 시각화


해당 모델은 3개의 층으로 쌓은 CNN에 비해 유효한 특징만 추출한 것을 확인할 수 있다.
모델 비교
| Model | Parameter | Validation Accuracy | Validation Loss |
|---|---|---|---|
| CNN | 12,939,077 | 0.9963 | 0.0132 |
| CNN 경량화 | 51,669 | 0.9970 | 0.0108 |
Parameter 수는 각 12,939,077와 51,669로 99.60(%) 경량화하였으며 Accuracy와 Loss를 보았을 때, 성능차이는 거의 없으며 오히려 경량화 모델이 소폭 높은 것을 확인할 수 있다.
(3) GoogLeNet
-
GoogLeNet의 구조는 아래 이미지와 같다.
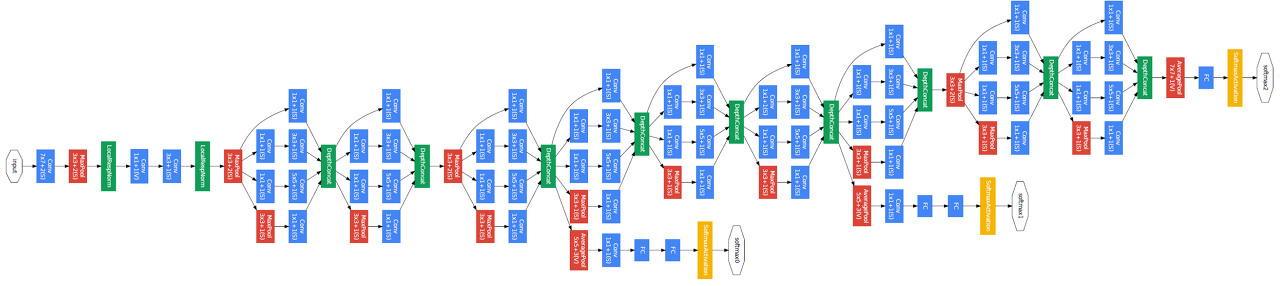
GoogLeNet은 총 27개의 Layer로 구성되어 있고 Stem Network는 신경망의 초기 부분으로 일반적인 CNN의 은닉 구조를 가진다. Inception Module은 GoogLeNet의 핵심적인 구조로 Layer를 하나의 Sub-Network구조로 구성하여 연산량을 줄이는 구조이다.
사전 학습된 Weight 없이 직접 해당 구조를 쌓아보았다.class InceptionModule(layers.Layer): def __init__(self, f1, f3_reduce, f3, f5_reduce, f5, pool_proj, **kwargs): super(InceptionModule, self).__init__(**kwargs) # 1x1 conv branch self.branch1 = layers.Conv2D(f1, (1,1), padding='same', activation='relu') # 1x1 -> 3x3 branch self.branch2 = models.Sequential([ layers.Conv2D(f3_reduce, (1,1), padding='same', activation='relu'), layers.Conv2D(f3, (3,3), padding='same', activation='relu') ]) # 1x1 -> 5x5 branch self.branch3 = models.Sequential([ layers.Conv2D(f5_reduce, (1,1), padding='same', activation='relu'), layers.Conv2D(f5, (5,5), padding='same', activation='relu') ]) # 3x3 max pooling -> 1x1 conv branch self.branch4 = models.Sequential([ layers.MaxPooling2D((3,3), strides=(1,1), padding='same'), layers.Conv2D(pool_proj, (1,1), padding='same', activation='relu') ]) def call(self, x): branch1 = self.branch1(x) branch2 = self.branch2(x) branch3 = self.branch3(x) branch4 = self.branch4(x) return tf.concat([branch1, branch2, branch3, branch4], axis=-1)def create_googlenet(input_shape, num_classes): inputs = layers.Input(shape=input_shape) # Stem network x = layers.Conv2D(64, (7,7), strides=(2,2), padding='same', activation='relu')(inputs) x = layers.MaxPooling2D((3,3), strides=(2,2), padding='same')(x) x = layers.Conv2D(64, (1,1), padding='same', activation='relu')(x) x = layers.Conv2D(192, (3,3), padding='same', activation='relu')(x) x = layers.MaxPooling2D((3,3), strides=(2,2), padding='same')(x) # Inception modules x = InceptionModule(64, 96, 128, 16, 32, 32)(x) x = InceptionModule(128, 128, 192, 32, 96, 64)(x) x = layers.MaxPooling2D((3,3), strides=(2,2), padding='same')(x) x = InceptionModule(192, 96, 208, 16, 48, 64)(x) x = InceptionModule(160, 112, 224, 24, 64, 64)(x) x = InceptionModule(128, 128, 256, 24, 64, 64)(x) x = InceptionModule(112, 144, 288, 32, 64, 64)(x) x = InceptionModule(256, 160, 320, 32, 128, 128)(x) x = layers.MaxPooling2D((3,3), strides=(2,2), padding='same')(x) x = InceptionModule(256, 160, 320, 32, 128, 128)(x) x = InceptionModule(384, 192, 384, 48, 128, 128)(x) # 최종 분류기 x = layers.GlobalAveragePooling2D()(x) x = layers.Dropout(0.4)(x) outputs = layers.Dense(num_classes, activation='softmax')(x) model = models.Model(inputs, outputs) return model googlenet = create_googlenet(input_shape=img_size + (3,), num_classes=5) googlenet.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy']) googlenet.summary()
Model Summary
| Layer (type) | Output Shape | Param # |
|---|---|---|
| input_layer_86 (InputLayer) | (None, 224, 224, 3) | 0 |
| conv2d_176 (Conv2D) | (None, 112, 112, 64) | 9,472 |
| max_pooling2d_44 (MaxPooling2D) | (None, 56, 56, 64) | 0 |
| conv2d_177 (Conv2D) | (None, 56, 56, 64) | 4,160 |
| conv2d_178 (Conv2D) | (None, 56, 56, 192) | 110,784 |
| max_pooling2d_45 (MaxPooling2D) | (None, 28, 28, 192) | 0 |
| inception_module_27 (InceptionModule) | (None, 28, 28, 256) | 163,696 |
| inception_module_28 (InceptionModule) | (None, 28, 28, 480) | 388,736 |
| max_pooling2d_48 (MaxPooling2D) | (None, 14, 14, 480) | 0 |
| inception_module_29 (InceptionModule) | (None, 14, 14, 512) | 376,176 |
| inception_module_30 (InceptionModule) | (None, 14, 14, 512) | 449,160 |
| inception_module_31 (InceptionModule) | (None, 14, 14, 512) | 510,104 |
| inception_module_32 (InceptionModule) | (None, 14, 14, 528) | 605,376 |
| inception_module_33 (InceptionModule) | (None, 14, 14, 832) | 868,352 |
| max_pooling2d_54 (MaxPooling2D) | (None, 7, 7, 832) | 0 |
| inception_module_34 (InceptionModule) | (None, 7, 7, 832) | 1,043,456 |
| inception_module_35 (InceptionModule) | (None, 7, 7, 1024) | 1,444,080 |
| global_average_pooling2d_3 (GlobalAveragePooling2D) | (None, 1024) | 0 |
| dropout_3 (Dropout) | (None, 1024) | 0 |
| dense_7 (Dense) | (None, 5) | 5,125 |
Total params: 5,978,677 (22.81 MB)
Trainable params: 5,978,677 (22.81 MB)
Non-trainable params: 0 (0.00 B)
Model Evaluation
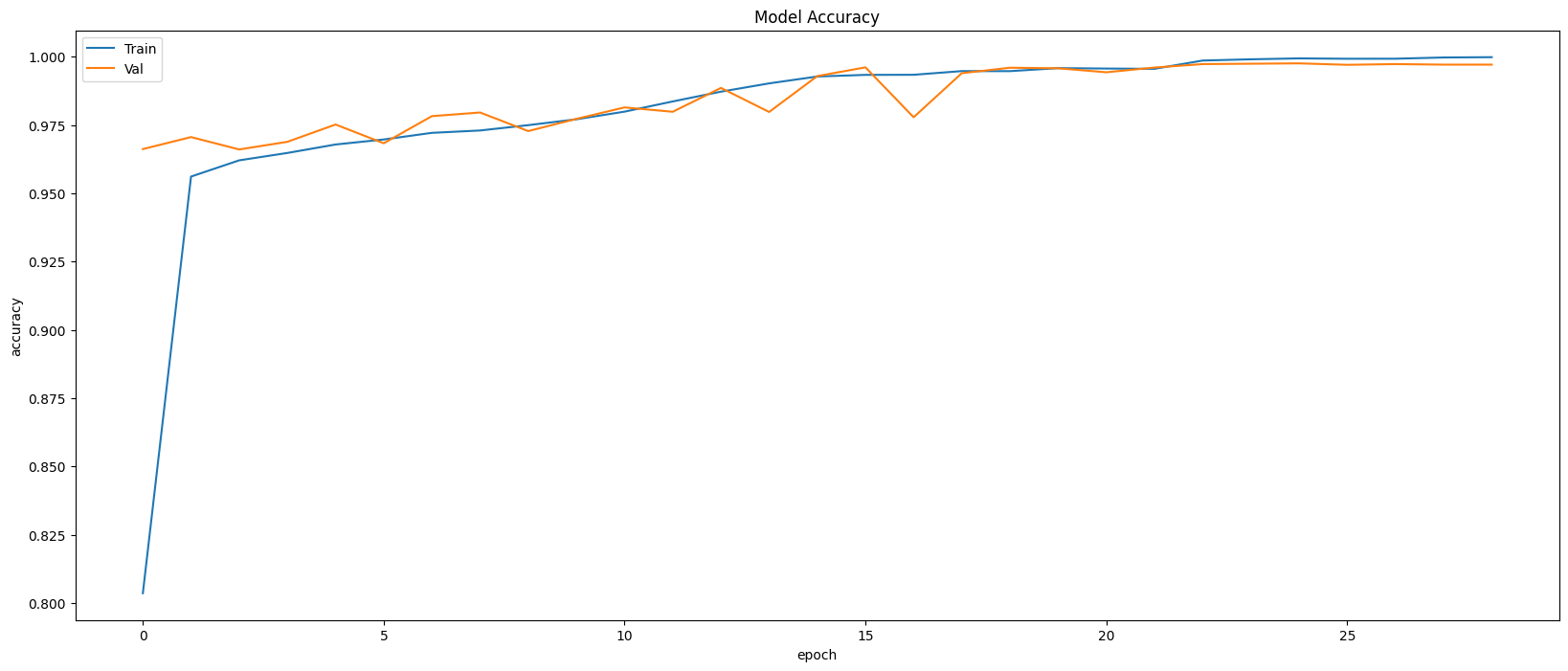
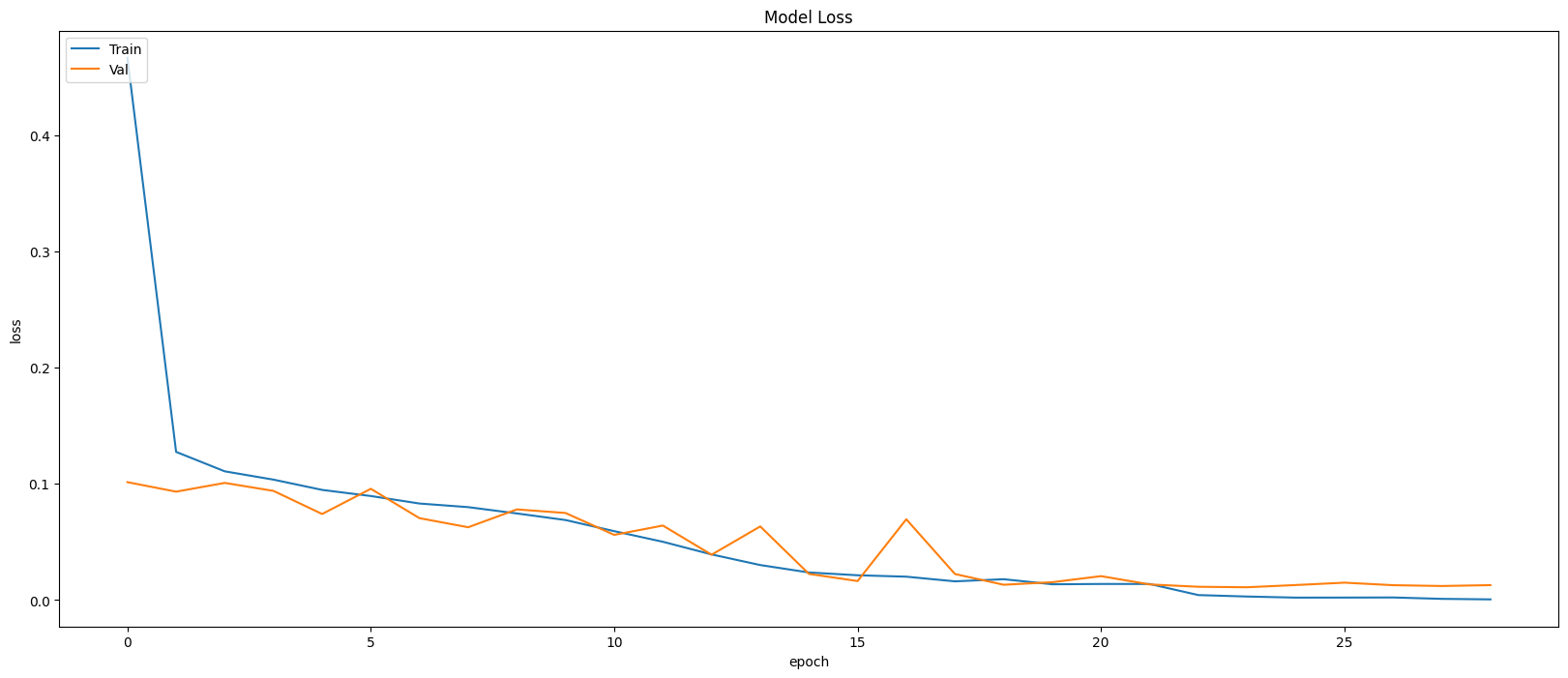
Restoring model weights from the end of the best epoch: 24.
Best score인 24번 째 epoch의 evaluation은 아래와 같다.
Train Accuracy: 0.9988
Train Loss: 0.0039
Validation Accruacy: 0.9975
Validation Loss: 0.0111
Feature Map 시각화
Feature Map은 Stem Network만 시각화해보았다.



(4) GoogLeNet 경량화
-
해당 모델은 Stem Network의 Filter의 개수를 줄이고 각 Inception Module의 Filter 개수를 줄여주었다. 또한 2단계의 Inception Module 하나를 삭제하므로써 연산량을 줄였다. Inception Module의 내부 구조는 GoogLeNet의 특징이므로 건드리지 않았다.
# Inception Module은 GoogLeNet과 같으므로 생략 def create_googlenet_light(input_shape, num_classes): inputs = layers.Input(shape=input_shape) # Stem network x = layers.Conv2D(16, (7,7), strides=(2,2), padding='same', activation='relu')(inputs) x = layers.MaxPooling2D((3,3), strides=(2,2), padding='same')(x) x = layers.Conv2D(16, (1,1), padding='same', activation='relu')(x) x = layers.Conv2D(64, (3,3), padding='same', activation='relu')(x) x = layers.MaxPooling2D((3,3), strides=(2,2), padding='same')(x) # Inception modules x = InceptionModule(16, 16, 24, 4, 8, 8)(x) x = InceptionModule(24, 24, 32, 4, 8, 8)(x) x = layers.MaxPooling2D((3,3), strides=(2,2), padding='same')(x) x = InceptionModule(32, 32, 48, 8, 16, 16)(x) x = InceptionModule(48, 48, 64, 8, 16, 16)(x) x = InceptionModule(64, 64, 96, 12, 24, 24)(x) x = InceptionModule(96, 64, 96, 12, 24, 24)(x) x = layers.MaxPooling2D((3,3), strides=(2,2), padding='same')(x) x = InceptionModule(96, 64, 96, 12, 24, 24)(x) x = InceptionModule(96, 96, 128, 16, 32, 32)(x) # 최종 분류기 x = layers.GlobalAveragePooling2D()(x) x = layers.Dropout(0.4)(x) outputs = layers.Dense(num_classes, activation='softmax')(x) model = models.Model(inputs, outputs) return model googlenet_light = create_googlenet_light(input_shape=img_size + (3,), num_classes=5) googlenet_light.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy']) googlenet_light.summary()
Model Summary
| Layer (type) | Output Shape | Param # |
|---|---|---|
| input_layer (InputLayer) | (None, 224, 224, 3) | 0 |
| conv2d (Conv2D) | (None, 112, 112, 16) | 2,368 |
| max_pooling2d (MaxPooling2D) | (None, 56, 56, 16) | 0 |
| conv2d_1 (Conv2D) | (None, 56, 56, 16) | 272 |
| conv2d_2 (Conv2D) | (None, 56, 56, 64) | 9,280 |
| max_pooling2d_1 (MaxPooling2D) | (None, 28, 28, 64) | 0 |
| inception_module (InceptionModule) | (None, 28, 28, 56) | 7,148 |
| inception_module_1 (InceptionModule) | (None, 28, 28, 72) | 11,172 |
| max_pooling2d_4 (MaxPooling2D) | (None, 14, 14, 72) | 0 |
| inception_module_2 (InceptionModule) | (None, 14, 14, 112) | 23,512 |
| inception_module_3 (InceptionModule) | (None, 14, 14, 144) | 44,488 |
| inception_module_4 (InceptionModule) | (None, 14, 14, 208) | 86,396 |
| inception_module_5 (InceptionModule) | (None, 14, 14, 240) | 103,580 |
| max_pooling2d_9 (MaxPooling2D) | (None, 7, 7, 240) | 0 |
| inception_module_6 (InceptionModule) | (None, 7, 7, 240) | 109,852 |
| inception_module_7 (InceptionModule) | (None, 7, 7, 288) | 181,392 |
| global_average_pooling2d (GlobalAveragePooling2D) | (None, 288) | 0 |
| dropout (Dropout) | (None, 288) | 0 |
| dense (Dense) | (None, 5) | 1,445 |
Total params: 580,905 (2.22 MB)
Trainable params: 580,905 (2.22 MB)
Non-trainable params: 0 (0.00 B)
Model Evaluation
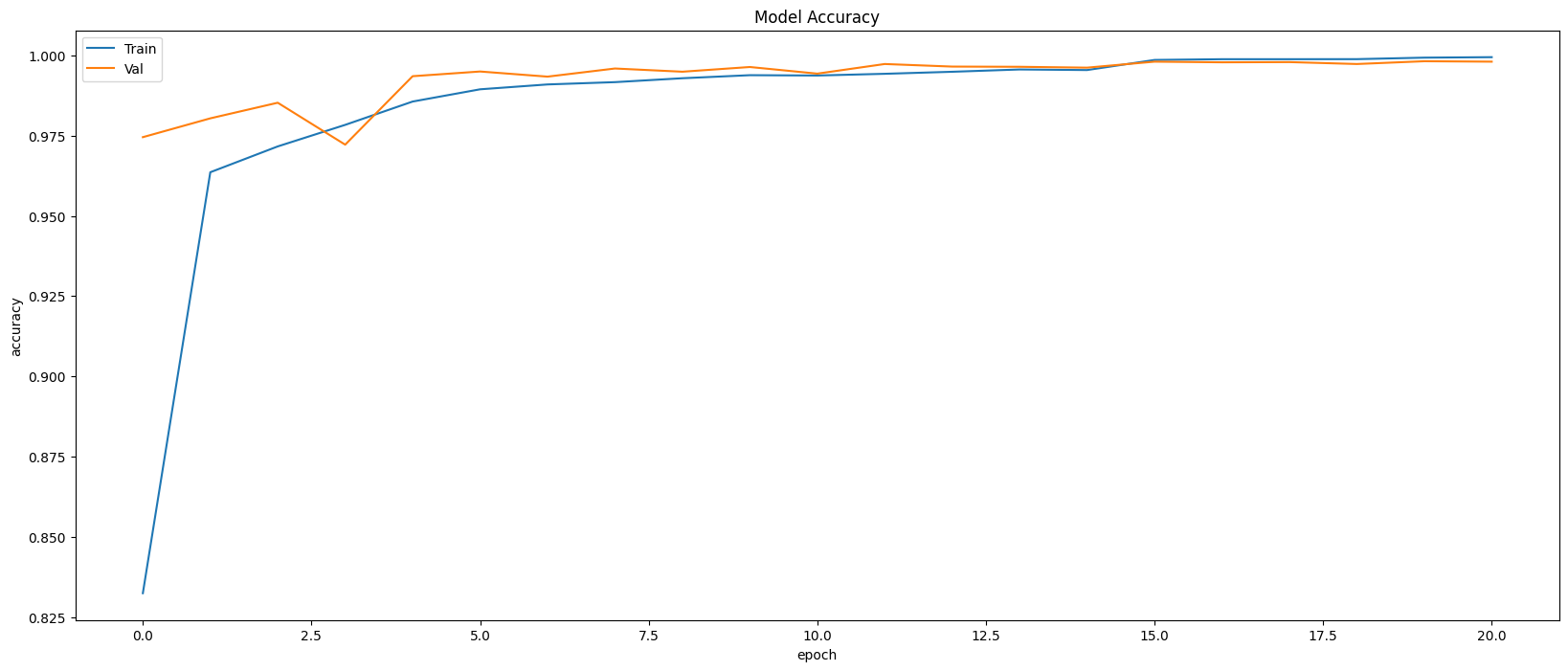
Restoring model weights from the end of the best epoch: 16.
Best score인 16번 째 epoch의 evaluation은 아래와 같다.
Train Accuracy: 0.9983
Train Loss: 0.0071
Validation Accuracy: 0.9981
Validation Loss: 0.0070
Feature Map 시각화
Feature Map은 위와 마찬가지로 Stem Network만 시각화해보았다.



모델 비교
| Model | Parameter | Validation Accuracy | Validation Loss |
|---|---|---|---|
| GoogLeNet | 5,978,677 | 0.9975 | 0.0111 |
| GoogLeNet 경량화 | 580,905 | 0.9981 | 0.0070 |
Parameter 수는 각 5,978,677와 580,905로 90.28(%) 경량화하였으며 Accuracy와 Loss를 보았을 때, 성능차이는 거의 없으며 오히려 경량화 모델이 소폭 높은 것을 확인할 수 있다.
(5) VGG16
-
VGG16은 구조가 매우 간단하며 아래와 같은 구조를 가진다.
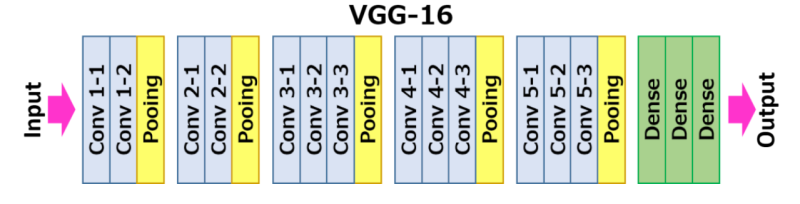
VGG16은 모든 Convolution Layer에 3x3 필터를 적용하는 것이 큰 특징이다. 구조가 간단하고 이해가 쉽고 변형을 시켜가면서 테스트 하기 용이해 자주 사용되는 모델이다. 해당 모델은 Feature Map 크기는 동일하지만 학습해야할 파라미터 수를 줄였다는 특징이 있다.
해당 모델은 ‘Rice Image Project 예시‘를 참고하여 Imagenet으로 사전학습 된 모델에서 미세조정 하였다. 또한 이미지 증강은 사용하지 않았고 ‘Rice Image Dataset’을 그대로 사용하였다.input_tensor = Input(shape=img_size + (3,)) # VGG16 base model base_model = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor) # 필요한 레이어만 학습되도록 설정 for layer in base_model.layers[:-4]: layer.trainable = False # 커스텀 분류기 추가 x = base_model.output x = GlobalAveragePooling2D()(x) x = Dense(512, activation='relu')(x) x = Dropout(0.3)(x) output_tensor = Dense(5, activation='softmax')(x) vgg16 = Model(inputs=input_tensor, outputs=output_tensor) vgg16.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy']) vgg16.summary()
Model Summary
| Layer (type) | Output Shape | Param # |
|---|---|---|
| input_layer_171 (InputLayer) | (None, 224, 224, 3) | 0 |
| block1_conv1 (Conv2D) | (None, 224, 224, 64) | 1,792 |
| block1_conv2 (Conv2D) | (None, 224, 224, 64) | 36,928 |
| block1_pool (MaxPooling2D) | (None, 112, 112, 64) | 0 |
| block2_conv1 (Conv2D) | (None, 112, 112, 128) | 73,856 |
| block2_conv2 (Conv2D) | (None, 112, 112, 128) | 147,584 |
| block2_pool (MaxPooling2D) | (None, 56, 56, 128) | 0 |
| block3_conv1 (Conv2D) | (None, 56, 56, 256) | 295,168 |
| block3_conv2 (Conv2D) | (None, 56, 56, 256) | 590,080 |
| block3_conv3 (Conv2D) | (None, 56, 56, 256) | 590,080 |
| block3_pool (MaxPooling2D) | (None, 28, 28, 256) | 0 |
| block4_conv1 (Conv2D) | (None, 28, 28, 512) | 1,180,160 |
| block4_conv2 (Conv2D) | (None, 28, 28, 512) | 2,359,808 |
| block4_conv3 (Conv2D) | (None, 28, 28, 512) | 2,359,808 |
| block4_pool (MaxPooling2D) | (None, 14, 14, 512) | 0 |
| block5_conv1 (Conv2D) | (None, 14, 14, 512) | 2,359,808 |
| block5_conv2 (Conv2D) | (None, 14, 14, 512) | 2,359,808 |
| block5_conv3 (Conv2D) | (None, 14, 14, 512) | 2,359,808 |
| block5_pool (MaxPooling2D) | (None, 7, 7, 512) | 0 |
| global_average_pooling2d_7 (GlobalAveragePooling2D) | (None, 512) | 0 |
| dense_14 (Dense) | (None, 512) | 262,656 |
| dropout_7 (Dropout) | (None, 512) | 0 |
| dense_15 (Dense) | (None, 5) | 2,565 |
Total params: 14,979,909 (57.14 MB)
Trainable params: 7,344,645 (28.02 MB)
Non-trainable params: 7,635,264 (29.13 MB)
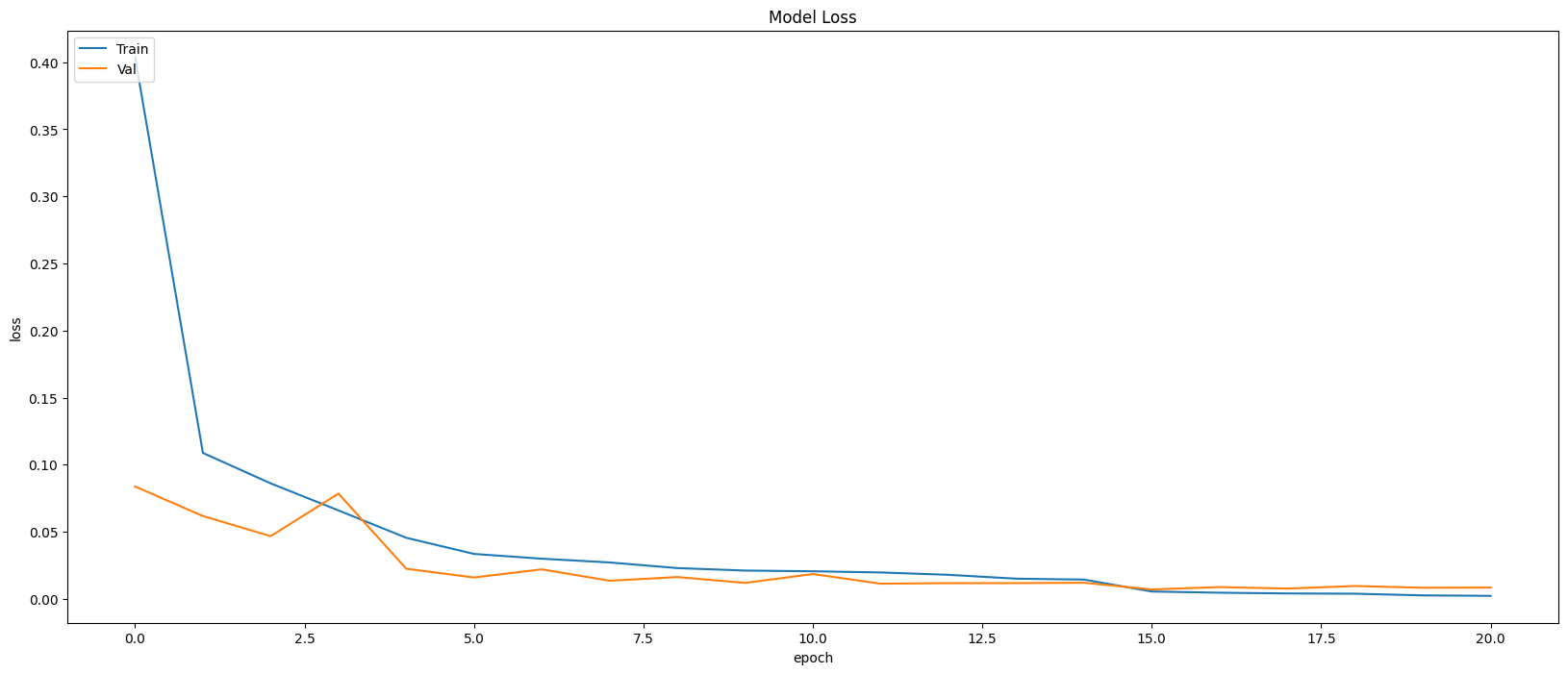
Model Evaluation
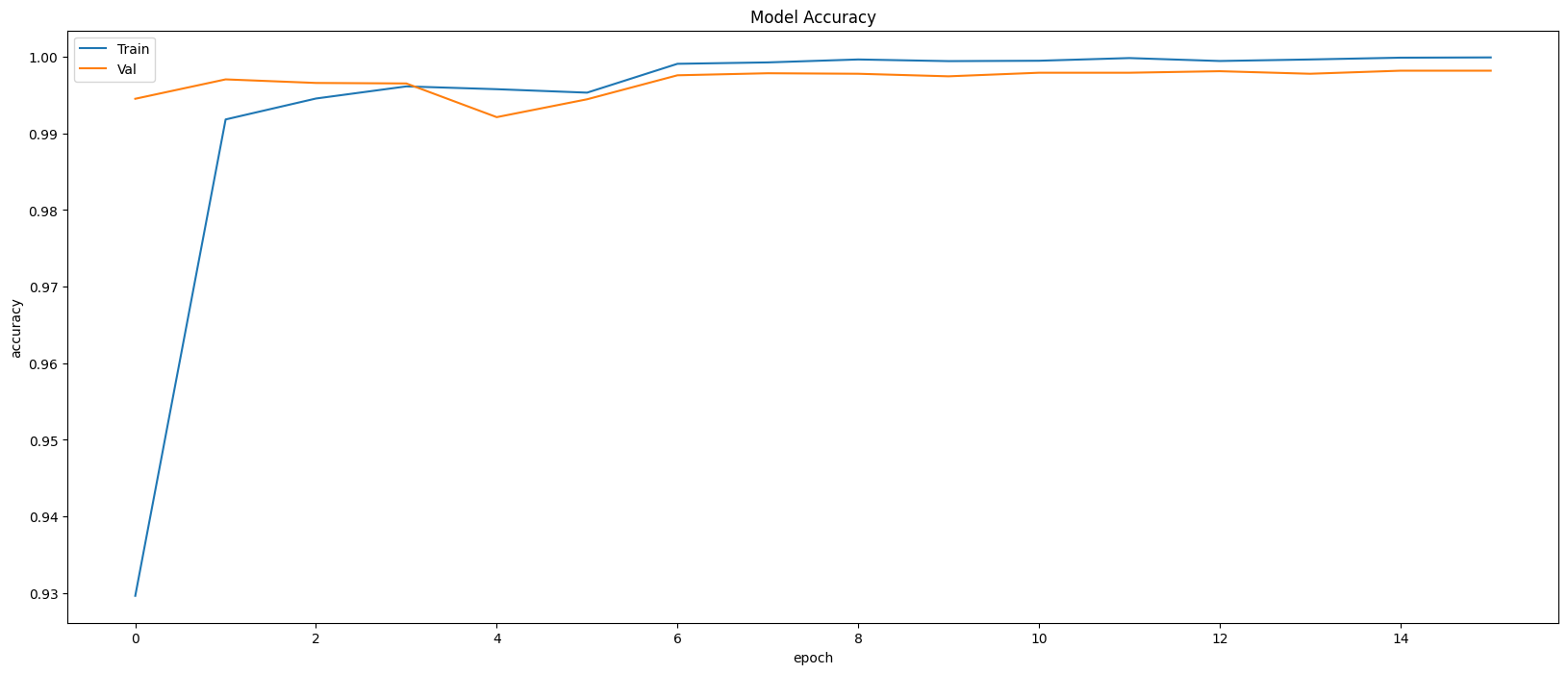
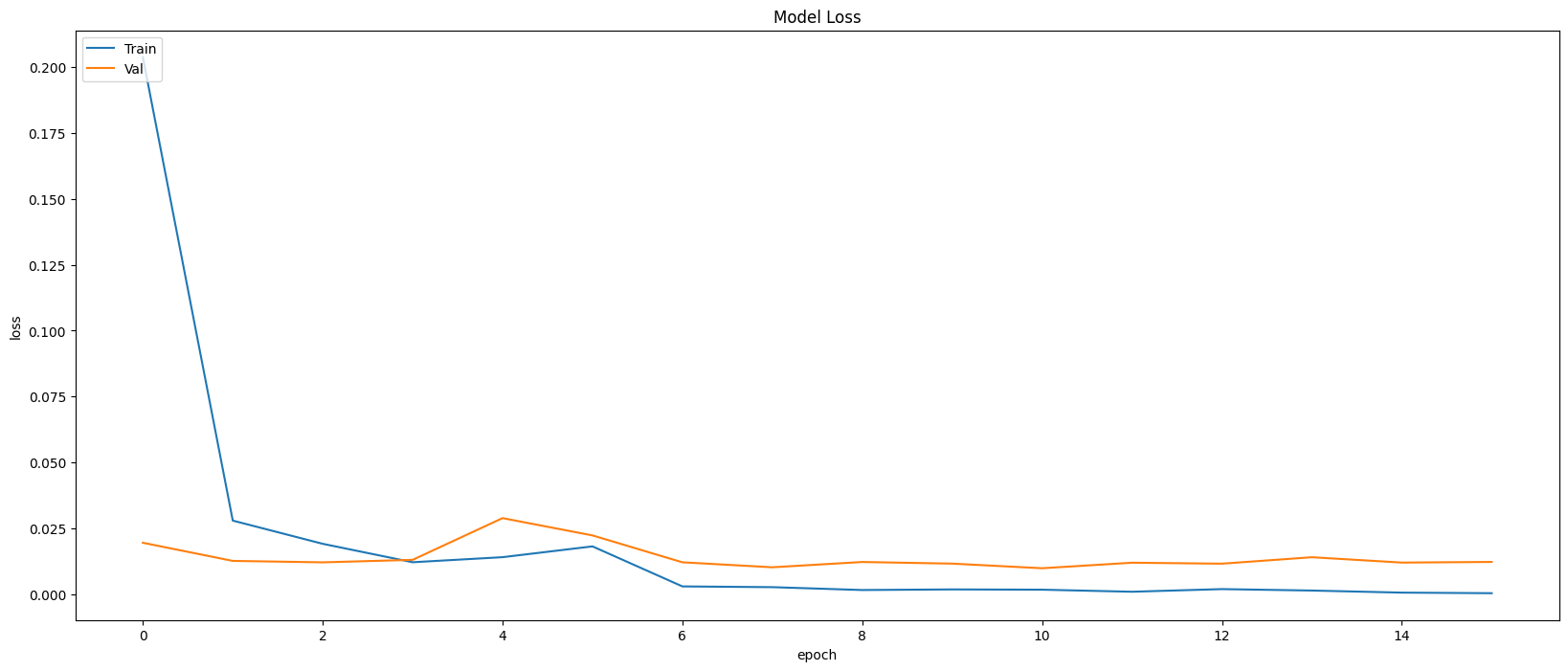
Restoring model weights from the end of the best epoch: 11.
Best score인 11번 째 epoch의 evaluation은 아래와 같다.
Train Accuracy: 0.9994
Train Loss: 0.0024
Validation Accuracy: 0.9979
Validation Loss: 0.0099
Feature Map 시각화




(6) VGG16 경량화
-
사전학습 되어있는 Filter를 그대로 사용하고 block_5는 특징 추출이 되지 않은 형태로 보이므로 삭제하여 경량화였다.
x = vgg16.get_layer('block4_pool').output # 분류기 추가 x = GlobalAveragePooling2D()(x) x = Dense(512, activation='relu')(x) x = Dropout(0.3)(x) output_tensor = Dense(5, activation='softmax')(x) # 전체 모델 정의 vgg_light = Model(inputs=input_tensor, outputs=output_tensor) # 필요한 레이어만 학습되도록 설정 for layer in vgg16.layers: layer.trainable = False vgg_light.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy']) vgg_light.summary()
Model Summary
| Layer (type) | Output Shape | Param # |
|---|---|---|
| input_layer (InputLayer) | (None, 224, 224, 3) | 0 |
| block1_conv1 (Conv2D) | (None, 224, 224, 64) | 1,792 |
| block1_conv2 (Conv2D) | (None, 224, 224, 64) | 36,928 |
| block1_pool (MaxPooling2D) | (None, 112, 112, 64) | 0 |
| block2_conv1 (Conv2D) | (None, 112, 112, 128) | 73,856 |
| block2_conv2 (Conv2D) | (None, 112, 112, 128) | 147,584 |
| block2_pool (MaxPooling2D) | (None, 56, 56, 128) | 0 |
| block3_conv1 (Conv2D) | (None, 56, 56, 256) | 295,168 |
| block3_conv2 (Conv2D) | (None, 56, 56, 256) | 590,080 |
| block3_conv3 (Conv2D) | (None, 56, 56, 256) | 590,080 |
| block3_pool (MaxPooling2D) | (None, 28, 28, 256) | 0 |
| block4_conv1 (Conv2D) | (None, 28, 28, 512) | 1,180,160 |
| block4_conv2 (Conv2D) | (None, 28, 28, 512) | 2,359,808 |
| block4_conv3 (Conv2D) | (None, 28, 28, 512) | 2,359,808 |
| block4_pool (MaxPooling2D) | (None, 14, 14, 512) | 0 |
| global_average_pooling2d_3 (GlobalAveragePooling2D) | (None, 512) | 0 |
| dense_6 (Dense) | (None, 512) | 262,656 |
| dropout_3 (Dropout) | (None, 512) | 0 |
| dense_7 (Dense) | (None, 5) | 2,565 |
Total params: 7,900,485 (30.14 MB)
Trainable params: 265,221 (1.01 MB)
Non-trainable params: 7,635,264 (29.13 MB)
Model Evaluation
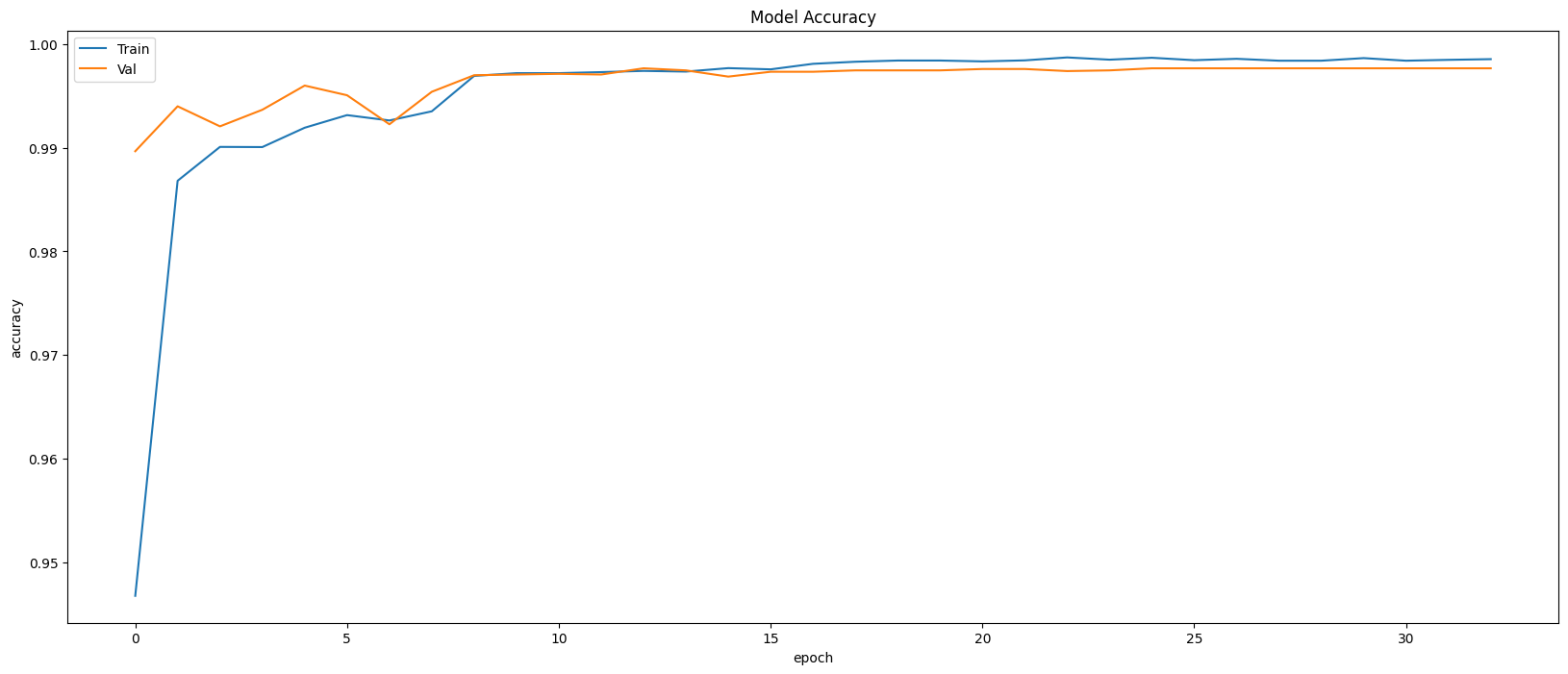
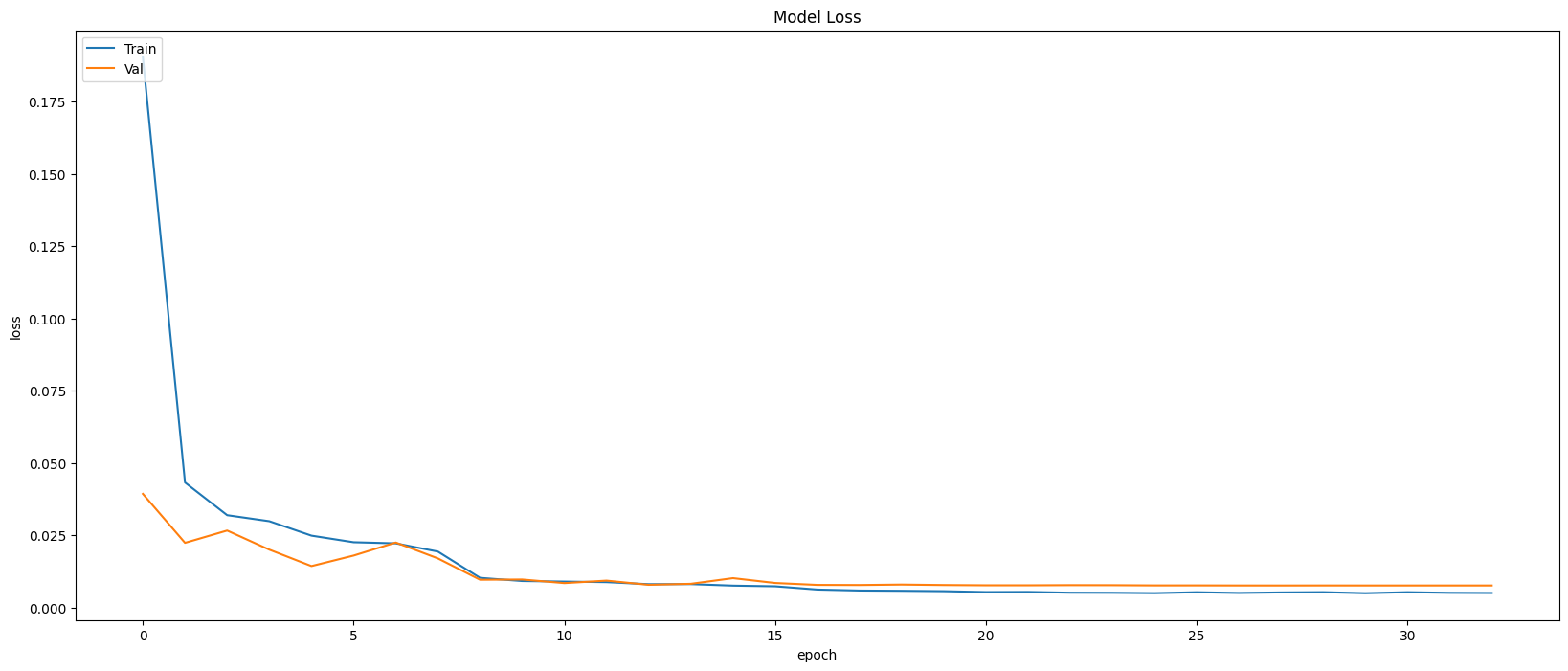
Restoring model weights from the end of the best epoch: 28.
Best score인 28번 째 epoch의 evaluation은 아래와 같다.
Train Accuracy: 0.9982
Train Loss: 0.0061
Validation Accuracy: 0.9977
Validation Loss: 0.0077
Feature Map 시각화
사전 학습된 모델 그대로 가져왔으므로 Filter를 통과한 Feature Map은 동일하다.
(7) VGG Custom
-
VGG16 모델과 경량화 모델은 모두 Imagenet으로 사전학습된 모델이다. 해당 모델은 VGG16의 구조를 따라가되 직접 학습한 모델이며 총 3개의 block으로 이루어져있다.
def vgg_custom(input_shape=(224, 224, 3), num_classes=5): inputs = layers.Input(shape=input_shape) # Block 1 - 16 filters x = layers.Conv2D(16, (3, 3), activation='relu', padding='same')(inputs) x = layers.Conv2D(16, (3, 3), activation='relu', padding='same')(x) x = layers.MaxPooling2D((2, 2))(x) # Block 2 - 32 filters x = layers.Conv2D(32, (3, 3), activation='relu', padding='same')(x) x = layers.Conv2D(32, (3, 3), activation='relu', padding='same')(x) x = layers.MaxPooling2D((2, 2))(x) # Block 3 - 64 filters x = layers.Conv2D(64, (3, 3), activation='relu', padding='same')(x) x = layers.Conv2D(64, (3, 3), activation='relu', padding='same')(x) x = layers.Conv2D(64, (3, 3), activation='relu', padding='same')(x) x = layers.MaxPooling2D((2, 2))(x) x = layers.GlobalAveragePooling2D()(x) x = layers.Dense(512, activation='relu')(x) x = layers.Dropout(0.5)(x) outputs = layers.Dense(num_classes, activation='softmax')(x) model = models.Model(inputs, outputs) return model vgg_custom = vgg_custom(input_shape=img_size + (3,), num_classes=5) vgg_custom.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy']) vgg_custom.summary()
Model Summary
| Layer (type) | Output Shape | Param # |
|---|---|---|
| input_layer_1 (InputLayer) | (None, 224, 224, 3) | 0 |
| conv2d (Conv2D) | (None, 224, 224, 16) | 448 |
| conv2d_1 (Conv2D) | (None, 224, 224, 16) | 2,320 |
| max_pooling2d (MaxPooling2D) | (None, 112, 112, 16) | 0 |
| conv2d_2 (Conv2D) | (None, 112, 112, 32) | 4,640 |
| conv2d_3 (Conv2D) | (None, 112, 112, 32) | 9,248 |
| max_pooling2d_1 (MaxPooling2D) | (None, 56, 56, 32) | 0 |
| conv2d_4 (Conv2D) | (None, 56, 56, 64) | 18,496 |
| conv2d_5 (Conv2D) | (None, 56, 56, 64) | 36,928 |
| conv2d_6 (Conv2D) | (None, 56, 56, 64) | 36,928 |
| max_pooling2d_2 (MaxPooling2D) | (None, 28, 28, 64) | 0 |
| global_average_pooling2d_4 (GlobalAveragePooling2D) | (None, 64) | 0 |
| dense_8 (Dense) | (None, 512) | 33,280 |
| dropout_4 (Dropout) | (None, 512) | 0 |
| dense_9 (Dense) | (None, 5) | 2,565 |
Total params: 144,853 (565.83 KB)
Trainable params: 144,853 (565.83 KB)
Non-trainable params: 0 (0.00 B)
Model Evaluation
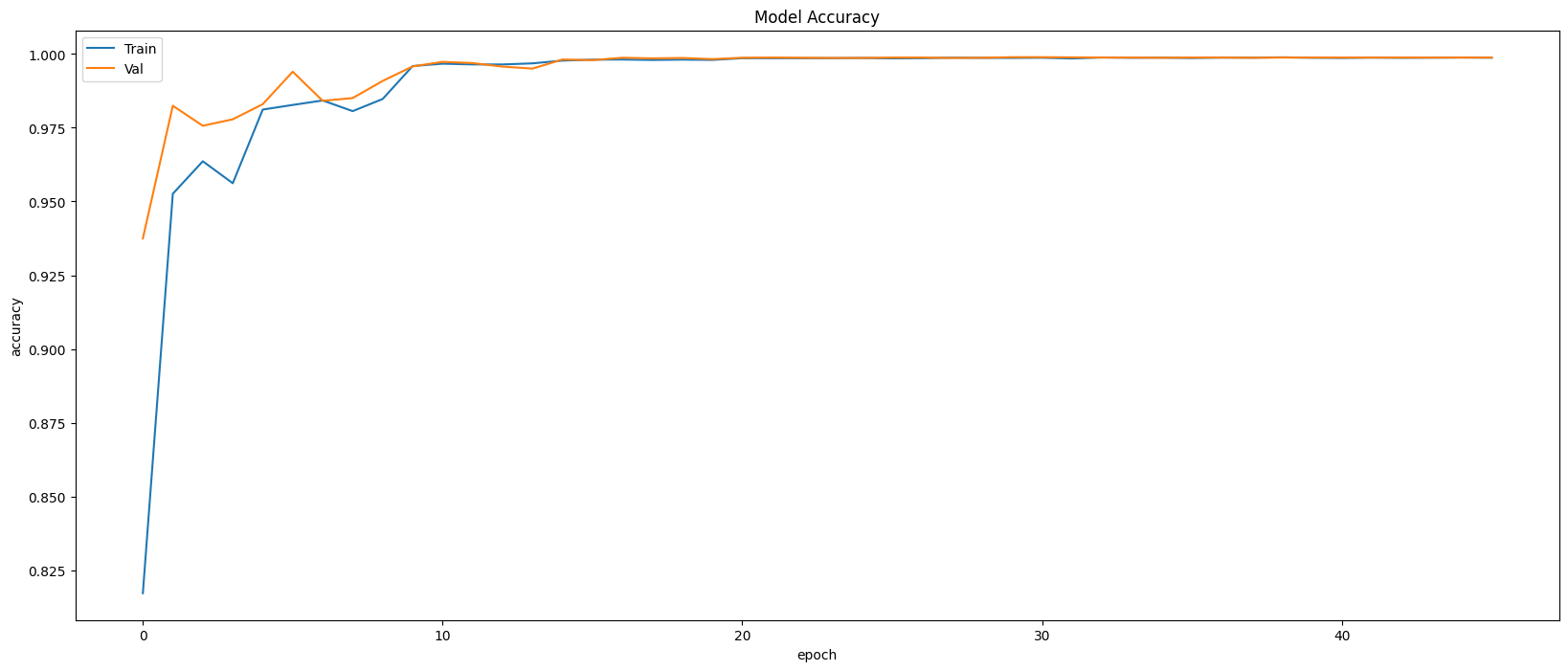
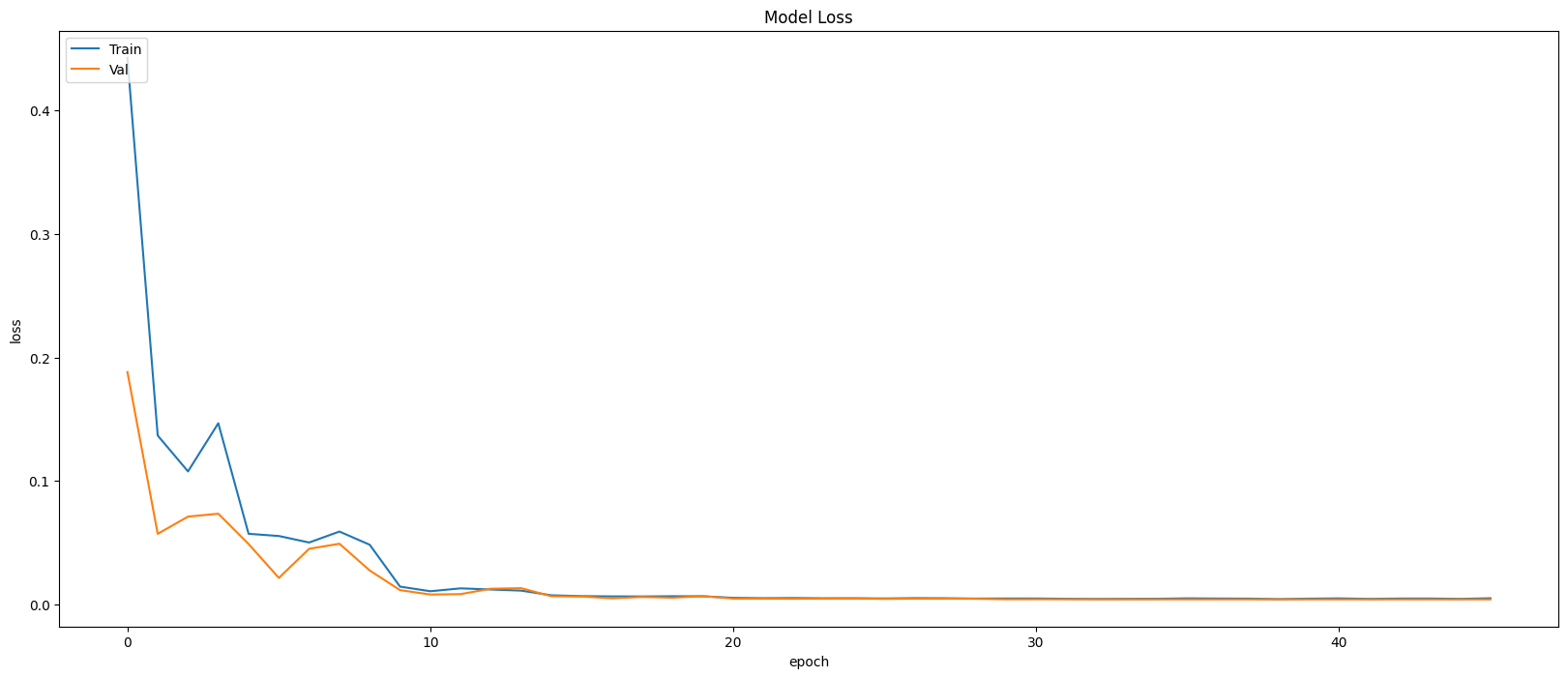
Restoring model weights from the end of the best epoch: 41.
Best score인 41번 째 epoch의 evaluation은 아래와 같다.
Train Accuracy: 0.9986
Train Loss: 0.0051
Validation Accuracy: 0.9988
Validation Loss: 0.0042
Feature Map 시각화



각 블럭의 1층 Feature Map만 시각화하였다.
모델 비교
| Model | Parameter | Validation Accuracy | Validation Loss |
|---|---|---|---|
| VGG16 | 14,979,909 | 0.9979 | 0.0099 |
| VGG 경량화 | 7,900,485 | 0.9977 | 0.0077 |
| VGG Custom | 144,853 | 0.9988 | 0.0042 |
Parameter 수는 각 VGG16 모델 대비 99.03(%) 경량화하였으며 VGG 경량화 모델 대비 98.16(%)경량화 되었다. Accuracy와 Loss를 보았을 때, 성능차이는 VGG16 Custom 모델이 제일 높은 성능을 보여준다.
4. 모델별 일반화 성능비교
각 학습한 모델들을 .h5형태로 저장하였으며 일반화 성능과 추론 속도를 보기 위해 기존의 데이터를 가공하여 사용해보았다.
raw_test_ds = tf.keras.preprocessing.image_dataset_from_directory(
test_fpath,
image_size=img_size,
batch_size=batch_size,
shuffle=False,
label_mode='categorical'
)
class_names = raw_test_ds.class_names
data_augmentation = tf.keras.Sequential([
layers.RandomFlip("horizontal"), # 수평 뒤집기
layers.RandomRotation(0.1), # ±10% 회전
layers.RandomZoom(0.1), # ±10% 확대/축소
layers.RandomTranslation(0.1, 0.1), # ±10% 가로/세로 이동
layers.RandomContrast(0.1) # 명암 변화
])
normalization_layer = tf.keras.layers.Rescaling(1./255)
test_ds = raw_test_ds.map(lambda x, y: (normalization_layer(data_augmentation(x)), y))
AUTOTUNE = tf.data.AUTOTUNE
test_ds = test_ds.prefetch(buffer_size=AUTOTUNE)
추론 속도는 정확한 값으로 측정하기 위해서 FLOPs로 대체하였다. FLOPs란 FLoating point Operations의 약자로 부동소수점 연산을 의미하며 주로 모델의 계산 복잡성을 측정하는데 사용된다. Device Performance는 대개 FLOPS(FLoating point Operations Per Second)로 측정하고 있으며 추론 시간은 Device의 성능이 높을수록 계산해야하는 FLOPs가 낮을수록 추론시간은 짧아진다. CNN 계열 모델의 이론적 추론시간은 아래와 같다.
\(Inference\,Time = \frac{\sum_{l=1}^{L}FLOPs_l}{Device\,Performance\,(FLOPs/sec)}\)
일반적으로 Convolution Lyaer의 FLOPs의 계산은 아래와 같이 계산된다.
$C_{in}$: 입력 채널 수
$K$: 커널크기
$H_{out}, W_{out}$: Feature Map의 Height, Width
$C_{out}$: 출력 채널 수
\(FLOPs_{conv} = 2 \times C_{in} \times K^2 \times H_{out} \times W_{out} \times C_{out}\)
여기서 Layer를 제거하거나 Filter의 개수를 줄이게 되면 이후 Layer에서의 $C_{in}$값 또한 감소한다. 따라서 연산량이 전반적으로 줄어들게 되며 상당한 계산량 절감 효과를 기대할 수 있다.
def get_flops(model, batch_size=1):
try:
concrete = tf.function(lambda x: model(x))
concrete_func = concrete.get_concrete_function(
tf.TensorSpec([batch_size, 224, 224, 3], tf.float32))
frozen_func = convert_to_constants.convert_variables_to_constants_v2(concrete_func)
graph_def = frozen_func.graph.as_graph_def()
with tf.Graph().as_default() as graph:
tf.graph_util.import_graph_def(graph_def, name='')
run_meta = tf.compat.v1.RunMetadata()
opts = tf.compat.v1.profiler.ProfileOptionBuilder.float_operation()
flops = tf.compat.v1.profiler.profile(graph=graph, run_meta=run_meta, cmd='op', options=opts)
return flops.total_float_ops
except Exception as e:
print(f"FLOPs 계산 실패: {e}")
return None
(1) CNN
-
총 필터 수: 224개
-
이미지 1장 당 FLOPs : 1,042,859,422 (약 1.04 GFLOPs)
이미지 7,500장 : 약 7.82 TFLOPs -
Test Accuracy : 0.7092
-
Confusion Matrix
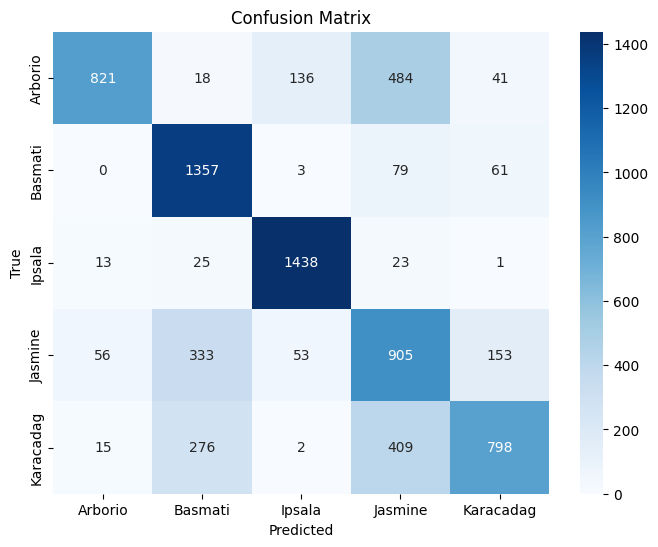
Class Precision Recall F1-Score Support Arborio 0.91 0.55 0.68 1500 Basmati 0.68 0.90 0.77 1500 Ipsala 0.88 0.96 0.92 1500 Jasmine 0.48 0.60 0.53 1500 Karacadag 0.76 0.53 0.62 1500 Accuracy 0.71 7500 Macro Avg 0.74 0.71 0.71 7500 Weighted Avg 0.74 0.71 0.71 7500
(2) CNN 경량화
-
총 필터 수: 24개
-
이미지 1장 당 FLOPs : 7,551,694 (약 7.55 MFLOPs)
이미지 7,500장 : 약 56.64 GFLOPs -
Test Accuracy : 0.7456
-
Confusion Matrix
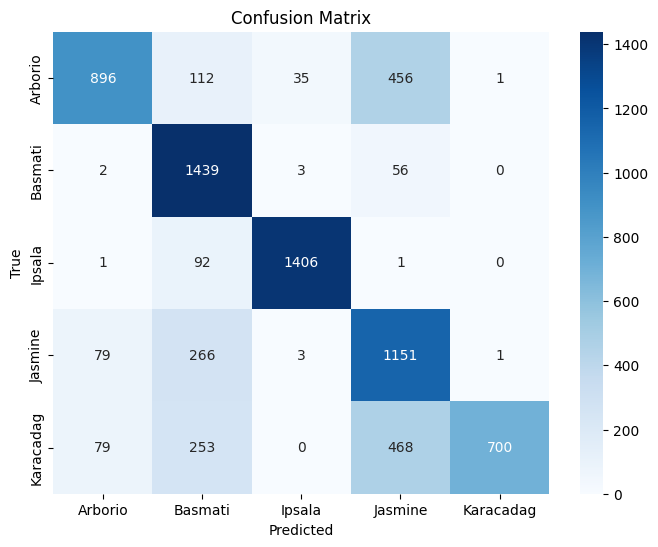
Class Precision Recall F1-Score Support Arborio 0.85 0.60 0.70 1500 Basmati 0.67 0.96 0.79 1500 Ipsala 0.97 0.94 0.95 1500 Jasmine 0.54 0.77 0.63 1500 Karacadag 1.00 0.47 0.64 1500 Accuracy 0.75 7500 Macro Avg 0.80 0.75 0.74 7500 Weighted Avg 0.80 0.75 0.74 7500
(3) GoogLeNet
-
총 필터 수: 5,808개
-
이미지 1장 당 FLOPs : 3,179,339,598 (약 3.18 GFLOPs)
이미지 7,500장 : 약 23.85 TFLOPs -
Test Accuracy : 0.8675
-
Confusion Matrix
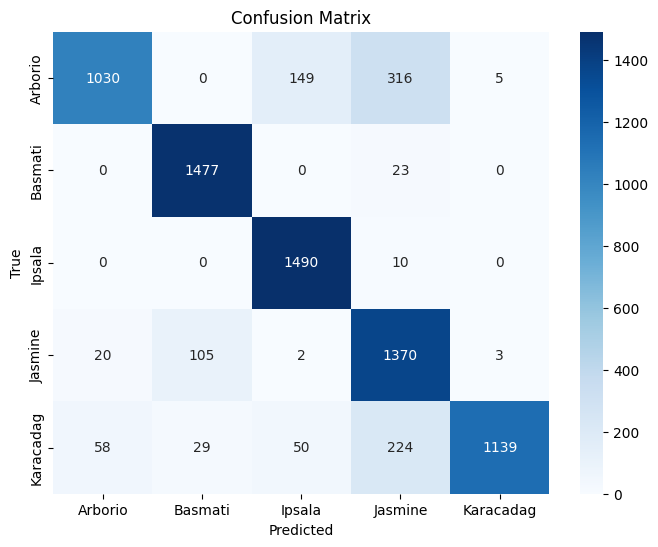
Class Precision Recall F1-Score Support Arborio 0.93 0.69 0.79 1500 Basmati 0.92 0.98 0.95 1500 Ipsala 0.88 0.99 0.93 1500 Jasmine 0.71 0.91 0.80 1500 Karacadag 0.99 0.76 0.86 1500 Accuracy 0.87 7500 Macro Avg 0.89 0.87 0.87 7500 Weighted Avg 0.89 0.87 0.87 7500
(4) GoogLeNet 경량화
-
총 필터 수: 1,456개
-
이미지 1장 당 FLOPs : 280,058,490 (약 0.28 GFLOPs)
이미지 7,500장 : 약 2.10 TFLOPs -
Test Accuracy : 0.9319
-
Confusion Matrix
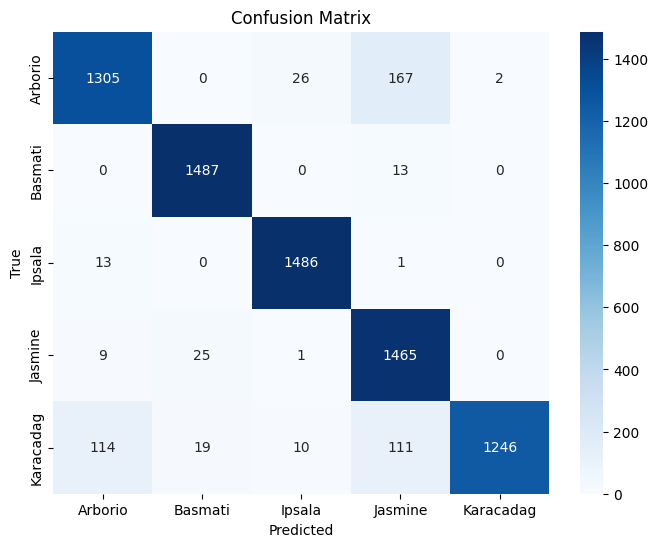
Class Precision Recall F1-Score Support Arborio 0.91 0.87 0.89 1500 Basmati 0.97 0.99 0.98 1500 Ipsala 0.98 0.99 0.98 1500 Jasmine 0.83 0.98 0.90 1500 Karacadag 1.00 0.83 0.91 1500 Accuracy 0.93 7500 Macro Avg 0.94 0.93 0.93 7500 Weighted Avg 0.94 0.93 0.93 7500
(5) VGG16
-
총 필터 수: 4,320개
-
이미지 1장 당 FLOPs : 30,713,485,342 (약 30.71 GFLOPs)
이미지 7,500장 : 약 226.30 TFLOPs -
Test Accuracy : 0.9649
-
Confusion Matrix
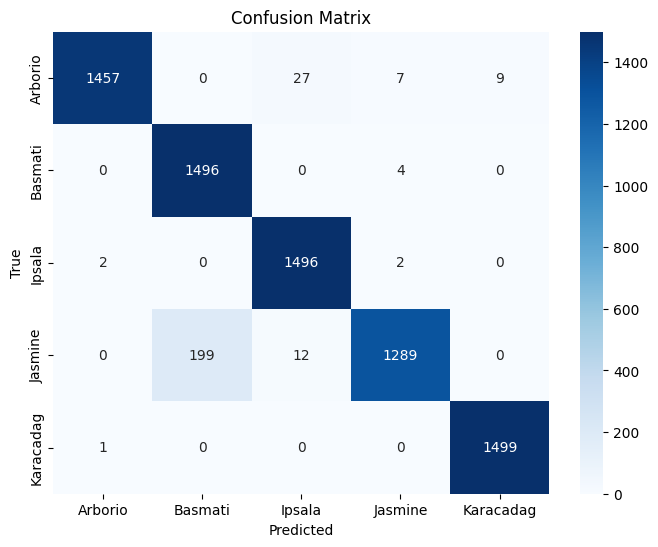
Class Precision Recall F1-Score Support Arborio 1.00 0.97 0.98 1500 Basmati 0.88 1.00 0.94 1500 Ipsala 0.97 1.00 0.99 1500 Jasmine 0.99 0.86 0.92 1500 Karacadag 0.99 1.00 1.00 1500 Accuracy 0.96 7500 Macro Avg 0.97 0.96 0.96 7500 Weighted Avg 0.97 0.96 0.96 7500
(6) VGG 경량화
-
총 필터 수: 2,688개
-
이미지 1장 당 FLOPs : 27,938,627,102 (약 27.94 GFLOPs)
이미지 7,500장 : 약 290.54 TFLOPs -
Test Accuracy : 0.9227
-
Confusion Matrix
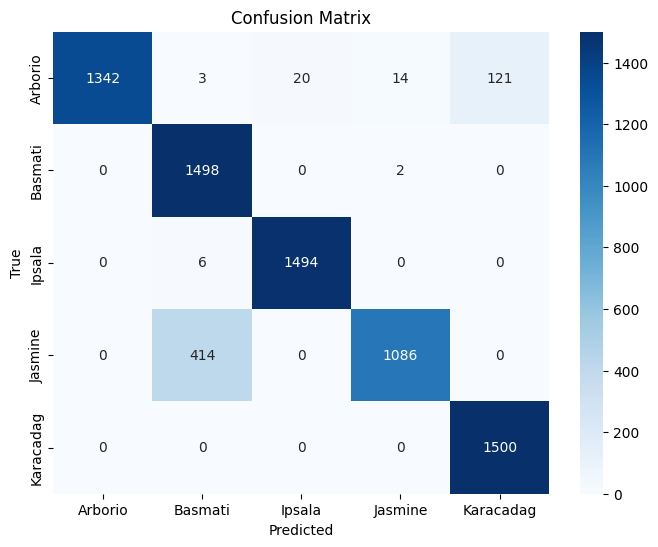
Class Precision Recall F1-Score Support Arborio 1.00 0.89 0.94 1500 Basmati 0.78 1.00 0.88 1500 Ipsala 0.99 1.00 0.99 1500 Jasmine 0.99 0.72 0.83 1500 Karacadag 0.93 1.00 0.96 1500 Accuracy 0.92 7500 Macro Avg 0.94 0.92 0.92 7500 Weighted Avg 0.94 0.92 0.92 7500
(7) VGG Custom
-
총 필터 수: 288개
-
이미지 1장 당 FLOPs : 1,203,943,966 (약 1.20 GFLOPs)
이미지 7,500장 : 약 9.02 TFLOPs -
Test Accuracy : 0.9909
-
Confusion Matrix
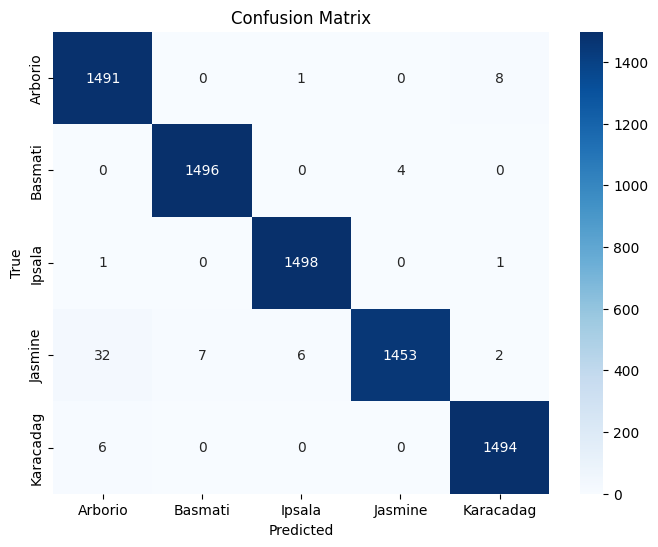
Class Precision Recall F1-Score Support Arborio 0.97 0.99 0.98 1500 Basmati 1.00 1.00 1.00 1500 Ipsala 1.00 1.00 1.00 1500 Jasmine 1.00 0.97 0.98 1500 Karacadag 0.99 1.00 0.99 1500 Accuracy 0.99 7500 Macro Avg 0.99 0.99 0.99 7500 Weighted Avg 0.99 0.99 0.99 7500
(8) 성능비교
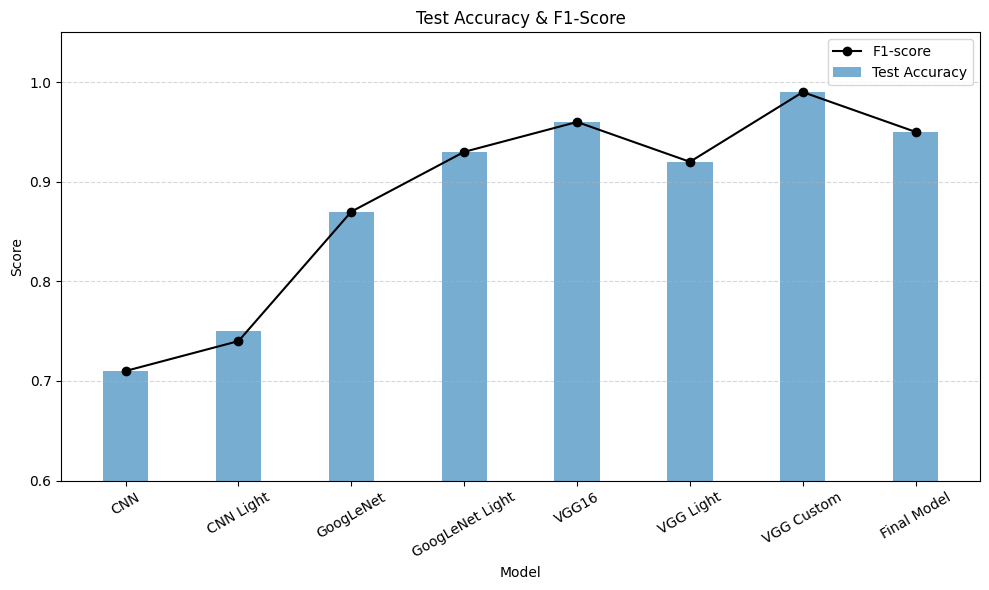
| 모델 이름 | Accuracy | Macro Precision | Macro Recall | Macro F1-score |
|---|---|---|---|---|
| CNN | 0.71 | 0.74 | 0.71 | 0.71 |
| CNN Light | 0.75 | 0.80 | 0.75 | 0.74 |
| GoogLeNet | 0.87 | 0.89 | 0.87 | 0.87 |
| GoogLeNet Light | 0.93 | 0.94 | 0.93 | 0.93 |
| VGG16 | 0.96 | 0.97 | 0.96 | 0.96 |
| VGG Light | 0.92 | 0.94 | 0.92 | 0.92 |
| VGG Custom | 0.99 | 0.99 | 0.99 | 0.99 |
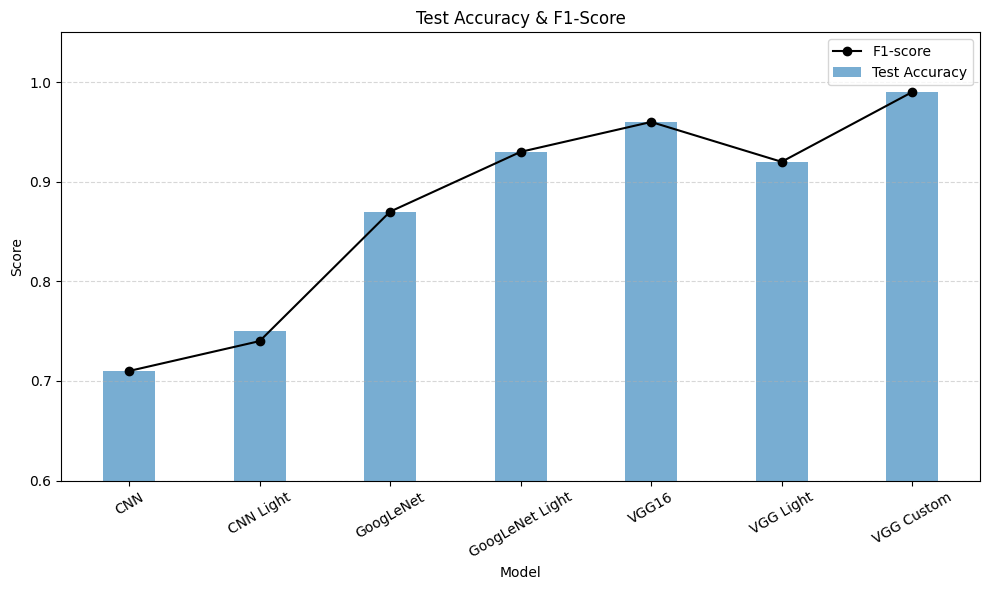
Filter의 개수를 줄이거나 Layer를 제거한 모델들의 일반화 성능이 더욱 높게 나왔다.
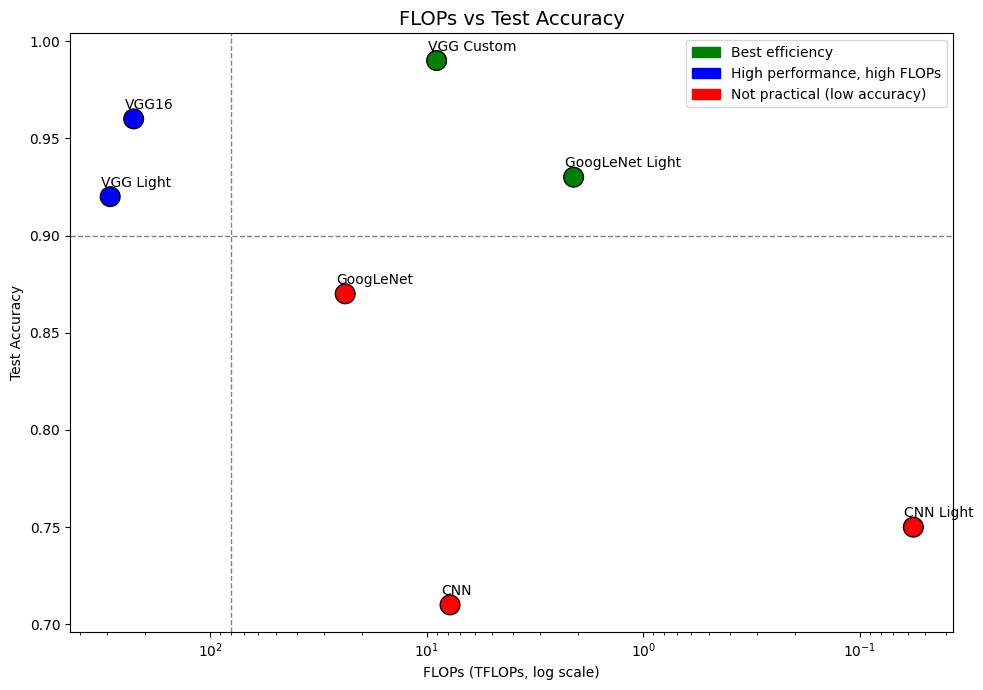
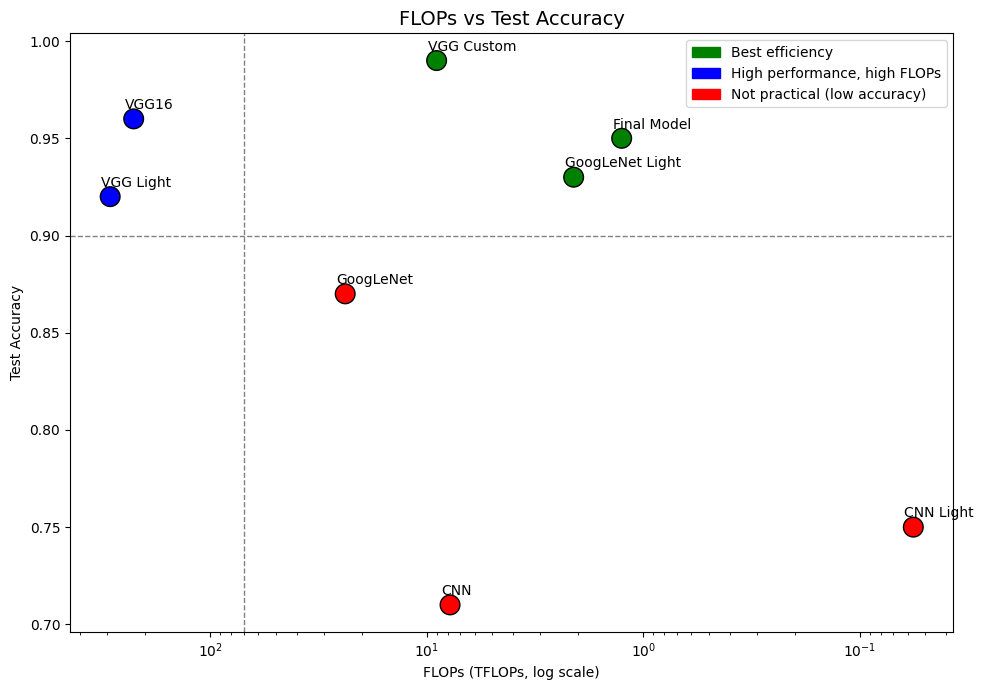
위 그림은 FLOPs vs Test Accuracy 그래프이다. 해당 그래프는 왼쪽 아래로 갈수록 성능은 낮고 계산량은 많으며 오른쪽 위로 갈수록 성능은 높고 계산량은 적은 모델임을 의미한다.
‘Rice Image Dataset’을 기준으로 평가했을 때, VGG Custom 모델이 가장 높은 정확도와 비교적 낮은 FLOPs를 동시에 달성하며 최고의 효율을 보이는 모델로 판단된다. GoogLeNet Light 역시 높은 정확도와 상대적으로 낮은 연산량으로 효율적인 구조임을 확인할 수 있다.
반면 CNN Light는 FLOPs가 약 0.056TFLOPs 수준으로 가장 낮은 연산량을 보였지만 Test Accuracy가 0.9 미만으로 일반화 성능이 부족하다고 판단되어 실사용에는 적합하지 않은 모델로 분류하였다.
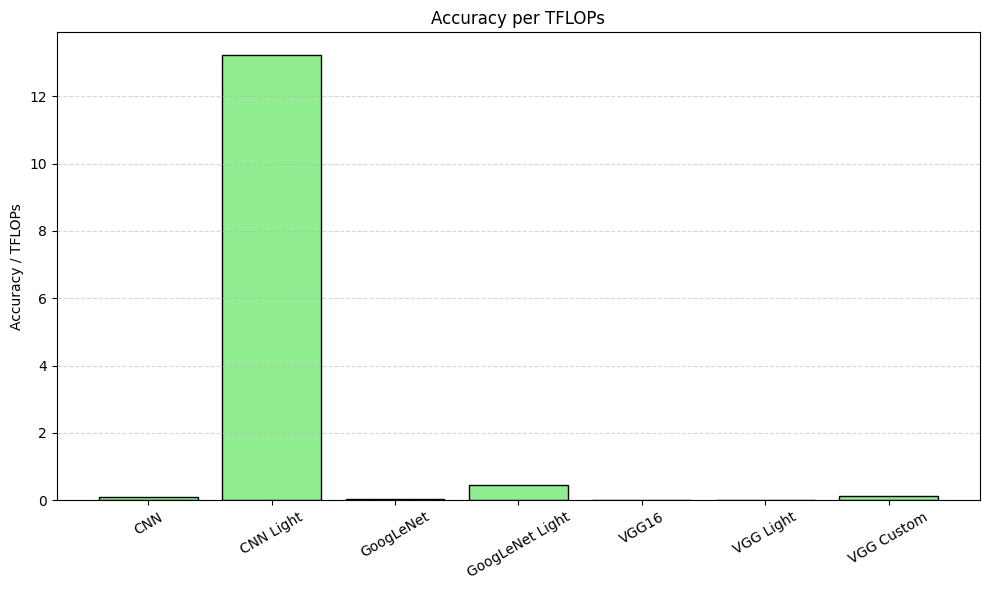
위 그림은 각 모델의 Accuracy / TFLOPs를 시각화한 그래프이다. 이를 통해 CNN Light의 계산 효율이 매우 높음을 확인할 수 있지만 정확도의 뒷받침이 없을 경우 효율성만으로는 모델 선택이 어렵다는 점을 보여준다.
하지만 CNN Light는 Validation Accuracy 0.9970, Validation Loss 0.0108로 학습 성능은 매우 우수하게 나타났다. 따라서 ‘Rice Image Dataset’과 같이 이미지 전처리가 잘 되어 있고 과적합에 대한 제약이 비교적 적은 환경에서는 극단적으로 연산량을 줄인 모델도 시도해볼 수 있다고 판단된다.
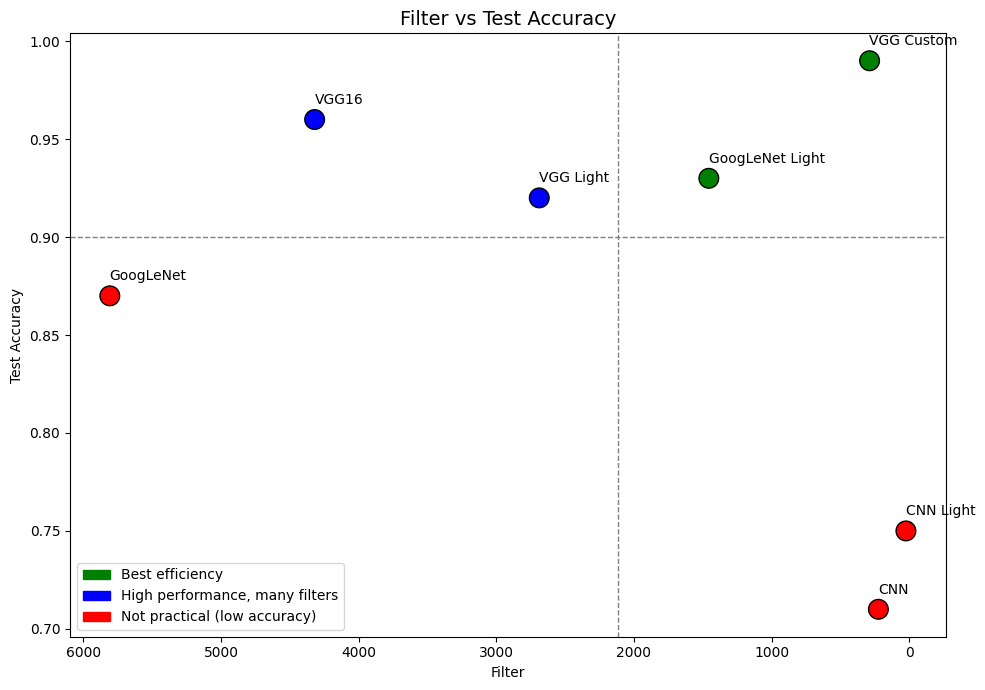
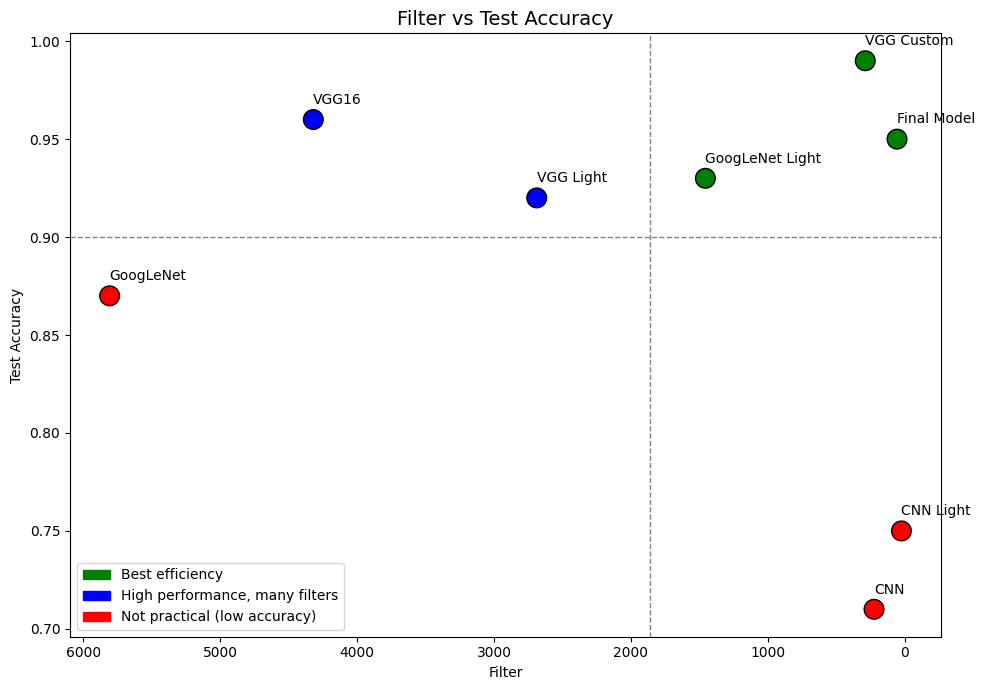
위 그림은 Filter 수와 정확도의 관계를 분석한 Filter vs Test Accuracy 그래프이다. 해당 그래프에서는 Filter 수가 많다고 해서 반드시 성능이 좋은 것은 아님을 알 수 있다.
실제로 VGG Custom, GoogLeNet Light 등은 비교적 적은 수의 필터로도 높은 정확도를 달성하였으며 오히려 필터 수가 적은 모델들이 더 뛰어난 일반화 성능을 보이기도 했다.
서론에서 언급한 바와 같이 GoogLeNet처럼 Filter 개수가 지나치게 많은 구조는 학습이 불안정해지거나 정보가 소실되어 학습되지 않는 형상이 발생할 수 있다. 특히 ‘Rice Image Dataset’처럼 비교적 단순한 이미지의 경우 이러한 문제는 더욱 뚜렷하게 나타날 수 있으므로 주의가 필요하다.
5. 결론
본 프로젝트에서는 모델 구조를 단순히 깊게 설계하거나 필터 수를 늘리는 방식보다는 학습에 실질적으로 기여하지 않는 구조를 제거하는 경량화 전략이 오히려 더 나은 성능을 낼 수 있음을 확인하였다.
Feature Map을 시각적으로 확인한 결과, 일부 모델에서는 이미지가 비교적 단순하고 전처리가 잘 되어 있음에도 불구하고 의미 있는 특성 추출에 기여하지 않는 필터들이 다수 존재하였다. 따라서 필터 수를 줄이거나 레이어를 삭제하는 방식으로 모델을 경량화한 결과, 실제 테스트 성능에서 오히려 일반화가 더 잘 되는 현상을 확인할 수 있었다.
실제로 ‘4. 모델별 일반화 성능 비교‘에서 확인할 수 있듯이 경량화된 모델들이 오히려 더 우수한 성능을 보이는 경우가 많았으며 이는 필터 수가 많다고 반드시 좋은 모델이 되는 것은 아님을 보여주는 결과였다.
이를 바탕으로 CNN Light의 압도적으로 낮은 계산량과 VGG Custom의 뛰어난 일반화 성능이라는 각 모델의 장점을 결합한 최종 개선 모델을 설계하였다. 이 모델은 CNN Light처럼 8 → 16 필터 구조를 유지하면서 VGG Custom과 같이 두 번째 풀링 이전에 Convolution 층을 추가하여 표현력을 강화하였고 Global Average Pooling과 Dropout을 적용하여 경량화와 성능 모두를 고려하였다.
(1) 최종 모델
-
CNN Light와 같이 필터의 개수를 8 → 16으로 제한하여 CNN Light의 극단적으로 적은 계산량을 가져가고 VGG Custom과 같이 두 번째 풀링 이전에 Convolution 층을 추가하여 표현력을 확보하였다. 또한 Global Average Pooling과 Dropout을 적용하여 경량화와 성능 모두를 고려한 모델이다.
def final_model(input_shape, num_classes): inputs = tf.keras.Input(shape=input_shape) x = tf.keras.layers.Conv2D(8, (3,3), activation='relu', padding='same')(inputs) x = tf.keras.layers.MaxPooling2D((2,2), strides = (2,2))(x) x = tf.keras.layers.Conv2D(16, (3,3), activation='relu', padding='same')(x) x = tf.keras.layers.Conv2D(16, (3,3), activation='relu', padding='same')(x) x = tf.keras.layers.Conv2D(16, (3,3), activation='relu', padding='same')(x) x = tf.keras.layers.MaxPooling2D((2,2), strides = (2,2))(x) x = layers.GlobalAveragePooling2D()(x) x = tf.keras.layers.Flatten()(x) x = tf.keras.layers.Dense(512, activation='relu')(x) x = layers.Dropout(0.3)(x) outputs = tf.keras.layers.Dense(num_classes, activation='softmax')(x) model = tf.keras.Model(inputs, outputs) return model final_model = final_model(input_shape=img_size + (3,), num_classes=5) final_model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy']) final_model.summary()
Final Model Summary
| Layer (type) | Output Shape | Param # |
|---|---|---|
| input_layer_10 (InputLayer) | (None, 224, 224, 3) | 0 |
| conv2d_32 (Conv2D) | (None, 224, 224, 8) | 224 |
| max_pooling2d_20 (MaxPooling2D) | (None, 112, 112, 8) | 0 |
| conv2d_33 (Conv2D) | (None, 112, 112, 16) | 1,168 |
| conv2d_34 (Conv2D) | (None, 112, 112, 16) | 2,320 |
| conv2d_35 (Conv2D) | (None, 112, 112, 16) | 2,320 |
| max_pooling2d_21 (MaxPooling2D) | (None, 56, 56, 16) | 0 |
| global_average_pooling2d_6 (GlobalAveragePooling2D) | (None, 16) | 0 |
| flatten_10 (Flatten) | (None, 16) | 0 |
| dense_20 (Dense) | (None, 512) | 8,704 |
| dropout_3 (Dropout) | (None, 512) | 0 |
| dense_21 (Dense) | (None, 5) | 2,565 |
Total params: 17,301 (67.58 KB)
Trainable params: 17,301 (67.58 KB)
Non-trainable params: 0 (0.00 B)
Model Evaluation
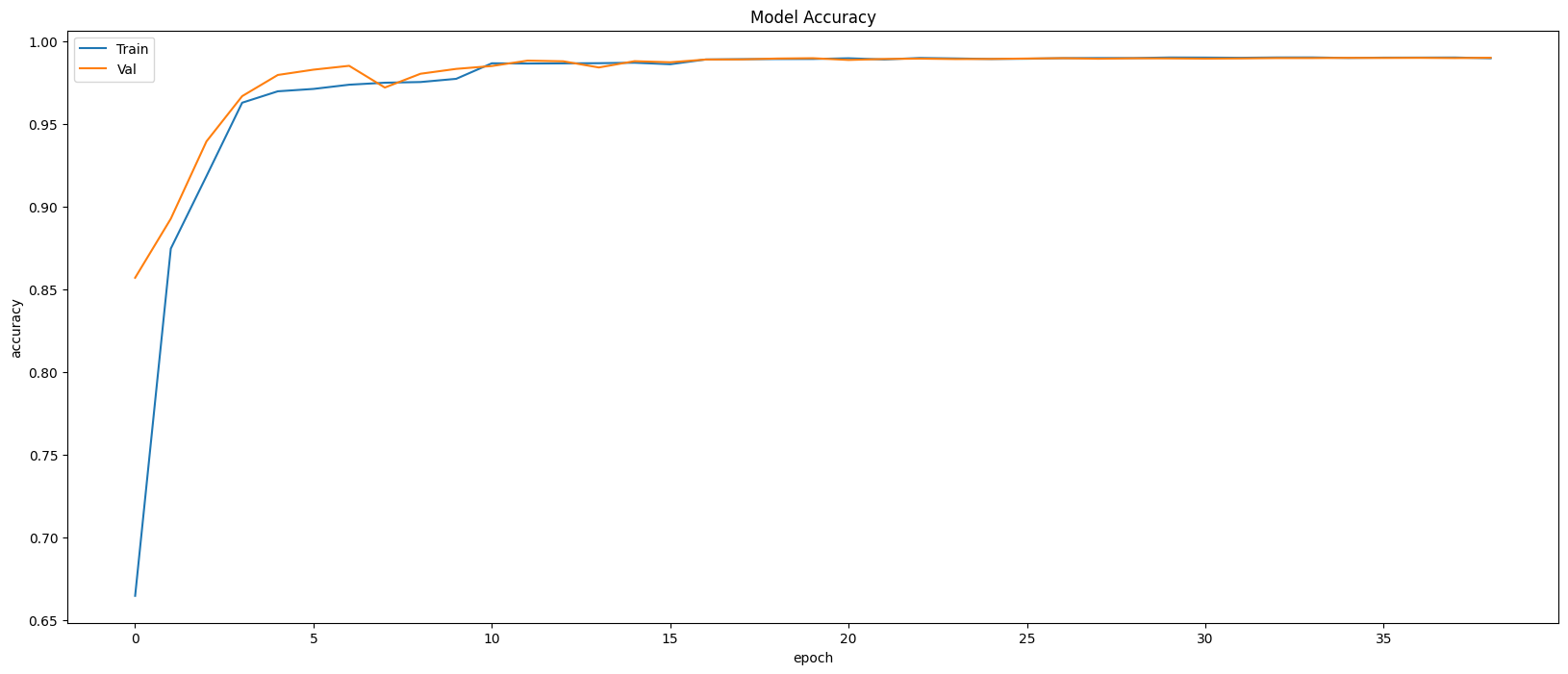
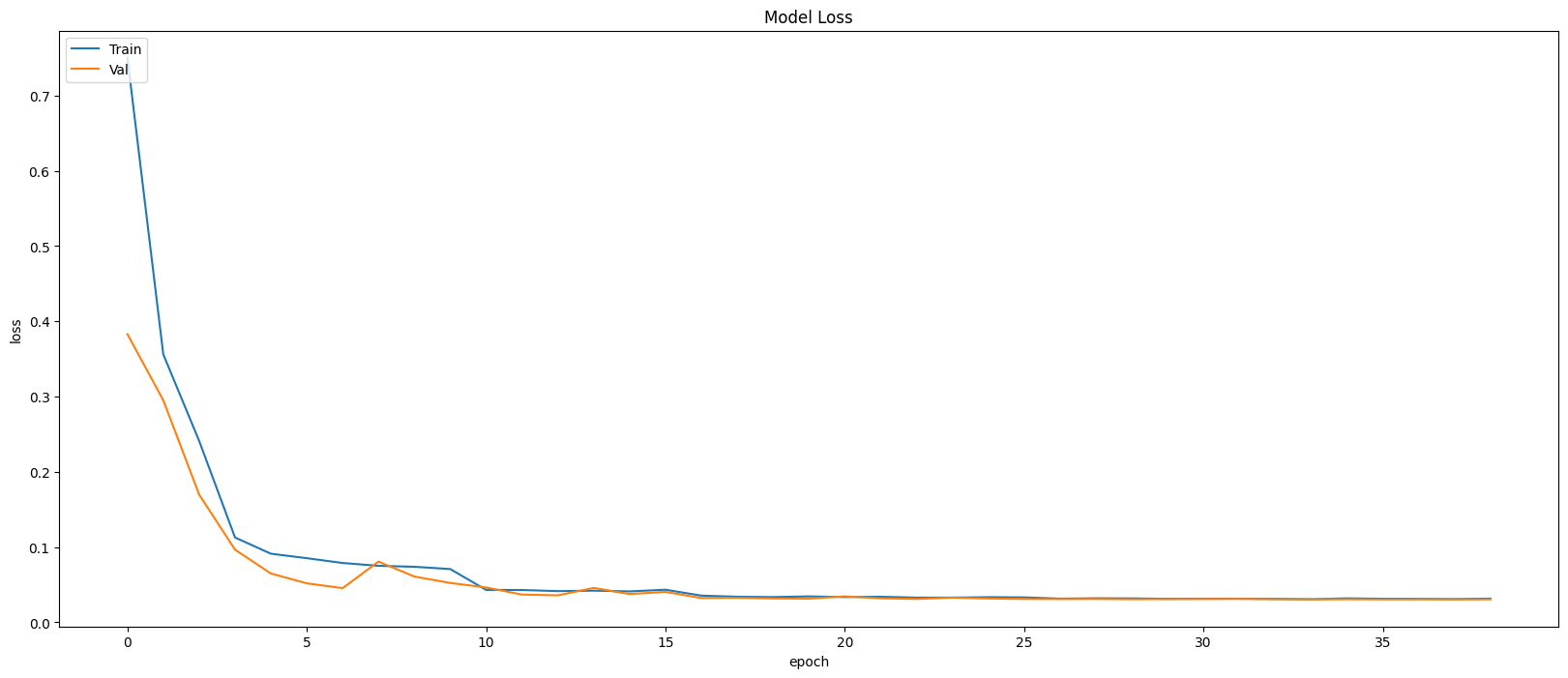
Restoring model weights from the end of the best epoch: 34.
Best score인 34번 째 epoch의 evaluation은 아래와 같다.
Train Accuracy: 0.9899
Train Loss: 0.0310
Validation Accuracy: 0.9897
Validation Loss: 0.0305
Feature Map 시각화




Final Model 일반화 성능
-
총 필터 수: 56개
-
이미지 1장 당 FLOPs : 167,860,766 (약 0.17 GFLOPs)
이미지 7,500장 : 약 1.26 TFLOPs -
Test Accuracy : 0.9533
-
Confusion Matrix
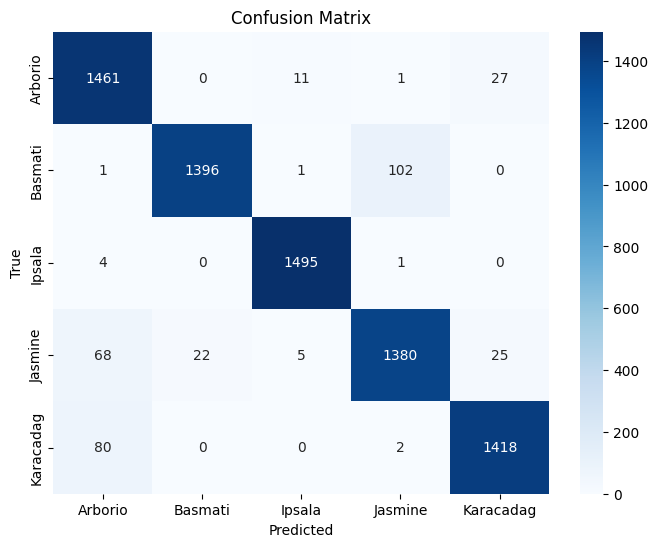
Class Precision Recall F1-Score Support Arborio 0.91 0.97 0.94 1500 Basmati 0.98 0.93 0.96 1500 Ipsala 0.99 1.00 0.99 1500 Jasmine 0.93 0.92 0.92 1500 Karacadag 0.96 0.95 0.95 1500 Accuracy 0.95 7500 Macro Avg 0.95 0.95 0.95 7500 Weighted Avg 0.95 0.95 0.95 7500 -
Final Model은 Test Accuracy 0.9533, 필터 수 56개, 최종 연산량 1.26 TFLOPs로 GoogLeNet Light보다 더 높은 정확도를 유지하면서도 계산량은 더욱 낮은 수준을 달성하였다.
(2) 최종 성능 비교표
위의 시각화된 성능 비교 그래프에서 확인할 수 있듯이 Final Model은 정확도와 효율성 측명 모두에서 우상단에 위치한다. 이는 단순히 계산량만 줄인 것이 아닌 효과적인 구조 설계를 통해 실질적인 성능 개선까지 달성한 사례라 할 수 있다.
CNN Light와 같이 극단적으로 연산량을 줄인 모델과 비교해보면 Final Model은 약간의 계산량을 추가함으로써 현실적인 성능 수준을 확보한 균형 잡힌 모델로 평가된다. 이는 경량화 모델 설계시 성능-연산량의 균형이 중요하다는 점을 잘 보여준다.
(3) 연구 의의와 활용 가능성
본 프로젝트는 Feature Map을 기반으로 시각적으로 분석하여 의미없는 필터를 제거하는 방식으로 모델 경량화를 시도하였다. 이는 기존 연구에서 다뤄지지 않았던 접근 방법으로 다양한 CNN 구조를 실험적으로 비교하고 FLOPs 계산량 및 필터 수와의 관계를 장량적으로 분석하였다. 이로써 단순한 구조 최적화만으로도 높은 성능을 유지하면서 연산 효율성을 극대화할 수 있음을 입증하였다.
최종적으로 제안된 Final Model은 낮은 연산량에도 불구하고 95% 이상의 정확도를 유지하며 성능과 효율의 균형을 모두 고려한 모델 설계가 가능함을 실증적으로 확인하였다. 이는 향후 모바일 디바이스나 엣지 컴퓨팅 환경처럼 제한된 연산 자원 내에서도 실용적인 딥러닝 모델을 구현한느 데에 참고할 수 있는 유의미한 사례가 될 수 있다.
6. Reference
-
Koklu, Murat. “Rice Image Dataset.” Kaggle. Accessed March 26, 2025. https://www.kaggle.com/datasets/muratkokludataset/rice-image-dataset/data.
-
Joshi, Shardul. “Rice Classification Using VGG16 - 99% Accuracy.” Kaggle, September 8, 2022. https://www.kaggle.com/code/sharduljoshi29/rice-classification-using-vgg16-99-accuracy.
-
최진영. “산업인공지능 수업자료”. 아주대학교 산업공학과. 2024.