import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
1. 데이터 리모델링과 처리
- 주어진 데이터를
Pandas DataFrame으로 만들고 groupby기능을 이용해 Year별 총 Sales를 구하세요.
- 구한 결과를 바탕으로 Year별 총 매출을
Total_Sales라는 새로운 컬럼으로 추가한 DataFrame을 출력하세요.
| Year |
Quater |
Sales |
| 2023 |
Q1 |
200 |
| 2023 |
Q2 |
300 |
| 2023 |
Q3 |
250 |
df = pd.DataFrame({
"Year" : [2023, 2023, 2023],
"Quater" : ["Q1", "Q2", "Q3"],
"Sales" : [200, 300, 250]
})
Year_sum = df.groupby("Year").sum()
df["Total_Sales"] = Year_sum.loc[2023, "Sales"]
df
|
Year |
Quater |
Sales |
Total_Sales |
| 0 |
2023 |
Q1 |
200 |
750 |
| 1 |
2023 |
Q2 |
300 |
750 |
| 2 |
2023 |
Q3 |
250 |
750 |
2. 정형 데이터와 비정형 데이터 처리
정형 데이터 처리
- 주어진 데이터를
DataFrame으로 만들고 Age가 30세 이상(>= 30), Salary가 5만 이상(>= 50000)인 직원만 필터링한 DataFrame을 만드세요.
- 필터링 된 결과에서 직원의 Name, Age, Department 컬럼만 출력하세요. (또는 필요한 컬럼만)
data = {
"ID" : [1, 2, 3, 4, 5],
"Name" : ["Alice", "Bob", "Charlie", "David", "Eve"],
"Age" : [25, 32, 45, 29, 40],
"Department" : ["HR", "Finance", "IT", "Marketing", "IT"],
"Salary" : [48000, 52000, 60000, 45000, 70000]
}
df = pd.DataFrame(data)
r_df = df[(df["Age"] >= 30) & (df["Salary"] >= 50000)]
r_df[["Name", "Age", "Department"]]
|
Name |
Age |
Department |
| 1 |
Bob |
32 |
Finance |
| 2 |
Charlie |
45 |
IT |
| 4 |
Eve |
40 |
IT |
비정형 데이터 처리
- API에서 JSON 데이터를 가저와
DataFrame으로 변환 후 아래 필드를 추출해 새로운 DataFrame을 만드세요.
| 필드 |
변환 내용 |
id |
ID |
name |
Name |
username |
Username |
email |
Email |
adress.city |
City |
company.name |
Company |
City가 "Lebsackbury" 또는 "Roscoeview"에 해당하는 사용자만 필터링하세요.- 필터링 된
DataFrame을 CSV파일로 저장하세요.
df = pd.read_json("https://jsonplaceholder.typicode.com/users")
new_df = pd.DataFrame({
"ID" : df["id"],
"Name" : df["name"],
"Username" : df["username"],
"Email" : df["email"],
"City" : df["address"].apply(lambda x : x["city"]),
"Company" : df["company"].apply(lambda x : x["name"])
})
new_df = new_df[(new_df["City"] == "Lebsackbury") | (new_df["City"] == "Roscoeview")]
new_df.to_csv("new_df.csv", index=False)
new_df
|
ID |
Name |
Username |
Email |
City |
Company |
| 4 |
5 |
Chelsey Dietrich |
Kamren |
Lucio_Hettinger@annie.ca |
Roscoeview |
Keebler LLC |
| 9 |
10 |
Clementina DuBuque |
Moriah.Stanton |
Rey.Padberg@karina.biz |
Lebsackbury |
Hoeger LLC |
df = pd.read_json("https://jsonplaceholder.typicode.com/users")
df = pd.json_normalize(df["address"])
df
|
street |
suite |
city |
zipcode |
geo.lat |
geo.lng |
| 0 |
Kulas Light |
Apt. 556 |
Gwenborough |
92998-3874 |
-37.3159 |
81.1496 |
| 1 |
Victor Plains |
Suite 879 |
Wisokyburgh |
90566-7771 |
-43.9509 |
-34.4618 |
| 2 |
Douglas Extension |
Suite 847 |
McKenziehaven |
59590-4157 |
-68.6102 |
-47.0653 |
| 3 |
Hoeger Mall |
Apt. 692 |
South Elvis |
53919-4257 |
29.4572 |
-164.2990 |
| 4 |
Skiles Walks |
Suite 351 |
Roscoeview |
33263 |
-31.8129 |
62.5342 |
| 5 |
Norberto Crossing |
Apt. 950 |
South Christy |
23505-1337 |
-71.4197 |
71.7478 |
| 6 |
Rex Trail |
Suite 280 |
Howemouth |
58804-1099 |
24.8918 |
21.8984 |
| 7 |
Ellsworth Summit |
Suite 729 |
Aliyaview |
45169 |
-14.3990 |
-120.7677 |
| 8 |
Dayna Park |
Suite 449 |
Bartholomebury |
76495-3109 |
24.6463 |
-168.8889 |
| 9 |
Kattie Turnpike |
Suite 198 |
Lebsackbury |
31428-2261 |
-38.2386 |
57.2232 |
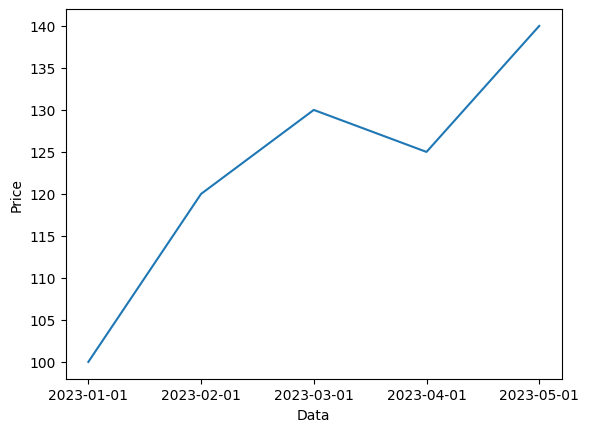
3. 시각화 및 시계열 데이터 활용
- 아래 데이터를
Pandas와 Matplotlib를 사용해 시계열 그래프로 시각화하세요.
- X축은 날짜, Y축은 가격으로 설정하고 가격의 추세를 선 그래프로 나타내세요.
| Data |
Price |
| 2023-01-01 |
100 |
| 2023-02-01 |
120 |
| 2023-03-01 |
130 |
| 2023-04-01 |
125 |
| 2023-05-01 |
140 |
df = pd.DataFrame({
"Data" : ["2023-01-01", "2023-02-01", "2023-03-01", "2023-04-01", "2023-05-01"],
"Price" : [100, 120, 130, 125, 140]
})
plt.plot(df["Data"], df["Price"])
plt.xlabel("Data")
plt.ylabel("Price")
plt.show()