Natural Language Processing
한 줄 정리
| 한 줄 정리 | 비고 | |
|---|---|---|
| NLP | 자연어 즉, 인간의 언어를 컴퓨터가 이해할 수 있도록 만든 알고리즘 혹은 모델 | |
| RNN | 뉴런이 정보를 처리한 후 자기 자신에게 되먹임 하는 cycle을 가진 모델로 과거의 정보를 기억하고 최신 데이터를 갱신하는 모델 | |
| LSTM | RNN의 기울기 소실을 해결하여 과거에서 현재까지 필요한 정보를 기억할 수 있도록 만든 모델로 RNN에 기억 셀과 게이트가 추가된 형태 |
Natural Language Processing
-
NLP는 인간의 언어 현상을 컴퓨터와 같은 기계를 이용해서 묘사할 수 있도록 연구하고 이를 구현하는 인공지능 분야 중 하나이다. NLP는 언어의 문법적 구조를 분석하고 문장의 의미를 파악하며 맥락을 이해하는 등 다양한 언어적 과제를 처리한다.
-
NLP의 목표는 컴퓨터가 사람의 언어를 이해하고 자연스럽게 소통하여 유용한 정보를 제공하는 것이다.
NLP의 벡터화
BoW(Bag of Words)
-
문서 내 단어의 등장 빈도수를 벡터로 표현하는 방법이다.
-
BoW 모델에서는 각 문서에 포함된 단어들의 순서나 문법은 무시하고 단어들이 얼마나 등장했는지만 고려한다.
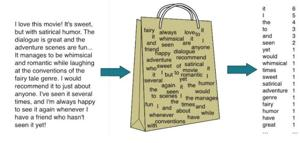
-
해당 단어들의 빈도로 벡터를 구성하여 텍스트를 비교할 수 있다.
TF-IDF(Term Frequency-Inverse Document Frequency)
- 단어의 빈도(Term Frequency)와 해당 단어가 다른 문서에 등정하는 빈도(Inverse Document Frequency)를 결합해 단어의 중요도를 측정하는 방법이다.
Multinomial Naive Bayes(다항 나이브 베이즈)
-
다항 나이브 베이즈는 텍스트 분류와 같이 각 특징의 빈도에 기반해 카테고리를 예측하는 확률적 분류 알고리즘이다.
-
Bayes’s Theorem(베이즈 정리) : 조건부 확률을 계산하는 공식으로 어떤 사건 A가 발생했을 때, 다른 사건 B가 발생할 확률은 아래와 같다.
-
Bayes’s Theorem의 핵심은 서로 독립이라는 가정이며 한 특성의 값이 다른 특성의 값에 영향을 주지 않는다고 가정하고 확률을 계산한다
-
Navie Bayes는 Bayes’s Theorem을 활용하여 특정 데이터가 특정 클래스에 속할 확률을 계산한다. 즉, 주어진 데이터에 특정 클래스가 나타날 확률을 계산하고 가장 높은 확률을 가진 클래스를 최종 분류 결과로 선택한다.
NLP의 사용
- Library Import
import nltk # 자연어 처리를 위한 NLTK 라이브러리 임포트
import os # 운영체제 관련 기능을 사용하기 위한 os 모듈 임포트
import shutil # 파일 및 디렉터리 관리를 위한 shutil 모듈 임포트
import numpy as np # 수치 계산을 위한 NumPy 라이브러리 임포트
import torch # PyTorch 딥러닝 프레임워크 임포트
import torch.nn as nn # 신경망 모델을 위한 PyTorch의 nn 모듈 임포트
import torch.optim as optim # 최적화 함수(Optimizer)를 위한 PyTorch의 optim 모듈 임포트
from torch.utils.data import TensorDataset, DataLoader # 데이터 관리를 위한 PyTorch 모듈 임포트
from nltk.corpus import stopwords # NLTK의 불용어(stopwords) 리스트 사용을 위한 임포트
from nltk.stem import WordNetLemmatizer # 형태소 분석을 위한 WordNetLemmatizer 임포트
from sklearn.datasets import fetch_20newsgroups # 뉴스 그룹 데이터셋 로드를 위한 임포트
from sklearn.model_selection import train_test_split # 학습 및 테스트 데이터 분할을 위한 모듈 임포트
- NLTK 데이터 다운로드 및 설정
# 기존 NLTK 데이터 삭제 (손상된 데이터 문제 해결)
shutil.rmtree('/root/nltk_data', ignore_errors=True) # 손상된 NLTK 데이터를 제거하여 오류 방지
# NLTK 데이터 다운로드 및 경로 설정
nltk.data.path.append("/root/nltk_data") # NLTK 데이터 저장 경로 설정
nltk.download('punkt') # 단어 토큰화를 위한 Punkt 데이터 다운로드
nltk.download('punkt_tab') # Punkt 관련 추가 리소스 다운로드
nltk.download('stopwords') # 불용어(stopwords) 데이터 다운로드
nltk.download('wordnet') # 형태소 분석을 위한 WordNet 데이터 다운로드
nltk.download('omw-1.4') # WordNet 관련 추가 리소스 다운로드
- 뉴스 그룹 데이터셋 로드 및 텍스트 전처리
# 뉴스 그룹 데이터셋 로드 (스포츠와 우주 관련 카테고리 선택)
categories = ['rec.sport.baseball', 'sci.space'] # 사용할 뉴스 그룹 카테고리 지정
newsgroups = fetch_20newsgroups(subset='train', categories=categories) # 지정된 카테고리의 뉴스 데이터셋 로드
texts = newsgroups.data # 뉴스 데이터의 본문 텍스트 가져오기
labels = newsgroups.target # 뉴스 데이터의 레이블 (0: 야구, 1: 우주)
# 텍스트 전처리 함수 정의
def preprocess_text(text):
text = text.lower() # 모든 문자를 소문자로 변환
tokens = nltk.word_tokenize(text) # 문장을 단어 단위로 토큰화
stop_words = set(stopwords.words('english')) # 영어 불용어 로드
tokens = [word for word in tokens if word.isalnum() and word not in stop_words] # 특수문자 및 불용어 제거
lemmatizer = WordNetLemmatizer() # 형태소 분석을 위한 WordNetLemmatizer 객체 생성
tokens = [lemmatizer.lemmatize(word) for word in tokens] # 모든 단어에 대해 형태소 분석 수행
return ' '.join(tokens) # 형태소 분석된 단어를 공백으로 연결하여 반환
# 모든 뉴스 데이터에 대해 전처리 수행
preprocessed_texts = [preprocess_text(text) for text in texts] # 리스트 컴프리헨션을 사용하여 모든 텍스트 전처리
- 단어 사전 생성 및 시퀀스 변환
# 단어 사전 생성 (torchtext 없이 직접 생성)
vocab = {"<pad>": 0} # "<pad>" 토큰을 인덱스 0으로 설정 (패딩 용도)
for text in preprocessed_texts: # 모든 문서에 대해 반복
for token in text.split(): # 각 문서를 단어 단위로 분리하여 반복
if token not in vocab: # 단어가 단어 사전에 없으면 추가
vocab[token] = len(vocab) # 현재 단어 개수를 인덱스로 할당하여 추가
# 단어를 정수 인덱스로 변환하여 시퀀스 데이터 생성
sequences = [[vocab.get(token, 0) for token in text.split()] for text in preprocessed_texts] # 단어를 정수로 변환
- 시퀀스 패딩 및 데이터셋 준비
# 시퀀스 패딩 (최대 길이에 맞춰 <pad> 인덱스(0) 추가)
max_length = max(len(seq) for seq in sequences) # 가장 긴 시퀀스의 길이 계산
def pad_sequence(seq, max_len):
if len(seq) < max_len: # 시퀀스 길이가 최대 길이보다 짧을 경우
seq = seq + [vocab["<pad>"]] * (max_len - len(seq)) # 패딩을 추가하여 길이를 맞춤
else:
seq = seq[:max_len] # 시퀀스가 너무 길면 최대 길이까지만 유지
return seq # 패딩 완료된 시퀀스 반환
# 모든 데이터를 패딩 처리하여 동일한 길이로 변환
X = [pad_sequence(seq, max_length) for seq in sequences] # 리스트 컴프리헨션을 사용하여 패딩 적용
X = np.array(X) # NumPy 배열로 변환
# 레이블을 NumPy 배열로 변환 (정수 인코딩된 상태 유지)
y = np.array(labels) # 레이블을 NumPy 배열로 변환
# 학습 및 평가 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 80% 학습, 20% 평가 데이터로 분리
- PyTorch 데이터셋 및 데이터로더 생성
# NumPy 배열을 PyTorch 텐서로 변환
X_train_tensor = torch.tensor(X_train, dtype=torch.long) # 정수 텐서 변환
y_train_tensor = torch.tensor(y_train, dtype=torch.long) # 정수 레이블 변환
X_test_tensor = torch.tensor(X_test, dtype=torch.long) # 정수 텐서 변환
y_test_tensor = torch.tensor(y_test, dtype=torch.long) # 정수 레이블 변환
# TensorDataset과 DataLoader 생성
batch_size = 32 # 배치 크기 설정
train_dataset = TensorDataset(X_train_tensor, y_train_tensor) # 학습 데이터셋 생성
test_dataset = TensorDataset(X_test_tensor, y_test_tensor) # 테스트 데이터셋 생성
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True) # 학습 데이터 로더 생성 (셔플 활성화)
test_loader = DataLoader(test_dataset, batch_size=batch_size) # 테스트 데이터 로더 생성
- 모델 정의 및 학습
# PyTorch 모델 정의 (Embedding -> Global Average Pooling -> Linear)
class TextClassificationModel(nn.Module):
def __init__(self, vocab_size, embedding_dim, num_classes):
super(TextClassificationModel, self).__init__() # 부모 클래스 초기화
self.embedding = nn.Embedding(vocab_size, embedding_dim) # 임베딩 레이어 생성
self.fc = nn.Linear(embedding_dim, num_classes) # 선형 분류기 레이어 생성
def forward(self, x):
x = self.embedding(x) # 단어 임베딩 적용
x = torch.mean(x, dim=1) # Global Average Pooling 수행
x = self.fc(x) # 선형 분류기 적용
return x # 출력 반환
- 모델 학습 및 평가
# 디바이스 설정
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = TextClassificationModel(len(vocab), 128, 2).to(device)
# 손실 함수 및 옵티마이저 설정
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 모델 학습
for epoch in range(10):
model.train()
total_loss = 0
for batch_x, batch_y in train_loader:
batch_x, batch_y = batch_x.to(device), batch_y.to(device)
optimizer.zero_grad()
loss = criterion(model(batch_x), batch_y)
loss.backward()
optimizer.step()
total_loss += loss.item()
print(f"Epoch {epoch+1}, Loss: {total_loss:.4f}")
Recurrent Neural Network
-
RNN은 순차적 데이터(텍스트, 시간 시계열 데이터 등)을 처리하기 위해 설계된 인공신경망이다.
-
텍스트는 문자의 Sequence로 되어 있다. RNN의 뉴런은 정보를 처리한 후 다시 자기 자신에게 되먹임할 수 있도록 Cycle을 가진다. 이러한 특징으로 데이터가 순환되기 때문에 과거의 정보를 기억하고 최신 데이터로 갱신될 수 있다.
-
RNN architecture는 Input/Hidden/Output Layer로 구성되어 있으며 초기 weight 값들은 랜덤으로 생성된다.
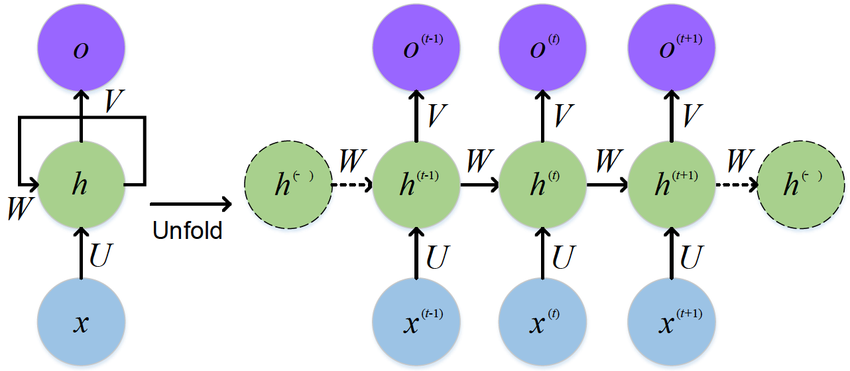
$x^{(t)}$는 Input Sequence의 $t$번째 값
$h^{(t)}$는 Hidden Layer의 $t$번째 Neuron
$o^{(t)}$는 Output Sequence의 $t$번째 값
$U, V, W$는 각각의 Layer에서 사용되는 공유된 weight → RNN의 핵심개념$h_t$는 상태를 나타내며 $h_t = \tanh(h_{t-1}W_h + x_tW_x + b)$로 계산된다.
RNN 추론
-
RNN의 추론은 보통의 신경망과 같이 오른쪽으로 진행하며 순전파를 수행한다.
$h_{next} = \tanh(h_{prev}W_h + x_tW_x + b)$ -
Hidden Layer의 뉴런은 $h^{(t)}=f(h^{(t-1)}, x^{(t)})$ 이며 activation function $f$는 hyperbolic tangent ($\tanh(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}}$)를 사용한다.
-
Hidden Neuron은 아래의 식으로 정의된다.
\[h^{(t)} = \begin{cases} \tanh(W_{xh} \cdot x^{(1)}), t = 1\\ \tanh(W_{hh} \cdot h^{(h-1)} + W_{xh} \cdot x^{(t)}), t > 1 \end{cases}\] -
Output Layer는 $W_{hy}$를 이용해 Hidden Layer의 결과를 다시 한 번 연산하여 Output 산출 $o^{(t)} = W_{hy} \cdot h^{(t)}$
RNN 학습
-
RNN의 학습은 일반적인 오차 역전파법을 적용하여 손실 함수에 대한 매개변수의 기울기를 계산한다.
-
시간 방향으로 펼친 신경망의 오차 역전파법이란 뜻으로 BPTT(Backpropagation Through Time)이라고 한다. RNN은 전후 관계를 갖는 Sequence를 다루기 때문에 기존의 역전파에 추가적인 시간의 개념이 도입된 BPTT를 이용한다.
-
일반적으로 RNN은 Softmax 함수를 사용한다.
\[S(x_i) = \frac{e^{x_i}}{\sum _j e^{x_j}}\] -
Output Layer는 Softmax 함수를 이용해 $o^{(t)} = softmax(W_{hy} \cdot h^{(t)})$
-
시점 $k$ 에서 output neuron의 mini loss function을 $l^{(k)}$ 라고 하면 BPTT 수행 시 시점 $k$ 에서 단계적으로 고려되는 loss function $L^{(k)}$ 는 시점 $k$ 와 그 이후의 mini loss function들의 합으로 정의된다.
\[L^{(k)} = \sum _{l = k} ^{\tau} l^{(l)}\] - 이 이외의 다른 부분은 다른 역전파 방법들과 동일하다.
- Chain rule을 이용한 Gradient 계산
- Gradient를 이용한 Weight 계산
- Cross entropy loss function
- BPTT 문제점과 해결방안
- Gradient exploding
- Gradient 크기를 제한하는 weight clipping을 통해 간단히 해결
- $W_{hh}$를 normalization시켜 spectral radius가 1이 넘지 않게 하는 것으로도 해결 가능
- Gradient vanishing
- Gradient vanishing은 해결하기가 쉽지 않다. 해당 문제를 해결하지 못하면 RNN은 sequence 전체가 아닌 짧은 범위의 몇 개 원소들만 기억하게 된다.
- 긴 sequence를 올바로 학습하기 위해서 LSTM(Long Short Term Memory)를 사용한다.
- Gradient exploding
RNN 구현
-
RNN의 구조를 이용하여 NumPy를 사용해 간단한 RNN을 구현할 수 있다. RNN은 반복할 때, 이전에 계산한 정보를 재사용하는 for 루프를 이용하여 구현 가능하다.
import numpy as np timesteps = 100 input_features = 32 output_features = 64 inputs = np.random.random((timesteps, input_features)) state_t = np.zeros((output_features, )) W = np.random.random((output_features, input_reatures)) U = np.random.random((output_features, output_features)) b = np.random.random((output_features, )) surccesive_outputs = [] for input_t in inputs: output_t = np.tanh(np.dot(W, input_t) + np.dot(U, state_t) + b) surccesive_outputs.append(output_t) state_t = output_t final_output_sequence = np.stack(surccesive_outputs, axis = 0)
Long Short Term Memory
-
LSTM은 기존의 RNN에서 출력과 멀리 있는 정보를 기억할 수 없다는 단점을 보완해 장/단기 기억을 가능하게 설계한 신경망 구조이다. 이는 RNN의 기울기 소실 문제 해결할 수 있다.
-
LSTM은 RNN에 과거에서 현재까지 필요한 정보를 기억할 수 있는 기억 셀($c_t$)을 추가한다.
LSTM 전용의 기억 메커니즘으로 3개의 입력($c_{t-1}, h_{t-1}, x_t$)으로부터 기억 셀($c_t$)을 구한다.
출력인 은닉 상태는 $h_t = \tanh(c_t)$ 에 의해 계산한다. -
LSTM은 RNN에 출력 정보의 양을 조절하는 게이트를 추가한다. 학습 시 기울기를 원만하게 흘려 기울기 소실을 줄일 수 있다.
LSTM의 구조
-
LSTM은 RNN의 Hidden State($h_t$)에 Cell State($C_t$)를 추가한 구조이다.
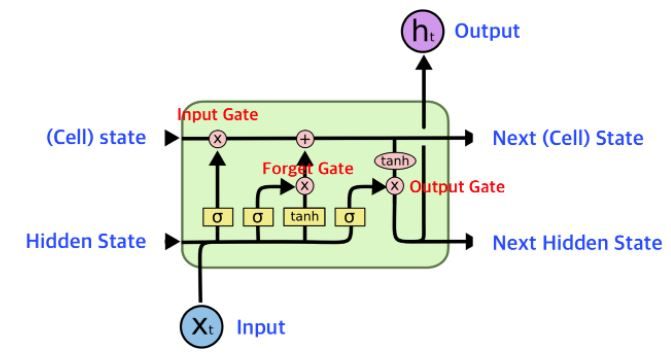
-
셀 스테이트(Cell state) $C_t$
LSTM은 셀 스테이트에 정제된 구조를 가진 게이트(gate)라는 요소를 활용해서 정보를 더하거나 제거하는 기능을 수행한다. -
시그모이드 레이어를 사용한 게이트 구현
게이트는 각 구성요소가 영향을 주게 될지 결정하는 역할을 한다. 0이라는 값을 가지게 되면 해당 구성요소가 미래의 결과에 아무런 영향을 주지 않으며 1이라는 값을 가지게 되면 해당 구성요소가 확실히 미래의 예측 결과에 영향을 주도록 데이터가 흘러가게 한다. -
Forget 게이트
셀 스테이트에서 어떤 정보를 버릴지 선택하는 게이트이다.
$f_t = \sigma(W_f \cdot [h_{t-1}, x_t] + b_f)$ 로 표현되며 $h_{t-1}$과 $x_t$의 입력 값을 받아 0과 1 사이의 값을 출력한다.
출력 값이 1인 경우 완전히 이 값을 유지하게 되고 출력 값이 0이 될 경우 완전히 이 값을 버린다. -
Input 게이트
새로운 정보가 셀 스테이트에 저장될지를 결정하는 게이트이다.
$$ i_t = \sigma(W_i \cdot [h_{t-1}, x_t] + b_i) \\tilde{C_t} = \tanh(W_C \cdot [h_{t-1}, x_t] + b_C) $$
-
오래된 셀 스테이트($C_{t-1}$)를 새로운 스테이트인 $C_t$로 업데이트
$C_t = f_t * C_{t-1} + i_t * \tilde{C_t}$ -
Output 게이트
\(o_t = \sigma(W_o \cdot [h_{t-1}, x_t] + b_o) \\ h_t = o_t * \tanh(C_t)\)어떤 값을 출력할지 결정하는 시그모이드 레이어로 Cell State 값이 tanh함수를 거쳐서 -1과 1 사이의 값으로 출력한다. 시그모이드 레이어에서 얻은 값과 tanh 함수를 거쳐 얻은 값을 곱해서 출력
-
LSTM의 단점
- 매개변수가 많아서 계산이 오래걸린다.
- LSTM을 대신할 게이트가 추가된 방법들이 많이 제안되었다. Gated Recurrent Unit(GRU) 등…
오늘의 회고
- NLP 중심으로 RNN과 LSTM을 학습하였다. 다른 모델도 마찬가지지만 해당 부분은 특히나 Architecture가 중요함을 깨달았으며 해당 Architecture을 수식으로 풀어보며 공부할 수 있었다.