Application Model
한 줄 정리
| 한 줄 정리 | 비고 | |
|---|---|---|
| Word Embedding | 단어를 벡터화 한 것으로 비슷한 의미의 단어들을 서로 가까운 벡터 공간에 위치하게 하여 문맥을 파악할 수 있도록 한 것 | |
| GANs | 두 신경망인 생성자와 판별자를 경쟁적으로 학습시켜 뛰어난 가짜 데이터를 만들기 위한 모델 | |
| Transformer Model | 입력을 병렬로 처리하여 각 단어의 관계를 빠르고 정확하게 처리할 수 있도록 만든 모델 | |
| Attention Mechanism | 각 입력을 동일하게 처리하지 않고 다른 요소와의 관계 등을 고려하여 가중치를 부여해 중요한 부분에 집종하도록 만든 알고리즘 |
Text CNN
-
Text CNN은 text 데이터를 처리하고 분류하기 위해 CNN을 사용하는 모델을 말한다. CNN은 주로 이미지 데이터를 처리하는데 사용되지만 텍스트 데이터 처리에도 성능이 좋다는 것이 Yoon Kim 박사의 논문을 통해 공개 되었다.
-
일반적으로 문장을 Word Embedding 벡터로 변환한 후 CNN 입력으로 사용하게 된다.
-
텍스트 데이터를 임베딩한 후 CNN을 사용해 분류작업을 수행하는 것이 일반적인 진행 순서이다.
Word Embedding
- Word Embedding은 단어를 벡터로 표현하는 방법으로 단어를 밀집 표현으로 변환하는 것으로 비슷한 의미의 단어들은 벡터 공간에서 가깝게 위치한다.
One-Hot Encoding의 문제점
-
One-Hot Encoding의 경우 Index 값만 1이고 나머지는 0으로 표현된다. 이런 벡터 혹은 행렬의 값 대부분이 0으로 표현되는 방법을 희소 표현(Sparse Representation)이라고 한다.
-
이러한 희소 벡터의 문제점은 단어의 개수가 늘어나면 벡터의 차원이 한 없이 커진다. 예를 들어 10,000개의 단어가 있다면 벡터의 차원이 10,000개여야 한다. 인덱스에 해당되는 부분은 1이고 나머지는 0의 값을 가지는데, 이러한 벡터 표현은 공간적 낭비를 불러 일으킨다.
Dense Representation(밀집 표현)
-
희소 표현과 반대되는 표현으로 밀집 표현이 있다. 밀집 표현은 벡터의 차원을 단어 집합의 크기로 상정하지 않고 사용자가 설정한 값으로 모든 단어의 벡터 표현의 차원을 맞춘다. 또한 이 과정에서 더 이상 0과 1만 가진 값이 아니라 실수 값을 가지게 된다.
-
단어의 의미를 내포한 정보를 압축된 형태로 제공하여 다양한 자연어 처리 작업에서 더 효과적으로 사용된다.
희소 표현 밀집 표현 벡터 차원 어휘 전체 크기와 동일한 고차원 벡터 일반적으로 낮은 차원으로 구성 값의 분포 해당 단어에 해당하는 한 위치만 1, 나머지는 0 모든 차원이 의미 있는 값을 가지며 연속적인 실수 값으로 표현 의미 반영 단어 간의 유사성을 반영하지 못한 서로 다른 단어들은 서로 완전히 독립적인 벡터 단어 간의 의미적, 문법적 유사성을 벡터 공간 내의 거리나 방향으로 반영할 수 있음 효율성 대부분의 값이 0이기 때문에 메모리 비효율적일 수 있음 저차원 벡터 사용으로 메모리와 계산 효율성이 높음 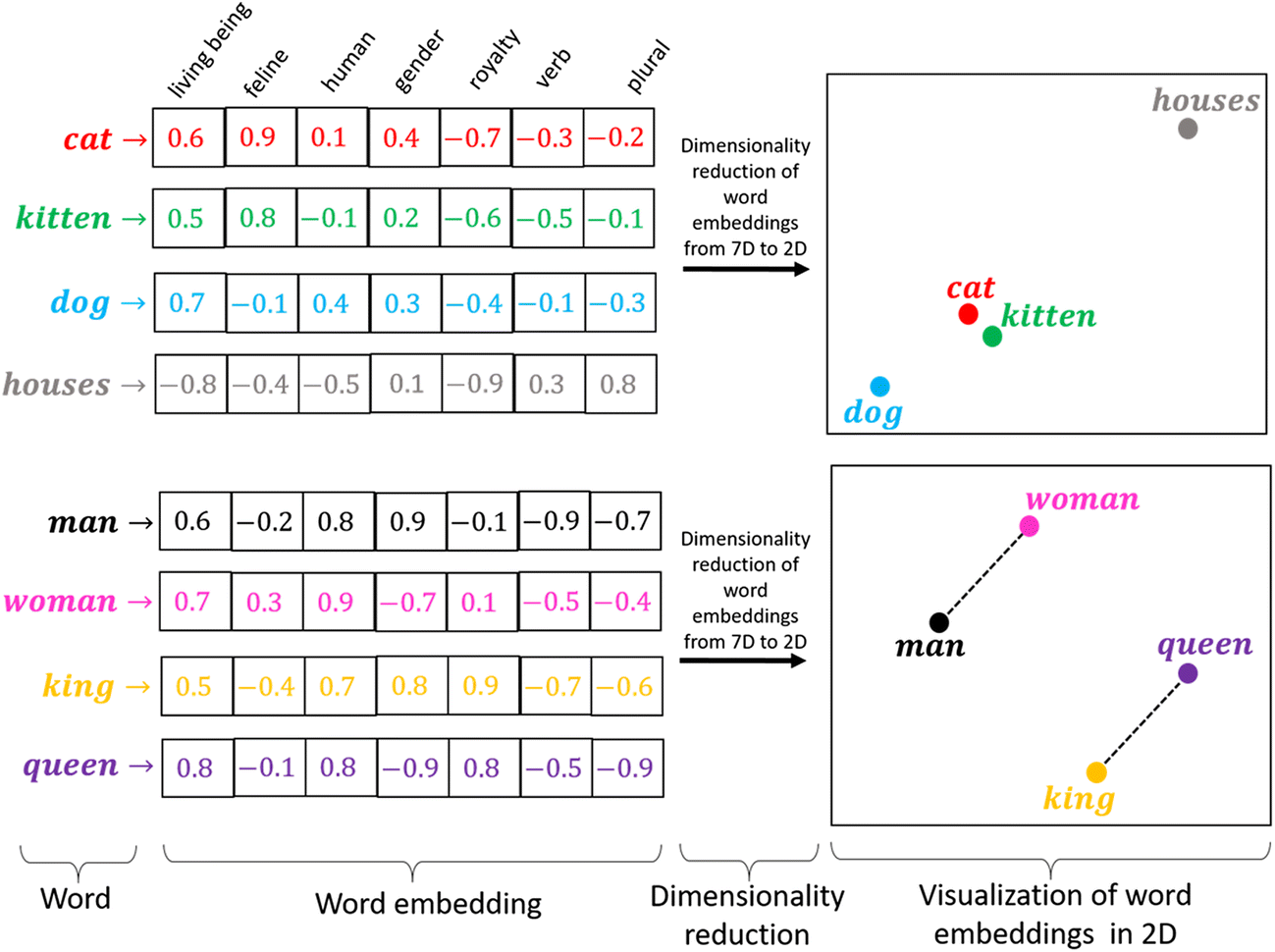
Generative Adversarial Nets(GANs)
-
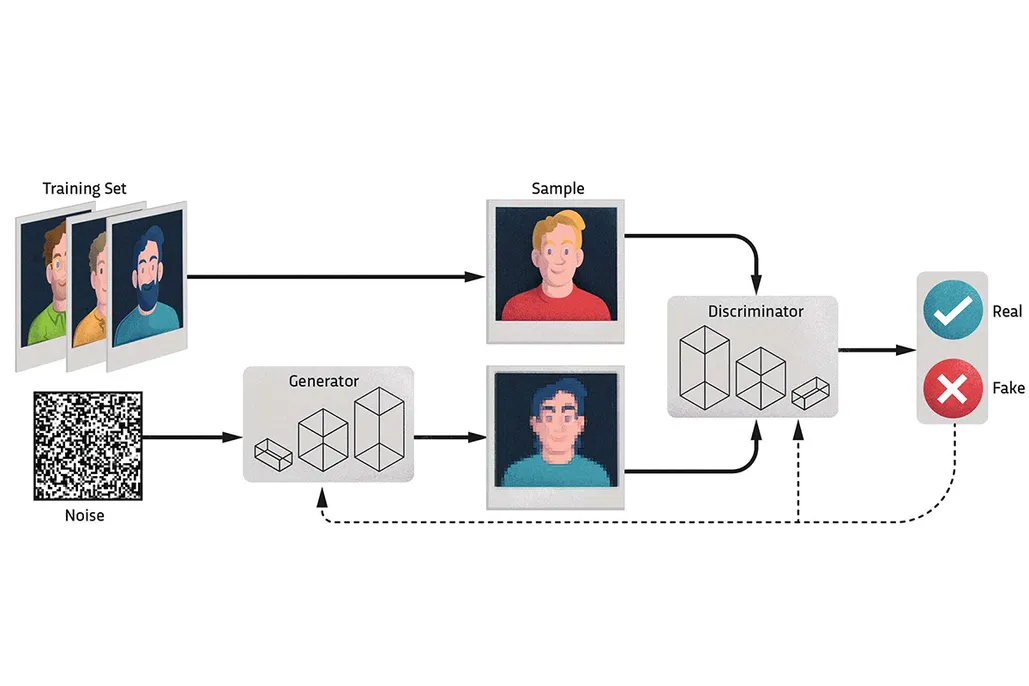
두 신경망이 경쟁적으로 학습하여 하나는 데이터를 생성하고 다른 하나는 이를 판별하며 서로의 성능을 개선하는 딥러닝 모델
-
2014년 Ian J. Goodfellow 등이 발표한 논문 ‘Generative Adversarial Nets’에서 제안되어 해당 논문에서는 지폐 위조범(Generator)과 경찰(Discriminator)에 비유하였다.
-
사람이 인공지능을 지도학습할 필요가 없이 기계 스스로 학습할 수 있는 길을 열었다는 점에서 뜨거운 반응을 얻었으며 이미지, 음성 신호 및 자연어 등의 다양한 분야에서 데이터를 새로 생성하거나 재구성할 수 있다.
-
Generator는 임의의 벡터를 입력 받아 가짜 데이터를 만들어 반별자 네트워크를 속이도록 훈련
-
Discriminator는 실제 학습 데이터와 Generator가 만든 가짜 데이터를 입력으로 받아 훈련 세트에서 온 데이터인지 생성자 네트워크가 만든 데이터인지 판별하는 기준을 설정하면서 생성자의 능력 향상에 적응해간다.
GANs 작동원리
-
Discriminator 네트워크는 전달된 이미지가 실제 이미지인지 가짜 이미지인지를 판별할 수 있는 일반적인 Convolution Network이다.
-
일반 Convolution 분류기는 이미지를 입력 받아 확률을 예측하기 위해 Maxpooling과 같은 기술을 사용하여 다운 샘플링하는 반면, Generator는 랜덤 노이즈 벡터를 입력 받아 이미지를 만드는 업샘플링을 한다.
-
수학적 표현
$min_G max_D V(D,G) = \mathbb{E_{x\sim p_{data}(x)}}[logD(x)] + \mathbb{E_{z\sim p _ {z}(z)}}[log(1-D(G(z)))]$-
D가 아주 뛰어날 때, $x$가 실제로 원본에서 온 것이라면 $D(x) = 1$이 될 것이고 $G(z)$에서 온 것이라면 $D(G(z)) = 0$이 될 것이다.
-
만약 $G(z)$가 완벽하게 위조한다면 $D(x) = \frac{1}{2}$이 될 것이다.
-
D의 입장에서 V의 최대값은 0이 되며 G의 입장에서 최소값은 $-\infty$이다.
\(Max \Rightarrow log(1) + log(1) = 0\) \(Min \Rightarrow \lim _{x \rightarrow \infty} log(x) = -\infty\)
-
GANs 활용
-
실제 이미지를 학습해 가짜 이미지를 만드는데 활용되며 nvidia는 2017년 유명인 20만 명의 사진을 학습시켜 실존하지 않는 사람들의 사진을 무한대로 만들어낼 수 있는 기술을 선보이기도 하였다.
-
영상 합성에도 사용되며 2017년 8월 미국 워싱턴대학교 연구진은 버락 오바마 전 미국 대통령의 가짜 영상을 만들어 화제가 되기도 하였다.
-
MIT의 한 연구진은 수천 개의 이미지와 시를 쌍으로 학습시켜 AI가 이미지를 보고 시를 만들어내도록 하는 연구를 진행하기도 하였으며 30명의 영문학 전문가를 포함한 500명에게 AI가 만든 시와 인간이 쓴 시를 구별하도록 했는데, 이중 60%만 AI가 쓴 시를 선별해 냈다.
-
위와 같은 예시로 불균형 데이터를 갖는 분류 문제에서 GANs를 이용하여 적은 수의 불균형 데이터를 학습하여 비슷한 유형의 불균형 데이터를 생성한다.
GANs의 단점
-
Model Collapsing : 이 현상은 학습 모델이 실제 데이터의 분포를 정확히 따라가지 못하고 다양성을 잃어버리는 현상
-
Oscillation : G와 D가 수렴하지 않고 진동하는 모양새를 보이는 경우
-
G와 D 사이의 Imbalance : 학습을 진행할 때, 처음에 D가 성능이 너무 좋아져서 오히려 G가 학습이 잘 되지 않는 문제
Transformer Model
-
Transformer는 병렬 처리와 Attention 메커니즘을 통해 빠르고 정확한 학습이 가능한 자연어 처리 모델 아키텍처이다.
-
Transformer Model은 Self-attention 메커니즘을 사용해 시퀀스 데이터를 병렬로 처리하고 단어 간의 관계를 빠르고 정확하게 학습할 수 있는 딥러닝 모델이다.
-
Transformer Model은 2017년 구글의 논문 ‘Attention is All You Need’에서 처음 제안되었으며 그 이후 많은 NLP 작업에서 중요한 역할을 하고 있다.
Self-Attention Mechanism
-
Self-Attention은 시퀀스의 각 요소가 다른 모든 요소와의 관계를 고려하여 자신을 다시 계산하는 메커니즘이다.
-
각 단어가 문장 내 다른 모든 단어와의 관계(의존성)를 파악하여 중요도에 따라 가중치를 부여하여 문맥 정보와 긴 거리 의존성을 효과적으로 캡처할 수 있다.
-
Self Attention에서는 Query, Key, Value라는 3가지 변수가 존재한다.
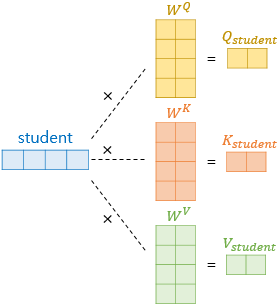
Self Attention은 Query, Key, Value의 시작 값이 동일하여 ‘Self’가 앞에 붙었으며 중간 학습 weight에 의해 최종적인 Query, Key, Value가 달라지게 된다.
-
Self Attention을 구하는 공식은 아래와 같다.
\(Attention(Q, K, V) = Softmax \left( \frac{QK^T}{\sqrt{d_k}} V \right)\)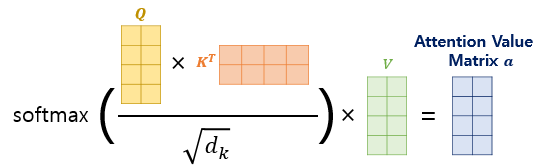
Transformer Model의 구조
-
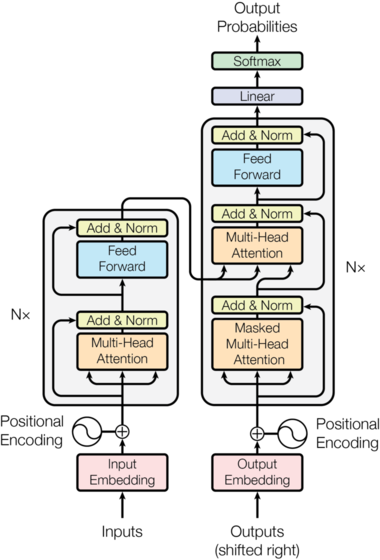
Transformer Model의 구조는 기본적으로 인코더-디코더 구조를 가지고 있다.
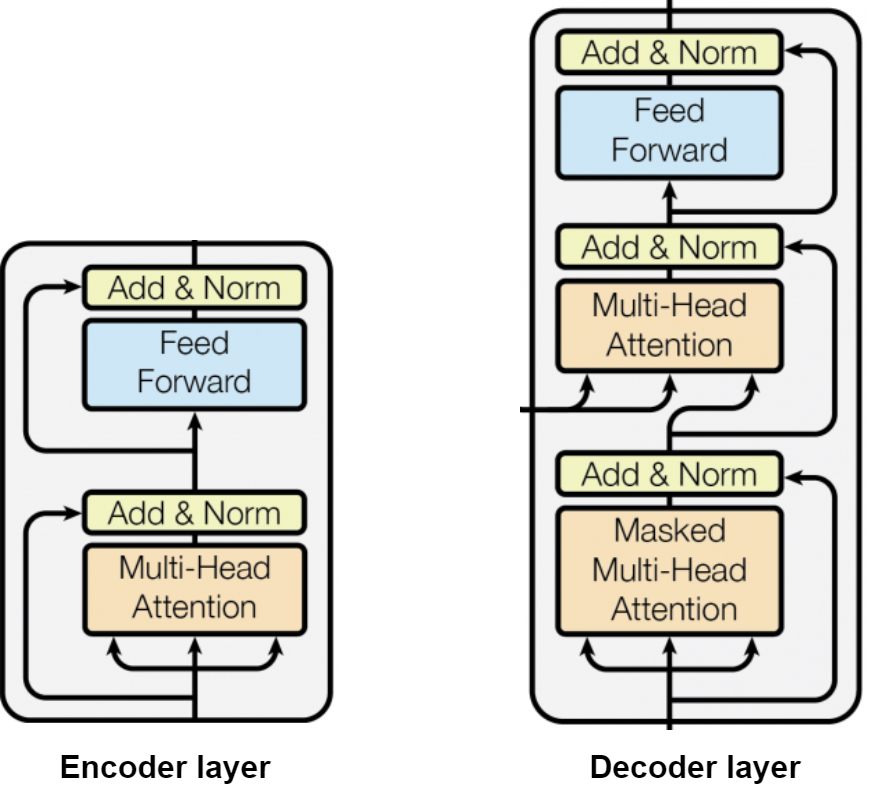
Encoder 구조
-
트랜스포머에서 인코더는 입력 문장의 정보를 추출해 내부 표현을 생성한다. 인코더는 여러 개의 인코더 레이어로 구성되며 각 레이어는 아래의 순서로 이루어져있다.
Self-Attention → Add & Norm → Feed Forward → Add & Norm
Decoder 구조
-
트랜스포머에서 디코더는 인코딩 된 표현을 받아 출력 시퀀스를 생성하는 역할을 한다. 디코더 또한 여러 개의 디코더 레이어로 구성되며 각 레이어는 아래의 순서로 이루어져있다.
Masked Self-Attention → Add & Norm → Encoder-Decoder Attention → Add & Norm → Feed Forward → Add & Norm
오늘의 회고
- 여태 학습하였던 것과 달리 여러 응용 모델을 학습하였다. 응용 모델의 가장 큰 주안점은 Transformer계열 모델이다. nvidia 블로그에 따르면 AI의 발전은 Transformer 이전과 이후로 또 한 번 나뉜다고 한다. Transformer 계열의 BERT계열 모델을 사용해 본 적이 있는데, Transformer의 기본적인 구조를 곱씹어보며 복습해야겠다.