인공지능 기본 정리
한 줄 정리
| 한 줄 정리 | 비고 | |
|---|---|---|
| PyTorch | 딥러닝 모델을 쉽게 구축할 수 있는 Python기반 라이브러리 | |
| 데이터 전처리 | 데이터 분석 및 학습을 위해 데이터를 정제하고 변환하는 일련의 과정 | 모델의 전반적인 성능을 향상시키고 신뢰할 수 있는 결과를 얻기 위해 사용 |
| 원-핫 인코딩 | 범주형 데이터를 이진벡터로 변환하는 것 | 범주형 데이터간의 불필요한 순서나 크기를 학습하지 않도록 하기 위해 사용 |
| 데이터 증강 | 기존 데이터를 변형하여 새로운 데이터를 생성하는 기법 | 모델이 다양한 형태를 학습하여 과적합을 방지하고 일반화 성능을 높이기 위해 사용 |
| 데이터셋 분할 | 학습할 데이터셋을 training, test, validation 데이터로 나누는 것 | 모델의 학습이 끝난 후 test 데이터셋으로 확인함으로써 과적합을 방지하고 일반화 성능을 높이기 위해 사용 |
| 머신러닝 | 인간의 개입없이 복잡한 문제를 해결하기 위한 알고리즘 | |
| 과적합 | 모델이 training 데이터셋에 너무 잘 학습되어 새로운 데이터에 대한 일반화 성능이 떨어지는 현상 | |
| 딥러닝 | 머신러닝의 하위 개념으로 다층신경망의 유무, 자동으로 최적화가 되느냐 안되느냐 (Back Propagation의 유무) | |
| 퍼셉트론 | 입력값을 weight와 함께 계산한 후 activation function을 이용해 출력하는 ANN의 기본 단위 |
인공지능
TensorFlow
-
딥러닝 및 머신러닝 모델을 구축, 훈련, 배포할 때 많이 사용하는 오픈소스 라이브러리
-
Keras는 파이썬으로 작성된 오픈소스 신경망 라이브러리로 TensorFlow는 자체적으로
tf.keras모듈을 포함하여 공식 고수준 API로 제공하기 시작 -
예제
PyTorch
-
PyTorch는 딥러닝 모델을 쉽게 구축하고 학습할 수 있도록 설계된 파이썬 기반의 오픈소스 딥러닝 라이브러리이다.
직관적인 코딩 스타일과 동적 계산 그래프를 통해 딥러닝 모델의 구축과 디버깅을 용이하게 하고 현재 연구와 실무에서 주로 사용되는 강력한 프레임워크이다. Tensor 데이터 구조를 사용하며 동적 계산 그래프를 통해 유연하고 직관적인 코딩을 지원한다. -
예제
TensorFlow vs. PyTorch
|항목|TensorFlow|PyTorch|
|--|--|--|
|코딩 스타일|선언적(정적 그래프)|명령형(동적 그래프)|
|디버깅|복잡|직관적|
|유연성|낮음|높음|
|학습곡선|가파름|완만함|
|커뮤니티|광범위함|급성장 중|
|배포|강력한 지원|상대적으로 미흡|
Kaggle
-
전 세계 데이터 연구자들이 데이터를 분석할 수 있도록 대회를 개최하고 분석 내용을 토론할 수 있는 커뮤니티를 제공하는 플랫폼
-
API를 만들고 Kaggle에 있는 Datasets을 받아 사용할 수 있다.
# 구글 코랩에서 데이터셋 다운로드 및 준비 from google.colab import files files.upload() # 'kaggle.json' 파일 업로드 !mkdir -p ~/.kaggle !cp kaggle.json ~/.kaggle/ !chmod 600 ~/.kaggle/kaggle.json # Orange Diseases 데이터셋 다운로드 !kaggle datasets download -d sumn2u/riped-and-unriped-tomato-dataset # 압축 해제 !unzip riped-and-unriped-tomato-dataset.zip -d riped-and-unriped-tomato
벡터
-
컴퓨터 그래픽스에서는 벡터가 이미지의 표현 요소로 사용된다. 머신러닝에서는 벡터가 입력 데이터를 표현하는데 사용된다. 각 벡터는 다차원 공간에서 방향과 크기를 가지며 데이터를 수치적으로 표현하는데 사용된다.
-
머신러닝 또는 딥러닝에서 벡터를 사용하는 이유는 데이터를 수치적으로 표현하여 연산과 분석을 쉽게 수행할 수 있기 때문이다.
Data Preprocessing (데이터 전처리)
-
데이터 전처리는 데이터를 분석 및 모델 학습을 위해 원본 데이터를 정제하고 변환하는 과정이다. 데이터 전처리 과정에는 결측값 처리, 이상치 제거, 데이터 정규화, 데이터 변환, 데이터 분할 등이 있다.
-
데이터 전처리는 모델의 성능을 향상시키고 신뢰할 수 있는 예측을 위해 데이터를 정리하고 결측값 처리, 이상치 제거, 스케일링 등의 작업을 통해 데이터를 최적화하기 위해 사용한다.
-
결측값 처리 : 누락된 데이터를 식별하고 적절한 값으로 대체
데이터 수집 과정의 오류, 응답자의 누락, 데이터 통합 문제, 특정시간대 누락 등 -
이상치 제거 : 데이터 내 비정상적인 값들을 식별하고 제거
데이터 입력 오류, 계측기기 오류, 특정 이벤트나 상황 -
데이터 정규화 : 데이터를 일정한 범위로 변환하여 모델 학습을 돕는 과정
데이터 일관성, 알고리즘 성능 -
데이터 변환 : 데이터를 로그 변환, One-Hot 인코딩 등으로 변환
정규분포화, 분산 축소, 비선형 관계 -
스케일링 : 다양한 수치 데이터가 있을 때, 이를 비교, 분석하기 쉽도록 동일한 범위 또는 척도로 변환하는 과정을 의미한다.
예를 들어 한 변 수의 범위가 0 ~ 1이고 다른 변수의 범위가 0 ~ 10,000,000인 경우 두 변수를 동일한 척도로 비교하기 어렵다. 따라서 스케일링을 통해 두 변수의 범위를 동일하게 맞춰줄 수 있다. -
머신러닝에서 데이터 전처리
데이터 수집 $\rightarrow$ 결측값 처리 $\rightarrow$ 이상치 제거 $\rightarrow$ 데이터 정규화 $\rightarrow$ 데이터 변환 $\rightarrow$ 데이터 분할
One-Hot Encoding
-
범주형 데이터를 이진 벡터로 변환하는 기법으로 각 범주형 값은 해당 범주를 나타내는 이진 값이 1이고 나머지는 0인 벡터로 변환하는 과정.
대부분의 머신러닝 알고리즘은 벡터 형태의 입력이 필요로하기 때문에 해당 방식을 많이 사용한다.
예를 들어['사과', '바나나', '딸기']라는 범주형 데이터를 One-Hot 인코딩하면사과 = [1, 0, 0],바나나 = [0, 1, 0],딸기 = [0, 0, 1]로 표현할 수 있다. -
AI에서는 모델이 범주형 변수를 수치형으로 해석하지 못하기 때문에 One-Hot 인코딩을 통해 변환해야한다.
0 John 1 Anna 2 Peter 3 Linda 4 James범주형 데이터를 수치화할 때, 각 카테고리 간의 불필요한 순서나 크기 관계를 학습하지 않도록 하기위해 사용된다.
Data Augmentation (데이터 증강)
- 데이터 증강은 머신러닝을 위해 기존 데이터를 변형하여 새로운 데이터를 생성하는 기법이다. 데이터 증강은 원본 데이터를 단순 복사하는 것이 아니라 회전, 크기 조절, 색상 변화, 노이즈 추가등의 방법을 사용하여 다양한 형태의 데이터를 만드는 것이다.
-
모델 학습에 필요한 데이터의 다양성과 양을 증가시켜 과적합을 방지하고 일반화 성능을 향상시키기 위해서 사용한다.

-
데이터 증강은 다양한 기법을 통해 원본 데이터를 변형할 수 있다.
이미지 회전(Rotation), 이미지 크기 조절(Rescaling), 이미지 뒤집기(Flipping), 색상 변형(Color Jittering), 노이즈 추가(Adding Noise), 역번역(Back-Translation), 속도 변환(Speed Perturbation) -
데이터 증강은 이미지 처리, 음성 인식, 자연어 처리 등의 분야에서 모델의 일반화 성능을 높이는데 널리 사용된다. 하지만 데이터 증강을 통해 생성된 데이터는 원본과 동일하지 않으므로 모델이 실제 데이터 분포를 완전히 학습하는데는 환계가 있을 수 있다.
-
GAN(Generative Adversarial Networks)
- ImageDataGenerator(Tensorflow, Keras)
Dataset Split (데이터셋 분할)
-
주어진 데이터를 목적에 맞게 학습(training), 테스트(test), 검증(validation)으로 분할하여 모델의 성능을 평가하고 일반화하기 위한 과정이다.
- 학습 데이터 : 모델이 패턴을 학습하는데 사용되는 데이터, 모델이 입력 데이터와 출력 데이터 간의 관계를 학습하는 과정에서 사용
- 테스트 데이터 : 학습이 완료된 모델의 최종 성능을 평가하는 데이터, 모델이 한 번도 본 적 없는 데이터로 평가해야 한다.
-
검증 데이터 : 하이퍼 파라미터 튜닝 및 모델 최적화 과정에서 사용되는 데이터, 학습 중 성능 평가를 위한 임시 데이터셋이며 과적합을 방지하는 역할
-
데이터셋 분할은 모델을 학습할 때, 과적합을 방지하고 모델의 성능을 객관적으로 평가하며 실제 데이터를 처리할 때, 모델이 잘 일반화 되는지 확인하기 위해 필요하다. (과적합 방지, 성능 평가, 일반화 확인, 하이퍼파라미터 튜닝, 비교 연구 등)
-
직접 분할 기법
데이터 수집 $\rightarrow$ 학습 데이터 분할 $\rightarrow$ 검증 데이터 분할 $\rightarrow$ 테스트 데이터 분할
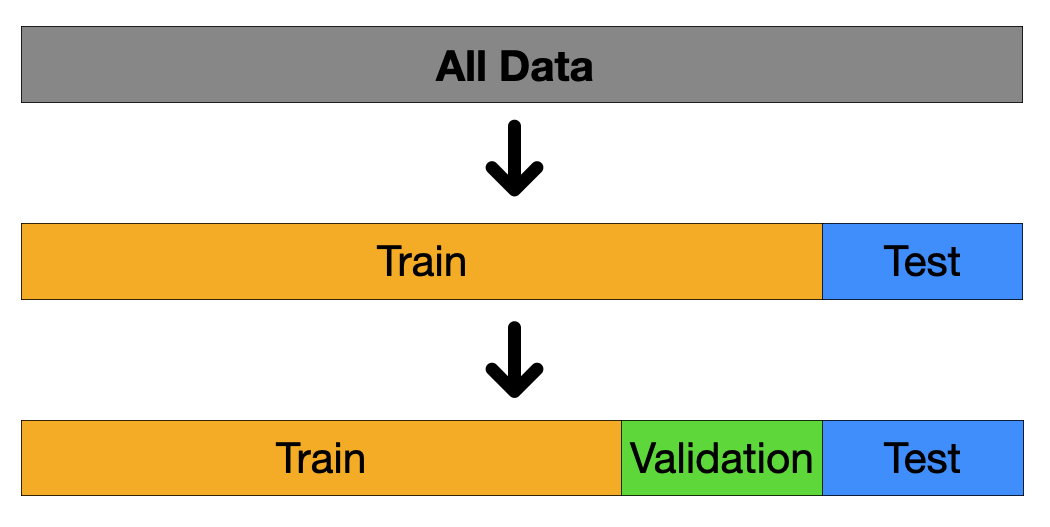
- 랜덤 분할 기법
랜덤 분할 기법에서는train_test_split함수를 사용한다.from sklearn.model_selection import train_test_split train_data, test_data = train_test_split(data, test_size = 0.2, random_state = 1)
Machine Learning (머신러닝)
-
머신러닝은 경험을 통해 자동으로 개선하는 컴퓨터 알고리즘의 연구 분야이다. 즉, ‘컴퓨터가 스스로 하는 학습’을 머신러닝이라고 한다. 머신러닝은 AI의 하위 분야 중 하나로 컴퓨터가 명시적인 프로그래밍 없이도 데이터를 통해 학습하고 예측을 개선하는 자동화 기술을 개발하는 것을 목표로 한다.
-
머신러닝은 데이터로부터 자동으로 학습하고 예측을 개선하여 복잡한 문제를 해결하기 위해서 사용한다. 여기서 자동화는 데이터 분석과 예측 작업을 자동화하여 인간의 개입 없이도 복잡한 문제를 해결할 수 있다. 이는 시간과 비용을 절감하는데 큰 도움이 된다.
-
기존의 인공지능은 규칙 기반 시스템(Rule-Based System)으로 사람이 모든 규칙을 직접 프로그래밍해야 했기 때문에 복잡한 문제를 해결하는데 한계가 있었다. 머신러닝은 이러한 한계를 극복하기 위해 등장하였으며 데이터를 통해 패턴을 학습하고 스스로 예측을 개선하는 방식으로 발전하였다.
-
모델을 학습시키는 과정
데이터 수집 및 전처리 $\rightarrow$ 모델 선택 및 학습 $\rightarrow$ 평가 및 검증 $\rightarrow$ 예측 및 최적화
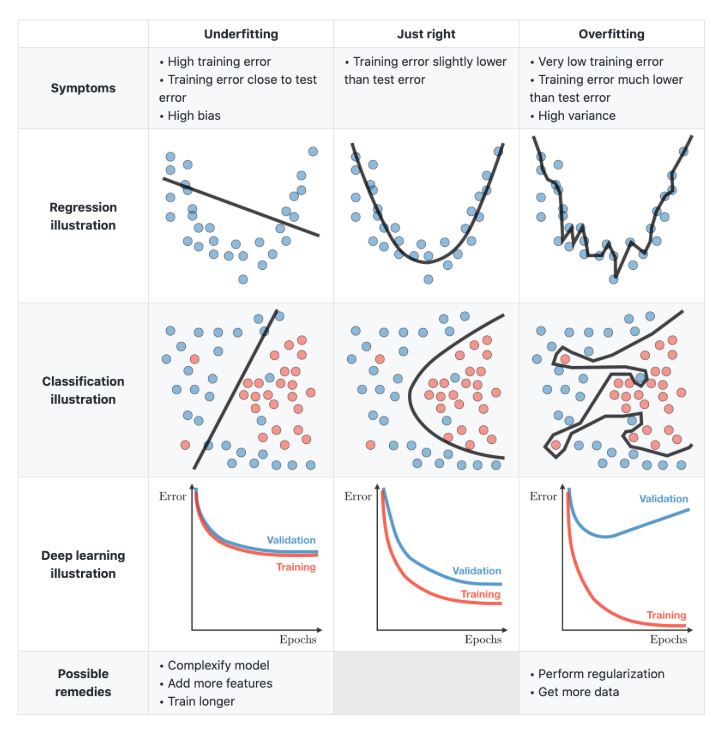
Overfitting(과적합)과 Underfitting(과소적합)
- Overfitting : 모델이 학습 데이터에 너무 잘 맞춰져서 새로운 데이터에 대해 일반화 성능이 떨어지는 현상
- Underfitting : 모델이 학습 데이터의 패턴을 충분히 학습하지 못한 채 지나친 단순화로 성능이 낮은 현상
Deep Learning (딥 러닝)
-
Deep Learning은 대량의 데이터를 기반으로 비선형 모델을 자동으로 만들어주는 기법이다.
-
딥러닝은 복잡한 데이터에서 각각의 특징을 자동으로 학습해 기울기와 가중치를 조정하기 때문에 사용된다. 딥러닝 모델은 자동으로 기울기와 가중치를 선정하여 데이터에서 중요한 패턴과 특징을 찾아낸다.
딥러닝 모델은 예측 정확도가 높고 자동화된 특징을 학습하며 확정성 및 유연성이 높다. -
모델을 학습시키는 과정
데이터 준비 $\rightarrow$ 신경망 모델 설계 $\rightarrow$ 모델 학습 $\rightarrow$ 모델 평가 $\rightarrow$ 모델 최적화 -
하이퍼파라미터
머신러닝 및 딥러닝 모델의 학습 과정에서 개발자가 미리 설정해야하는 변수하이퍼파라미터 정의 Learning Rate 모델이 가중치를 업데이트하는 속도를 결정하는 값 Batch Size 한 번의 학습 단계에서 사용되는 훈련 데이터 샘플의 수 Epochs 전체 훈련 데이터셋을 한 번 학습하는 주기의 수 신경망의 층 수 및 뉴런의 수 신경망의 구조를 결정하는 하이퍼파라미터 Dropout Rate 학습 중 일부 뉴런을 무작위로 제외시키는 비율
Machine Learning vs. Deep Learning
-
비교표
비교향목 머신러닝 딥러닝 특징 추출 수동 자동 데이터 요구량 상대적으로 적음 매우 많음 계산 복잡도 낮음 높음 성능 단순 문제에 강점 복잡한 문제에 강점 유연성 특정 문제에 특화 다양한 문제에 적용 가능 -
딥러닝과 머신러닝의 학습과정을 보면 모델 설계와 훈련 과정에서 차이가 있다. 딥러닝에서는 신경망의 구조(층 수, 뉴런 개수, 활성화 함수 등)가 모델의 성능에 직접적인 영향을 미치므로 설계와 초기화 과정이 매우 중요하다.
Perceptron (퍼셉트론)
-
퍼셉트론은 ANN(Artificial Neural Network)의 기본 단위로 입력값을 weight(가중치)와 함께 처리하여 단일 출력을 생성하는 선형 이진 분류기이다. 단, 다층 퍼셉트론(MLP)에서는 비선형 활성화 함수를 통해 연속적인 값을 출력할 수도 있다.
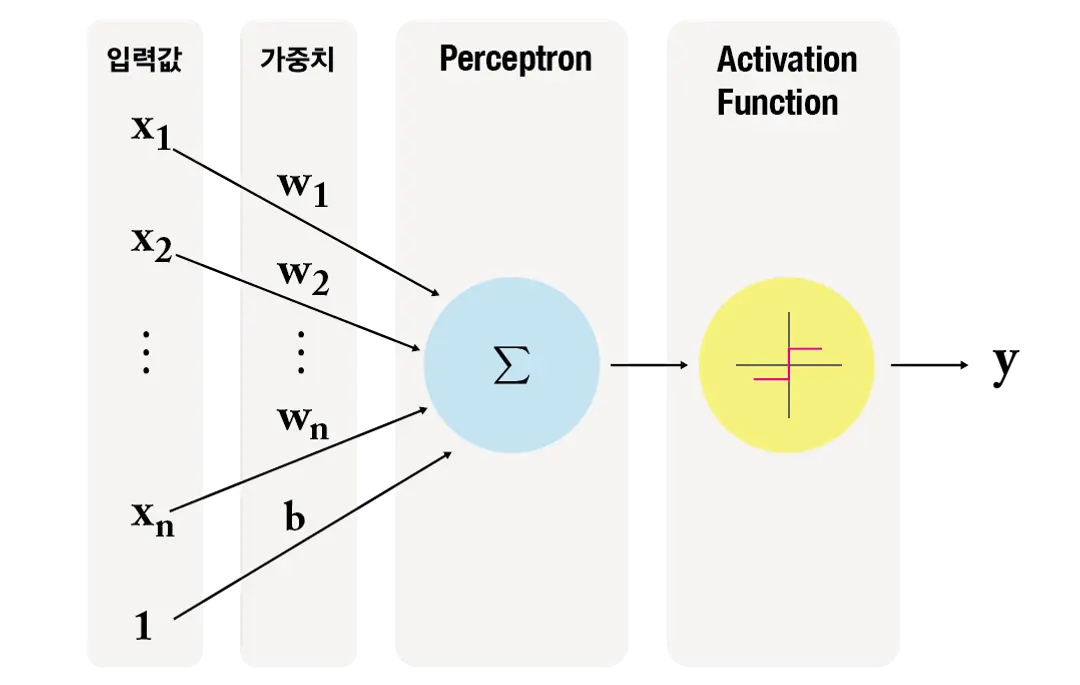
-
활성화 함수
입력값을 특정 기준에 따라 변환하여 출력하는 함수 -
단층 퍼셉트론
단층 퍼셉트론에서는 활성화 함수로 일반적인 계단 함수(Step Function)을 사용한다. 계단 함수는 특정 임계값을 넘으면 1, 넘지 않으면 0을 반환한다. 해당 함수는 선형 결정 경계를 그린다.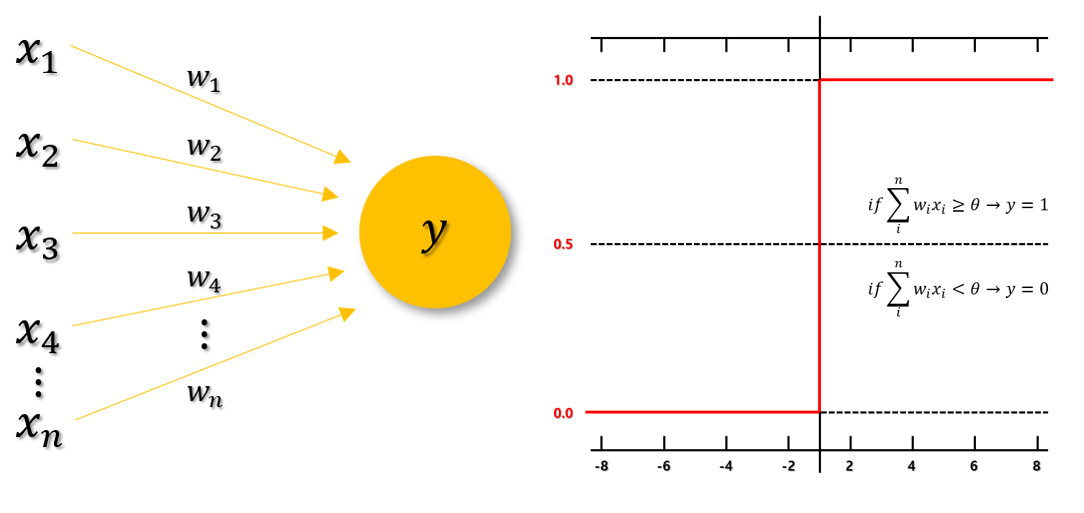
- 단층 퍼셉트론 학습
for epoch in range(epochs): for i in range(len(inputs)): # 총 입력 계산 total_input = np.dot(inputs[i], weights) + bias # 예측 출력 계산 prediction = step_function(total_input) # 오차 계산 error = outputs[i] - prediction # 가중치와 편향 업데이트 weights += learning_rate * error * inputs[i] bias += learning_rate * error수식 표현
\[\begin{aligned} y &= wX + b \\[6pt] f(x) &= \begin{cases} 0 & x < 0 \\ 1 & x \ge 0 \end{cases} \\[6pt] \hat{y} &= f(y) \\[6pt] e &= y - \hat{y} \\[6pt] w_{n+1} &= w_n + \alpha \cdot e \cdot X_n \\[6pt] b_{n+1} &= b_n + \alpha \cdot b_n \end{aligned}\] - 다층 퍼셉트론
다층 퍼셉트론에서는 활성화 함수로 ReLU함수, Sigmoid 계열 함수 등 다양한 함수를 사용한다. 해당 활성화 함수들은 비선형성을 도입하여 비선형 결정 경계를 형성할 수 있다.
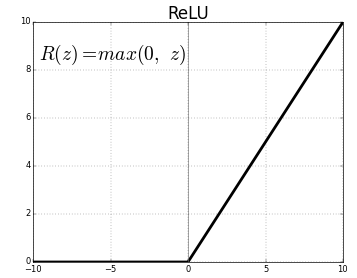
- ReLU -
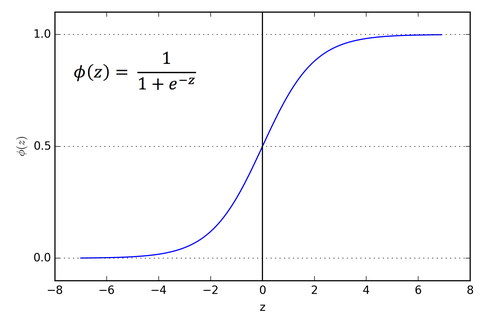
- Sigmoid -
오늘의 회고
-
AI의 기초에 대해 학습하였다. 해당 내용을 가지고 인공지능의 대부분을 응용할 수 있다. 또한 팀원들과 Machine Learning과 Deep Learning의 차이점에 대해 분석하였고 이를 토대로 면접 예상 질문 등을 서로 주고 받았다.
-
Machine Learning의 발전 단계가 Deep Learning이다. 따라서 두 용어를 정확히 잘라내기란 쉽지 않다. 하지만 우리의 결론은 Deep Learning과 Machine Learning의 근본적인 차이는 다층 신경망의 유무와 더불어 Back Propagation으로 자동적으로 최적화가 되느냐에 중점을 둔다면 명확히 구분할 수 있다고 판단하였다.