데이터 시각화 딥다이브
데이터 분석 전에 수행해야 하는 전처리 과정과 데이터 품질을 향상시키는 방법을 설명하시오.
데이터 전처리 과정은 원하는 결과와 분석하고자 하는 데이터의 특징에 따라 달라지며 방법은 무수히 많으며 데이터 특징에 따라 적절한 데이터 전처리 과정이 데이터 품질을 향상시키는 가장 좋은 방법이다.
데이터 분석 수행 과정
- 일반적으로 데이터 분석은 데이터 수집 - 데이터 정제 - 데이터 변환 - 데이터 분석으로 이루어져있다.
- 데이터 정제는 데이터에 있는 결측치와 이상치를 처리하는 과정으로 결측치와 이상치는 데이터에 따라 어떻게 처리할 것 인지 달라진다.
무조건 없애거나 보간하는 것은 좋은 데이터 처리 방법이 아니다. - 데이터 변환은 정제된 데이터를 분석 환경에 맞게 데이터를 변환하는 과정으로 우리가 이전에 배웠던 필터링, 정렬, 그룹화, 피벗, 병합, 분할, 샘플링, 집계 등이 사용된다. 이 또한 데이터 분석에 알맞게 처리해야 한다.
데이터 정제와 변환의 모든 과정이 데이터 전처리라고 할 수 있다.
전처리 과정이 왜 필요한가
- 데이터 전처리는 데이터의 품질을 향상시키기 위한 방법이다. 데이터 품질이 좋지 않다면 분석 결과가 부정확하게 나올 수 있다. 따라서 전처리 과정 자체가 데이터 품질을 향상시키는 방법 중 하나이다.
데이터 전처리
-
결측치 처리
(1) 결측치가 있는 행이 의미가 없다고 판단되는 경우
예) 데이터가 1,000,000개 있는데 결측치가 1 ~ 2개 발생했다면 오히려 보간하는 것보다 삭제하는 것이 데이터 품질을 높일 수 있다.
한국인 대상 설문조사 중 외국인의 설문조사가 끼어 있고 그 설문조사에서 결측치가 발생했다면 삭제하는 것이 더 좋다.(2) 그 외
보간을 해야하는데, 보간은 어떻게 하느냐가 문제이다.
우리가 배운 보간법df.interpolate()
가장 기본적인 것은 Linear Regression : 예측하고자 하는 값이 주변의 값들과 선형관계에 있으면 탁월한 방법
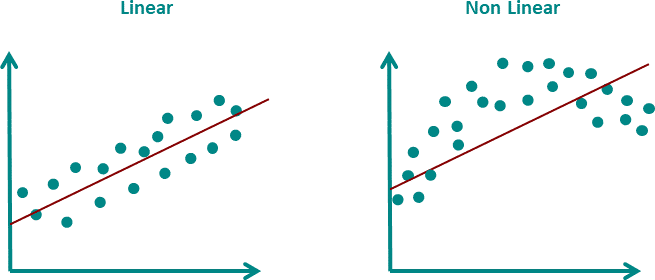
단점 - 세상은 그렇게 만만하지 않다. -
이상치 처리
(1) 이상치가 의미 없다고 판단되는 경우는 삭제
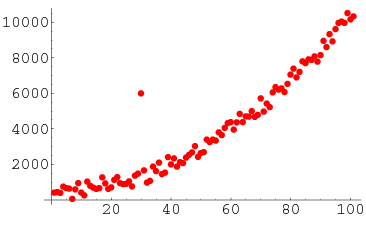
(2) 이상치가 중요한 데이터의 경우
FFT 기법 등을 이용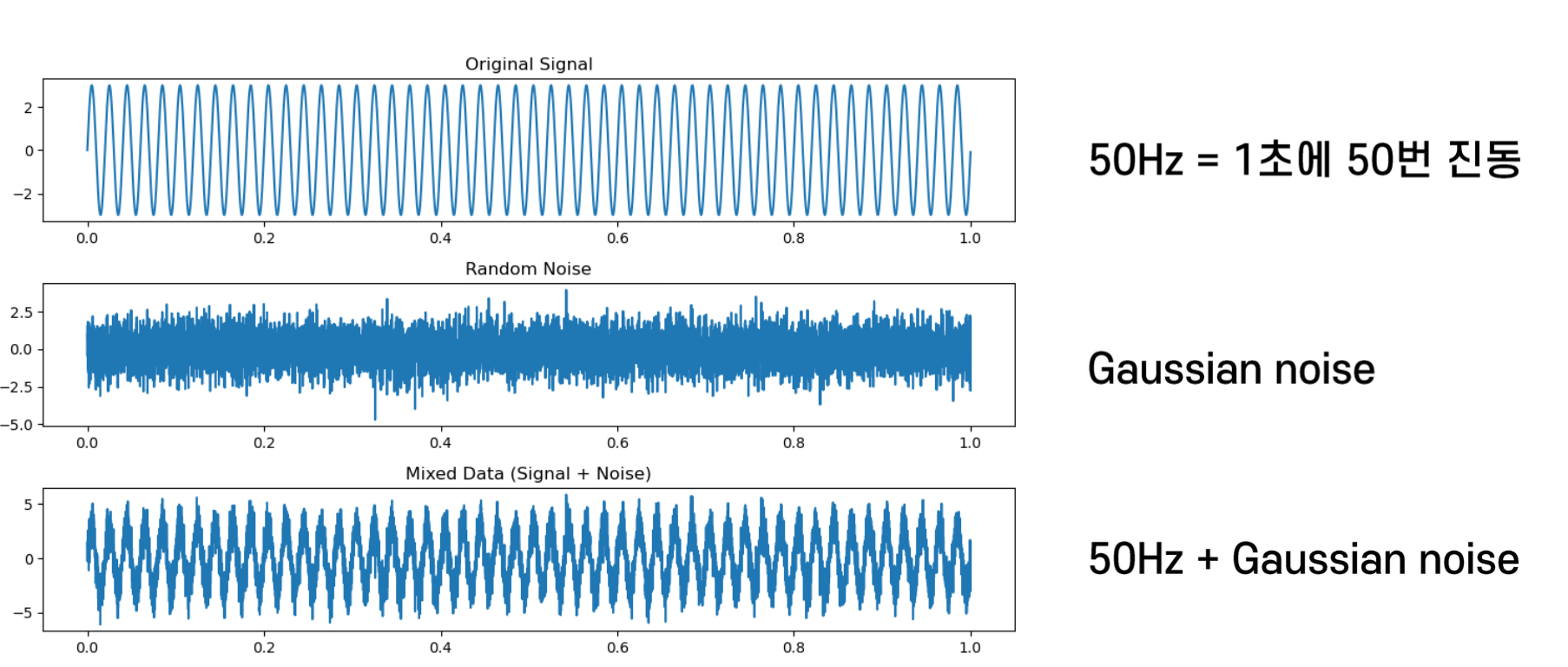
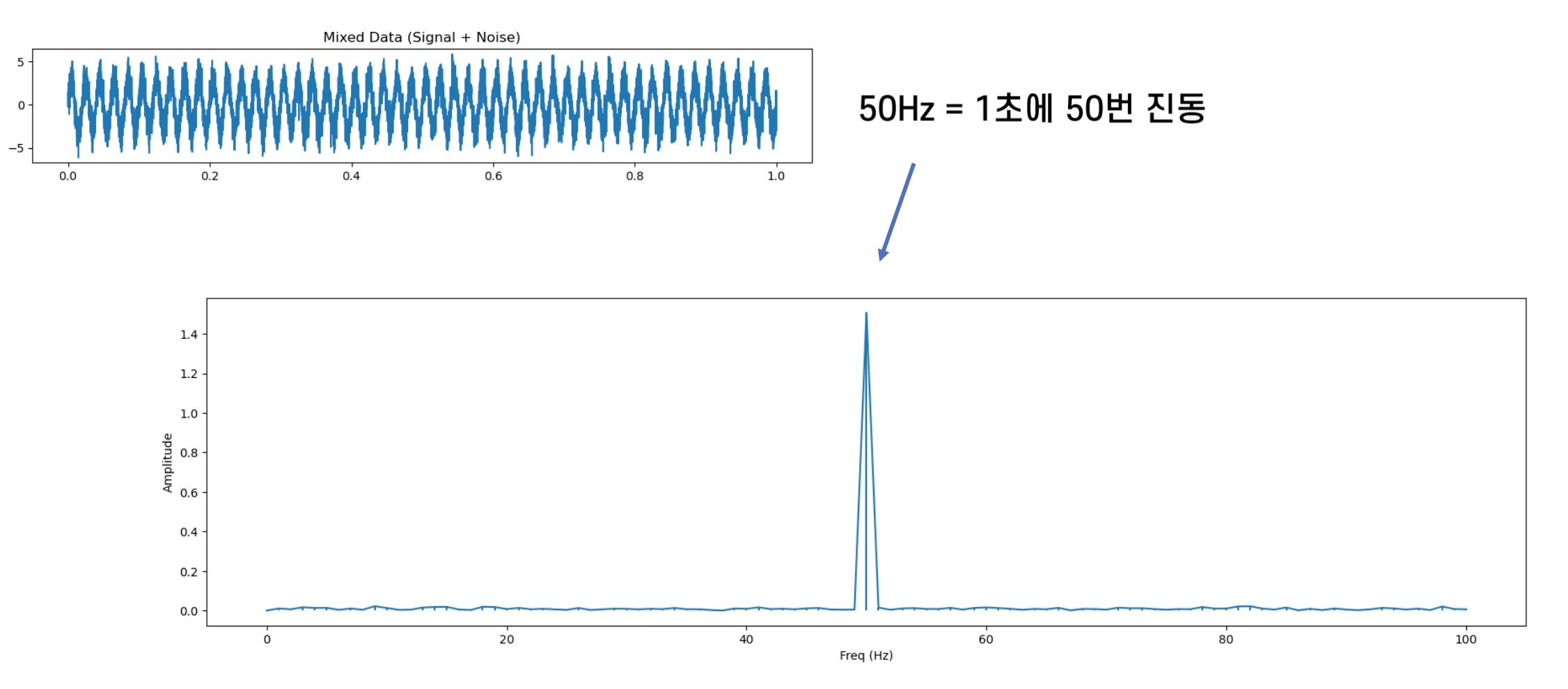
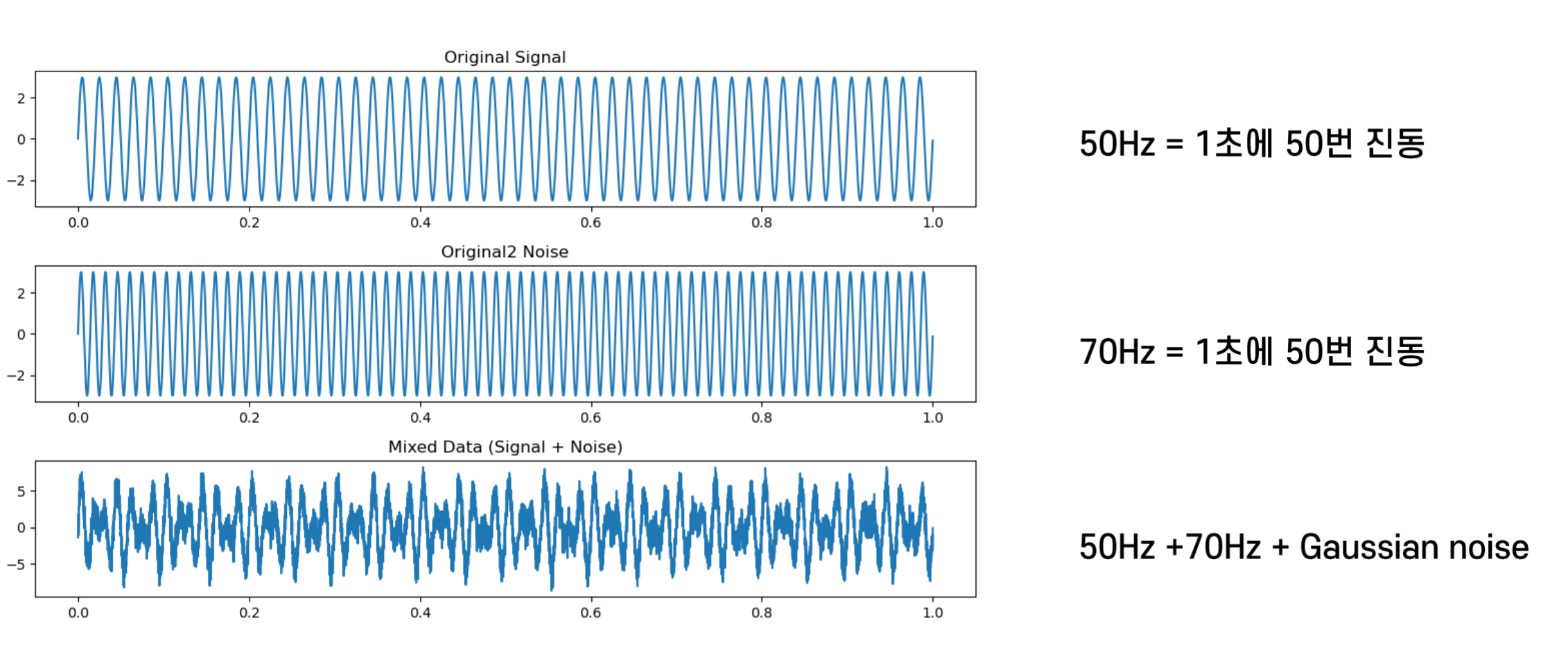
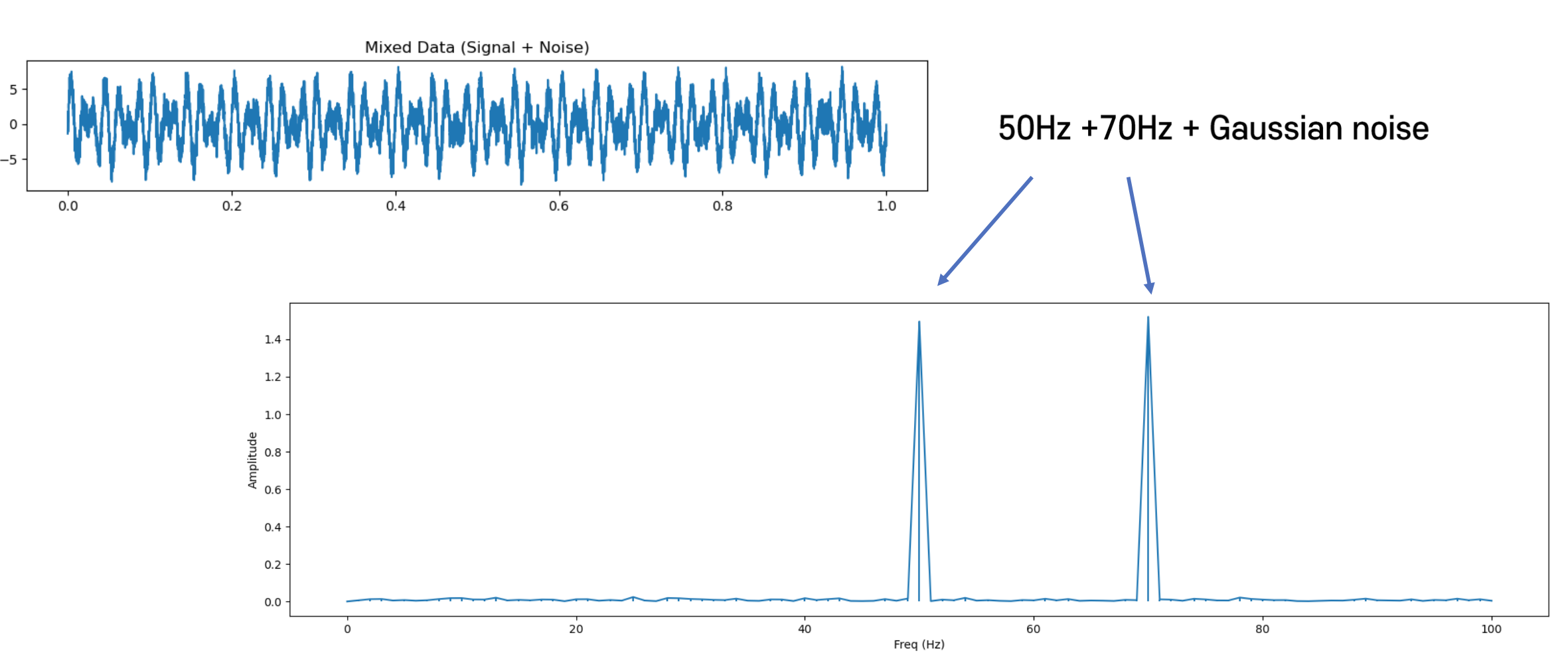
AI를 이용한 모델링
- 데이터 전처리를 할 때, 가장 이상적인 방법은 자연 함수를 모델링하면 된다.
- 대표적인 자연 함수 모델링 : 뉴턴 고전 역학
- 우리가 밈으로 웃고 넘어가는 일명 기영이 차트도 자연적인 현상을 모델링했다고 볼 수 있다.
-
더 나아가 어떤 현상을 $Y = \cdots$ 으로 표현만 할 수 있다면 결측치, 이상치 처리 모두 가능하다. 하지만 이런 모델링 자체가 불가능에 가깝다.
- 위와 같은 자연현상 모델링은 불가능에 가깝기 때문에 AI를 이용한 모델링을 사용한다.
- 대표적인 자연 함수 모델링 : 뉴턴 고전 역학
오늘의 회고
- 딥 다이브를 통해 데이터 전처리에 대해 좀 더 깊이 학습할 수 있었다. 앞으로 학습할 AI 모델링과도 직접적으로 연결되므로 충분한 학습이 필요하다.