3주차 시계열 데이터 Mini Quest
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
시계열 데이터(Time Series Data)
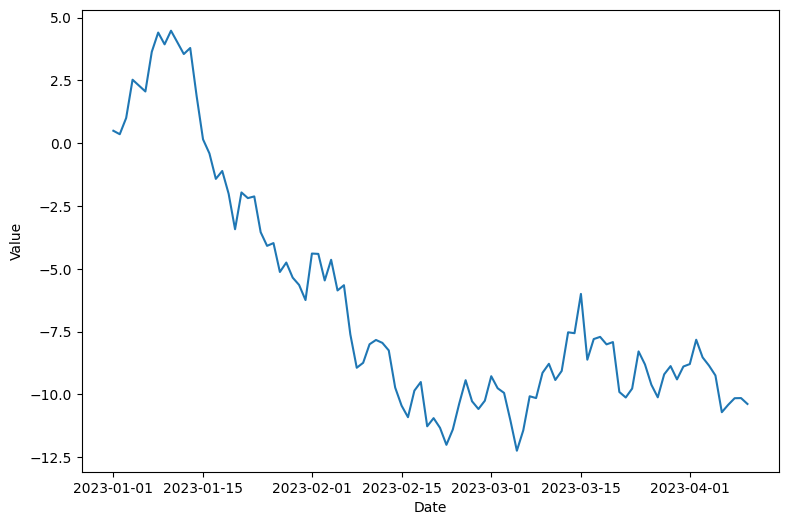
- 100일간의 시계열 데이터를 생성하고 이를 선 그래프로 시각화하는 코드를 작성하세요.
np.random.seed(42)
date_range = pd.date_range(start="2023-01-01", periods=100, freq="D")
values = np.cumsum(np.random.randn(100))
plt.figure(figsize=(9, 6))
plt.plot(date_range, values)
plt.xlabel("Date")
plt.ylabel("Value")
plt.show()
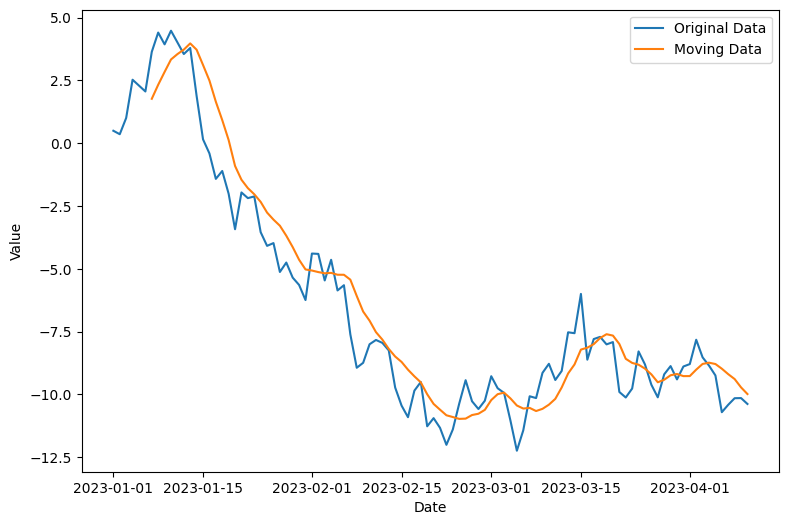
- 1번에서 생성한 데이터를 기반으로 7일 이동 평균을 계산하고 원본 데이터와 함께 그래프로 비교하는 코드를 작성하세요.
np.random.seed(42)
date_range = pd.date_range(start="2023-01-01", periods=100, freq="D")
values = np.cumsum(np.random.randn(100))
plt.figure(figsize=(9, 6))
values_series = pd.Series(values, index=date_range)
rolling = values_series.rolling(window=7).mean()
plt.plot(date_range, values, label="Original Data")
plt.plot(date_range, rolling, label="Moving Data")
plt.xlabel("Date")
plt.ylabel("Value")
plt.legend()
plt.show()
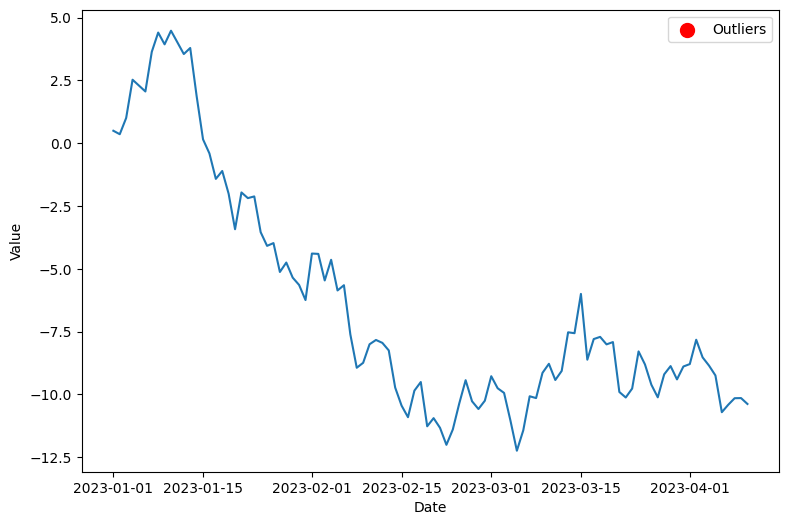
- 1번에서 생성한 시계열 데이터에서 이상치를 탐지하고 이상치만 강조하여 그래프에 표시하는 코드를 작성하세요. 이상치는 사분위수 범위(IQR)를 이용해 판단합니다.
np.random.seed(42)
date_range = pd.date_range(start="2023-01-01", periods=100, freq="D")
values = np.cumsum(np.random.randn(100))
plt.figure(figsize=(9, 6))
plt.plot(date_range, values)
Q1 = np.percentile(values, 25)
Q3 = np.percentile(values, 75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
outliers = values[(values < lower_bound) | (values > upper_bound)]
outliers_dates = date_range[(values < lower_bound) | (values > upper_bound)]
plt.scatter(outliers_dates, outliers, s = 100, color="red", marker = 'o', label="Outliers")
plt.xlabel("Date")
plt.ylabel("Value")
plt.legend()
plt.show()
리샘플링(Resampling)
Pandas를 사용하여 3시간 간격의 시계열 데이터를 생성한 후 하루 단위(D)로 평균을 구하는 다운 샘플링을 수행하는 코드를 작성하세요.
date_rng = pd.date_range(start="2024-01-01", end="2024-01-05", freq="3h")
df = pd.DataFrame({
"datetime": date_rng,
"value": np.random.randn(len(date_rng))
})
df = df.set_index("datetime")
df_d = df.resample("D").mean()
df_d
| value | |
|---|---|
| datetime | |
| 2024-01-01 | -0.084685 |
| 2024-01-02 | 0.108810 |
| 2024-01-03 | 0.071744 |
| 2024-01-04 | -0.083181 |
| 2024-01-05 | -1.062304 |
- 3시간 간격으로 생성된 시계열 데이터에서 1시간 단위로 업 샘플링한 후 선형보간(
linear)을 적용하는 코드를 작성하세요.
date_rng = pd.date_range(start="2024-01-01", end="2024-01-03", freq="3h")
df = pd.DataFrame({
"datetime": date_rng,
"value": np.random.randn(len(date_rng))
})
df = df.set_index("datetime")
df_h = df.resample("H").interpolate(method="linear")
df_h.head()
<ipython-input-30-93838bc24f67>:7: FutureWarning: 'H' is deprecated and will be removed in a future version, please use 'h' instead.
df_h = df.resample("H").interpolate(method="linear")
| value | |
|---|---|
| datetime | |
| 2024-01-01 00:00:00 | 0.250493 |
| 2024-01-01 01:00:00 | 0.282478 |
| 2024-01-01 02:00:00 | 0.314463 |
| 2024-01-01 03:00:00 | 0.346448 |
| 2024-01-01 04:00:00 | 0.004291 |
- 3시간 간격으로 생성된 시계열 데이터에서 하루 단위(
D)로 다운 샘플링을 수행한 후 각 날짜에 해당하는 최소(min)값과 최대(max)값을 출력하는 코드를 작성하세요.
date_rng = pd.date_range(start="2024-01-01", end="2024-01-07", freq="3h")
df = pd.DataFrame({
"datetime": date_rng,
"value": np.random.randn(len(date_rng))
})
df = df.set_index("datetime")
df_d = df.resample("D").agg(["min", "max"])
df_d
| value | ||
|---|---|---|
| min | max | |
| datetime | ||
| 2024-01-01 | -1.792045 | 1.912318 |
| 2024-01-02 | -2.090018 | 1.770432 |
| 2024-01-03 | -0.477382 | 1.357881 |
| 2024-01-04 | -2.037076 | 1.570032 |
| 2024-01-05 | -1.445610 | 1.271138 |
| 2024-01-06 | -0.431942 | 2.275761 |
| 2024-01-07 | 1.200412 | 1.200412 |
이동평균(Moving Average)
- 주어진 시계열 데이터에서 7일 단순 이동평균(SMA)을 계산하여 새로운 컬럼을 추가하는 코드를 작성하세요.
date_rng = pd.date_range(start="2024-01-01", end="2024-01-20", freq="D")
df = pd.DataFrame({
"datetime": date_rng,
"value": np.random.randint(50, 150, size=len(date_rng))
})
df = df.set_index("datetime")
df['SMA'] = df['value'].rolling(window=7).mean()
df
| value | SMA | |
|---|---|---|
| datetime | ||
| 2024-01-01 | 64 | NaN |
| 2024-01-02 | 103 | NaN |
| 2024-01-03 | 109 | NaN |
| 2024-01-04 | 146 | NaN |
| 2024-01-05 | 57 | NaN |
| 2024-01-06 | 102 | NaN |
| 2024-01-07 | 109 | 98.571429 |
| 2024-01-08 | 54 | 97.142857 |
| 2024-01-09 | 117 | 99.142857 |
| 2024-01-10 | 55 | 91.428571 |
| 2024-01-11 | 145 | 91.285714 |
| 2024-01-12 | 143 | 103.571429 |
| 2024-01-13 | 96 | 102.714286 |
| 2024-01-14 | 148 | 108.285714 |
| 2024-01-15 | 104 | 115.428571 |
| 2024-01-16 | 89 | 111.428571 |
| 2024-01-17 | 101 | 118.000000 |
| 2024-01-18 | 65 | 106.571429 |
| 2024-01-19 | 62 | 95.000000 |
| 2024-01-20 | 79 | 92.571429 |
- 시계열 데이터에서 7일 지수 이동평균(EMA)을 계산하고 기존 데이터와 비교하여 출력하는 코드를 작성하세요.
date_rng = pd.date_range(start="2024-01-01", end="2024-01-20", freq="D")
df = pd.DataFrame({
"datetime": date_rng,
"value": np.random.randint(50, 150, size=len(date_rng))
})
df = df.set_index("datetime")
df['EMA'] = df['value'].ewm(span=7).mean()
df
| value | EMA | |
|---|---|---|
| datetime | ||
| 2024-01-01 | 68 | 68.000000 |
| 2024-01-02 | 66 | 66.857143 |
| 2024-01-03 | 112 | 86.378378 |
| 2024-01-04 | 68 | 79.657143 |
| 2024-01-05 | 141 | 99.764405 |
| 2024-01-06 | 107 | 101.964954 |
| 2024-01-07 | 104 | 102.552088 |
| 2024-01-08 | 139 | 112.677779 |
| 2024-01-09 | 139 | 119.792544 |
| 2024-01-10 | 111 | 117.463236 |
| 2024-01-11 | 72 | 105.596222 |
| 2024-01-12 | 58 | 93.307918 |
| 2024-01-13 | 61 | 85.034382 |
| 2024-01-14 | 50 | 76.116895 |
| 2024-01-15 | 107 | 83.942245 |
| 2024-01-16 | 50 | 75.370775 |
| 2024-01-17 | 83 | 77.292527 |
| 2024-01-18 | 145 | 94.315365 |
| 2024-01-19 | 97 | 94.989374 |
| 2024-01-20 | 138 | 105.776238 |
- 주어진 시계열 데이터에서 이동평균을 활용하여 변동성이 큰 날을 탐색하는 코드를 작성하세요. 7일 단순 이동평균(SMA)과 비교하여 특정 일자의 값이 이동평균보다 $\pm$ 20% 이상 차이가 나는 경우만 출력하세요.
date_rng = pd.date_range(start="2024-01-01", end="2024-01-20", freq="D")
df = pd.DataFrame({
"datetime": date_rng,
"value": np.random.randint(50, 150, size=len(date_rng))
})
df = df.set_index("datetime")
df['SMA'] = df['value'].rolling(window=7).mean()
result = df[(df['value'] - df['SMA']).abs() > 0.2 * df['SMA']]
result
| value | SMA | |
|---|---|---|
| datetime | ||
| 2024-01-07 | 71 | 91.285714 |
| 2024-01-08 | 142 | 104.428571 |
| 2024-01-11 | 75 | 108.428571 |
| 2024-01-12 | 65 | 101.714286 |
| 2024-01-14 | 135 | 108.285714 |
| 2024-01-16 | 78 | 97.714286 |
| 2024-01-17 | 127 | 98.000000 |
| 2024-01-18 | 141 | 107.428571 |
금융 데이터(Financial Data)
- 샘플 금융 데이터프레임을 직접 생성한 후 데이터의 기분 정보(행 개수, 열 개수, 데이터 타입 등)를 출력하는 코드를 작성하세요.
data = {
'Date': pd.date_range(start='2024-01-01', periods=10, freq='D'),
'Open': [100, 102, 105, 103, 108, 107, 110, 112, 115, 118],
'High': [102, 106, 108, 107, 110, 109, 112, 115, 117, 120],
'Low': [98, 100, 103, 101, 106, 105, 108, 110, 113, 116],
'Close': [101, 104, 106, 105, 109, 108, 111, 113, 116, 119],
'Volume': [1000, 1200, 1500, 1300, 1600, 1400, 1700, 1800, 1900, 2000]
}
df = pd.DataFrame(data)
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 10 entries, 0 to 9
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Date 10 non-null datetime64[ns]
1 Open 10 non-null int64
2 High 10 non-null int64
3 Low 10 non-null int64
4 Close 10 non-null int64
5 Volume 10 non-null int64
dtypes: datetime64[ns](1), int64(5)
memory usage: 612.0 bytes
- 주어진
df데이터프레임에서 5일 이동평균(SMA)과 5일 지수 이동평균(EMA)을 계산하는 코드를 작성하세요.
data = {
'Date': pd.date_range(start='2024-01-01', periods=10, freq='D'),
'Close': [101, 104, 106, 105, 109, 108, 111, 113, 116, 119]
}
df = pd.DataFrame(data)
df['SMA'] = df['Close'].rolling(window=5).mean()
df['EMA'] = df['Close'].ewm(span=5).mean()
df
| Date | Close | SMA | EMA | |
|---|---|---|---|---|
| 0 | 2024-01-01 | 101 | NaN | 101.000000 |
| 1 | 2024-01-02 | 104 | NaN | 102.800000 |
| 2 | 2024-01-03 | 106 | NaN | 104.315789 |
| 3 | 2024-01-04 | 105 | NaN | 104.600000 |
| 4 | 2024-01-05 | 109 | 105.0 | 106.289100 |
| 5 | 2024-01-06 | 108 | 106.4 | 106.914286 |
| 6 | 2024-01-07 | 111 | 107.8 | 108.360855 |
| 7 | 2024-01-08 | 113 | 109.2 | 109.970024 |
| 8 | 2024-01-09 | 116 | 111.4 | 112.033697 |
| 9 | 2024-01-10 | 119 | 113.4 | 114.396777 |
df데이터프레임에서 주간(7일) 단위로 종가(Close) 평균을 리샘플링 한 후 이를 바탕으로 주간 변동성(표준편차)을 계산하는 코드를 작성하세요.
date_rng = pd.date_range(start='2024-01-01', periods=30, freq='D')
close_prices = np.random.uniform(100, 200, size=len(date_rng))
df = pd.DataFrame({
'Date': date_rng,
'Close': close_prices
})
df = df.set_index('Date')
weekly_df = df.resample('W').agg(Weekly_std=('Close', 'std'))
weekly_df
| Weekly_std | |
|---|---|
| Date | |
| 2024-01-07 | 29.527025 |
| 2024-01-14 | 21.552952 |
| 2024-01-21 | 28.471306 |
| 2024-01-28 | 27.804352 |
| 2024-02-04 | 27.990682 |