CNN
한 줄 정리
| 한 줄 정리 | 비고 | |
|---|---|---|
| FCNN | 모든 노드들이 이전 노드들과 연결된 신경망 구조 | |
| 역전파 | 순전파의 반대 방향으로 Gradient를 계산하는 과정 | |
| 옵티마이저 | Loss Function의 최소값을 찾아가는 알고리즘 | |
| 기울기 소실 | 역전파를 통해 계산한 기울기를 곱하다보면 gradient 값이 너무 작아 0으로 수렴하는 것 | |
| Adam | 딥러닝에서 널리 사용되는 optimizer로 학습 과정에서 파라미터를 자동으로 조정한다는 특징이 있다. | |
| CNN | 합성곱 인공 신경망으로 2D tensor 이상의 입력 데이터에서 특징을 추출하는데 용이하다. | |
| 합성곱 계층 | CNN에서 filter를 사용해 입력 데이터의 특징을 추출하는 계층이다. | |
| 풀링 계층 | 합성곱 계층에서 나온 주요 특징을 압축하는 과정이다. |
딥러닝
Activation Function(비선형 활성화 함수)
-
인공신경망에서 뉴런의 출력을 결정하는 비선형 함수이다.
-
$f =$ weighted sum, $g = $ activation function
$h(x) = f(g(x))$
$h’(x) = f’(g(x))\cdot g’(x)$
노드가 입력신호를 받아 가중합을 계산한 후 이를 비선형 함수에 적용하여 최종 출력을 생성하는 역할
Sigmoid(시그모이드)
-
시그모이드 함수는 모든 입력 값을 0과 1 사이로 매핑하는 S자 형태의 함수이다.
-
$\sigma(x) = \frac{1}{1+e^{-x}}$
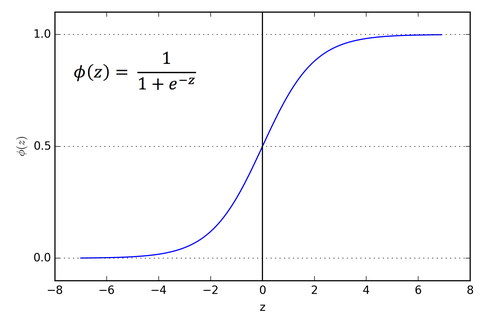
Hyperbolic Tangent, tanh(하이퍼볼릭 탄젠트)
-
시그모이드 함수와 유사한 S자 형태의 함수로 모든 입력 값을 -1과 1사이로 매핑한다.
\(\tanh(x) = \frac{\sinh(x)}{\cosh(x)} = \frac{e^x-e^{-x}}{e^x+e^{-x}} = \frac{e^{2x}-1}{e^{2x}+1}\)
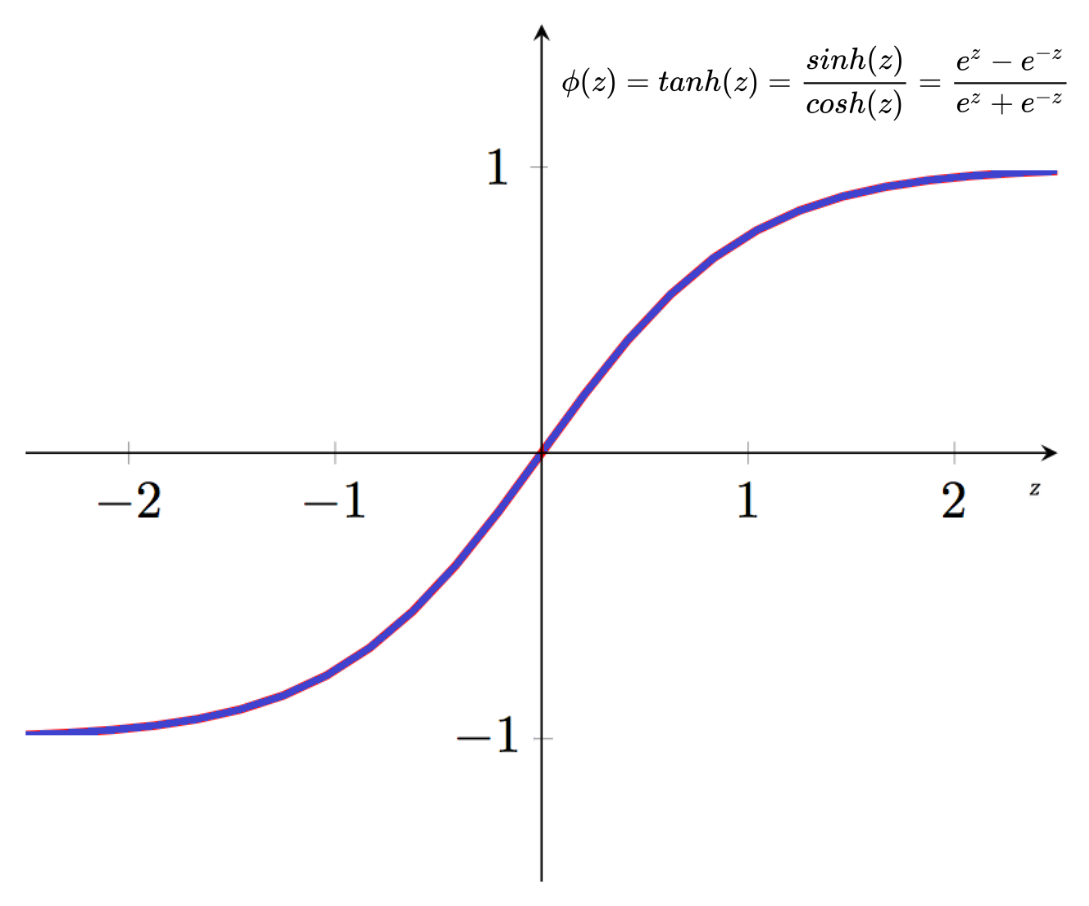
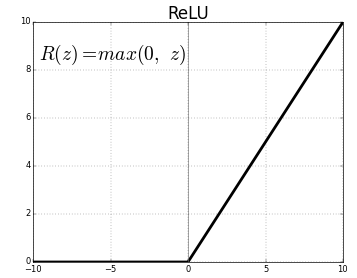
Rectified Linear Unit, ReLU(렐루)
-
“고르게 한다.”는 뜻의 Rectified와 “직선” Linear로 결합된 힘수로 입력이 0 보다 작으면 0이 출력되고 입력이 0 이상이면 출력이 입력과 동일해지는 함수이다.
-
$ReLU(x) = Max (0, x)$
Artificial Neural Network(인공 신경망)
-
인공신경망은 머신러닝과 인지 과학에서 사용되어 패턴 인식과 문제 해결 능력을 갖구헤나는 뇌의 뉴런 네트워크를 모방한 알고리즘이다.
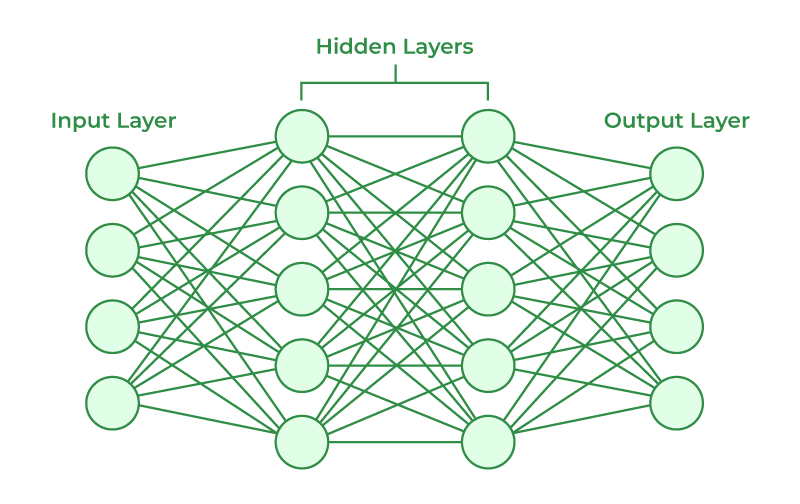
-
ANN의 기본 동작 구조
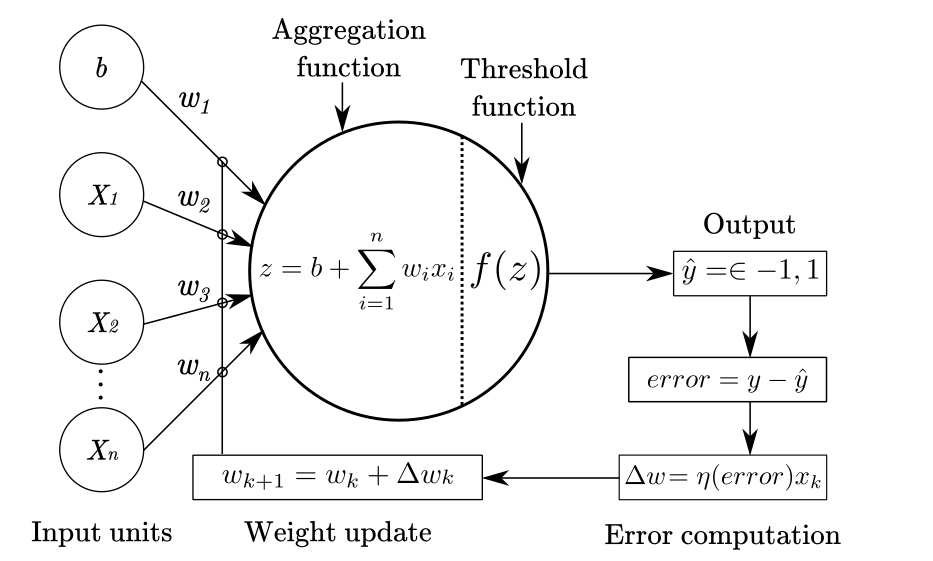
-
Feed-Forward(순방향 전파)
인공신경망에서 입력 데이터를 출력으로 변환하는 과정을 말한다. 입력 데이터를 받아서 은닉층과 출력층을 거쳐 출력을 생성하는 과정을 포함한다. -
Loss Function(손실 함수)
출력층에서 예측된 출력값과 실제 정답을 비교하여 손실(Loss)값을 계산한다.
$|Y - \hat Y|$ -
Backpropagation(오차 역전파)
계산된 손실 값을 기반으로 손실을 줄이기 위해 각 가중치에 대한 기울기를 계산한다. 이 과정은 출력 방향의 역방향으로 진행되며 각 층의 가중치에 대한 기울기를 계산한다.
Fully Connected Neural Network(완전 연결 신경망)
- FCNN은 모든 뉴런이 이전 층의 모든 뉴런과 연결된 신경망 구조이다. 입력 데이터의 모든 특징을 활용하여 복잡한 패턴을 학습하고 예측하는데 효과적이다.
- 라이브러리
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
import numpy as np
- 데이터 준비
input_dim = 20
num_classes = 10
X_train = np.random.rand(1000, input_dim).astype(np.float32)
y_train = np.random.randint(num_classes, size=1000).astype(np.int64)
X_test = np.random.rand(200, input_dim).astype(np.float32)
y_test = np.random.randint(num_classes, size=200).astype(np.int64)
train_dataset = TensorDataset(torch.tensor(X_train), torch.tensor(y_train))
test_dataset = TensorDataset(torch.tensor(X_test), torch.tensor(y_test))
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)
- 모델 정의
class FCNN(nn.Module):
def __init__(self, input_dim, num_classes):
super(FCNN, self).__init__()
self.fc1 = nn.Linear(input_dim, 64)
self.fc2 = nn.Linear(64, 64)
self.fc3 = nn.Linear(64, num_classes)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = self.fc3(x)
return x
model = FCNN(input_dim, num_classes)
- Loss Function & Optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
- Model Train
num_epochs = 20
for epoch in range(num_epochs):
model.train()
for inputs, labels in train_loader:
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
print(f"Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}")
- Evaluation & Predict
model.eval()
correct = 0
total = 0
with torch.no_grad():
for inputs, labels in test_loader:
outputs = model(inputs)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = 100 * correct / total
print(f"Test Accuracy: {accuracy:.2f}%")
sample_input = torch.tensor(X_test[:5])
predictions = model(sample_input)
_, predicted_classes = torch.max(predictions, 1)
print("Predicted classes: ", predicted_classes.numpy())
print("True classes: ", y_test[:5])
Fully Connected Layer(완전 연결 계층)
- 인공 신경망에서 모든 입력 뉴런이 모든 출력 뉴런과 연결된 레이어로 Hidden Layer와 Output Layer가 Fully Connected Layer 부분이라고 생각할 수 있다. 이러한 구조는 데이터의 모든 특징을 종합적으로 분석하고 학습하는데 중요한 역할을 한다.
Loss Function(손실 함수)
-
손실 함수는 인공신경망이나 기타 머신러닝 모델에서 예측갑과 실제 값 간의 차이를 정량적으로 측정하는 함수이다. 손실함수는 모델이 얼마나 정확한 예측을 하고 있는지를 평가하는데 사용되며 예측 오차를 최소화하는 방향으로 모델을 학습시키기 위한 중요한 역할을 한다.
-
손실 함수의 종류
- 회귀(Regression) 문제
-
평균제곱오차(MSE, Mean Squared Error)
예측 값과 실제 값의 차이를 제곱한 후 평균을 구하는 손실 함수, 오차가 클 수록 영향이 크다. -
평균절대오차(MAE)
예측 값과 실제 값의 차이의 절대값을 평균 내는 손실 함수 이다. 단순히 예측이 실제 값에서 얼마나 벗어났는지를 평균으로 평가
-
- 분류(Classification) 문제
-
Cross-Entropy Loss (크로스 엔트로피 손실)
확률 분포 간 차이를 측정하며 분류 문제에서 예측 확률과 실제 정답 간의 차이를 최소화하는 손실 함수이다. 모델이 정답을 맞출 확률이 높을수록 손실이 작아지고 틀릴 확률이 높을수록 손실이 커진다. -
Hinge Loss (힌지 손실)
주로 Support Vector Machine에서 사용되는 손실 함수로 정답과 예측 값 사이의 마진을 기반으로 손실을 계산한다.
-
- 회귀(Regression) 문제
Backpropagation(오차 역전파)
-
Neural Network에서 출력값과 실제값 간의 오차를 기분으로 각 뉴런의 weight를 조정하기 위해 사용하는 알고리즘이다.
-
Backpropagation은 Loss Function에 대한 가중치의 기울기(Gradient)를 계산하는 과정이다. 실제 가중치를 조정하는 것은 Optimizer의 역할이다.
-
Backpropagation에서 Gradient를 계산하기 위해 Chain Rule를 이용한다.
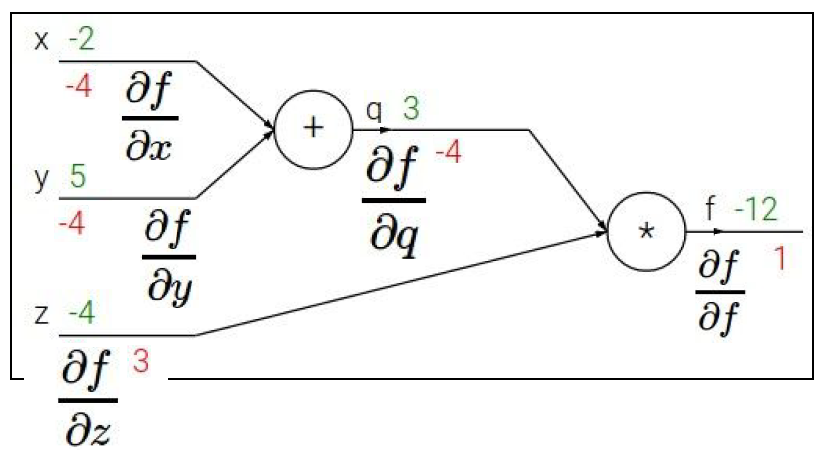
Optimizer(옵티마이저)
-
딥러닝 모델의 손실 함수를 최소화하기 위해 기울기를 기반으로 가중치를 업데이트 하는 알고리즘으로 손실함수를 최소화하도록 가중치를 조정하기 위해 사용한다.
-
Gradient Descent : 가장 기본적인 옵티마이저로 딥러닝 모델의 학습 과정에서 손실 함수를 최소화하기 위해 사용되는 대표적인 알고리즘이다.
ex. Batch Gradient Descent, Stochastic Gradient Descent, Mini-batch Gradient Descent -
Adaptive Optimizers : 학습률을 동적으로 조정하여 학습 효율을 높여주는 옵티마이저이다.
ex. Adagrad, RMSprop, Adam(Adaptive Moment Estimation) -
Momentum Optimizers : 기울기 벡터의 지수 이동평균을 사용하여 가중치를 업데이트한다. 지수 이동 평균은 기울기 벡터의 변동성을 줄여주기 때문에 SGD의 단점을 보완할 수 있다. ex. NAG(Mesterov Acceleated Gradient)
-
Pytorch에서 옵티마이저 선택
# SGD 옵티마이저 선택 및 학습률 설정 optimizer = optim.SGD(model.parameters(), lr=0.01) # Adam 옵티마이저 사용 예시 optimizer = optim.Adam(model.parameters(), lr=0.001)
Gradient Descent
- Gradient Descent는 머신러닝과 딥러닝에서 손실 함수를 최소화하기 위해 가중치를 반복적으로 조정하는 최적화 알고리즘
기울기 소실(Vanishing Gradient)
-
Activation Function의 기울기 값이 계속 곱해지다 보면 weight에 따른 결과값의 기울기가 0에 가까워져 weight를 변경할 수 없게 되는 현상을 말한다.
-
주로 Sigmoid 계열 활성화 함수에서 주로 발생하며 신경망의 학습을 어렵게 만든다. ReLU 함수는 이 문제를 일부 완화하지만 음수 영역에서는 뉴런이 죽어버리는 현상을 야기한다.
Adam(Adaptive Moment Estimation)
-
딥러닝에서 널리 사용되는 최적화 알고리즘으로 학습 과정에서 파라미터의 학습률을 자동으로 조정하여 효과적인 학습을 가능하게 한다.
-
Adam은 학습 속도가 빠르고 메모리 효율적이며 다양한 문제에 대해 안정적인 성능을 보여주기 때문에 사용한다. 기존 옵티마이저(SGD, Momentum, RMSprop)의 단점을 보완하면서도 자동으로 학습률을 조정하여 호과적인 학습이 가능하다.
Convolutional Neural Network, CNN (합성곱 인공신경망)
- 여러 개의 Convolutional Layer, Pooling Layer, Fully Connected Layer들로 구성된 신경망이다.
Convolution(합성곱)
-
두 함수 $f$와 $g$에 대해서 $fg$로 표현한다.
$(fg)(t) = \int f(\tau)g(t-\tau) d\tau$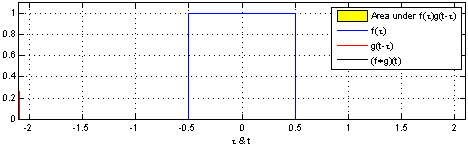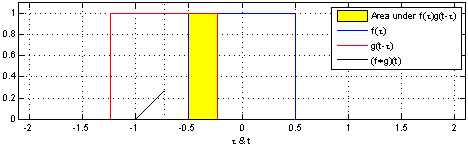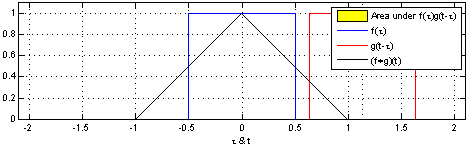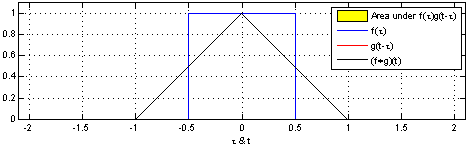
출처: WIKIpedia
{kind=link}
Convolutional Layer(합성곱 계층)
- Convolutional Layer는 CNN에서의 입력 데이터의 특징을 추출하는 레이어이다. 입력 데이터에 Convolutional Mask(필터/커널)을 적용하고 활성화 함수를 반영하여 특징을 추출하는 레이어이다.
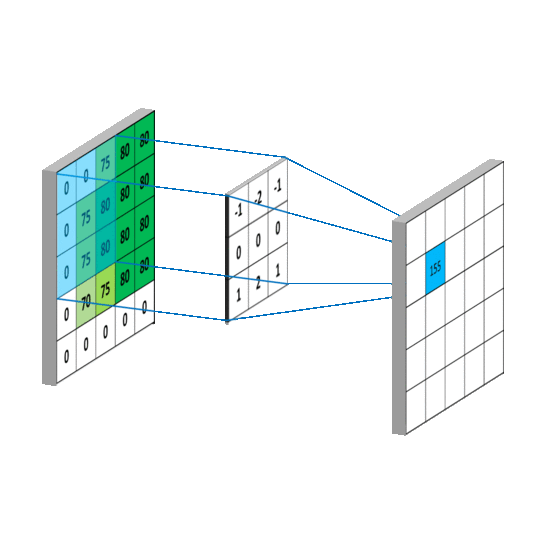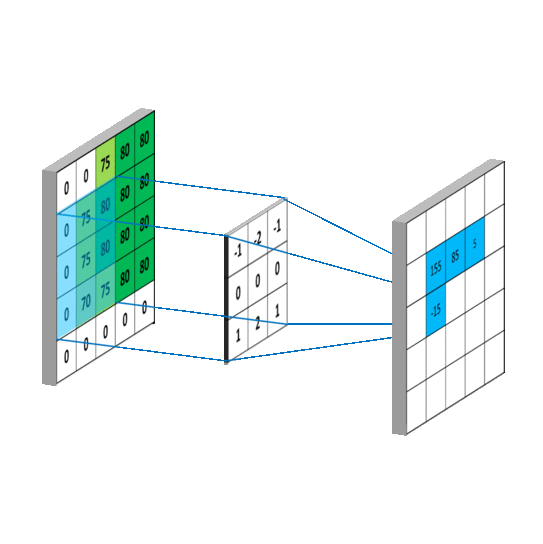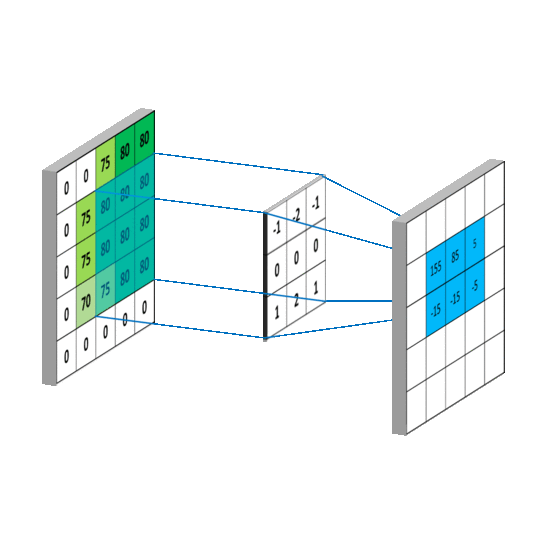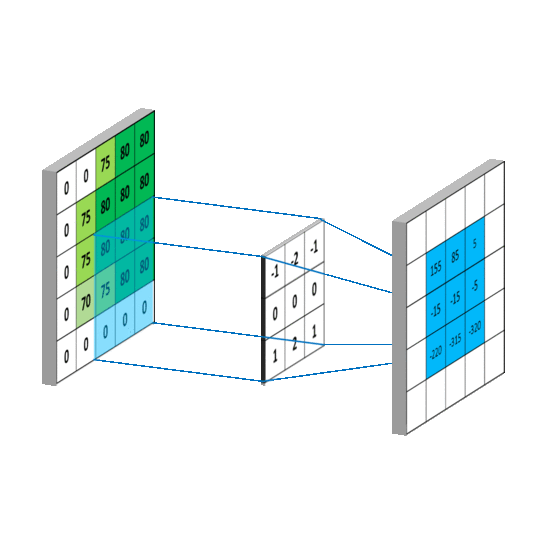
Pooling Layer(풀링 계층)
-
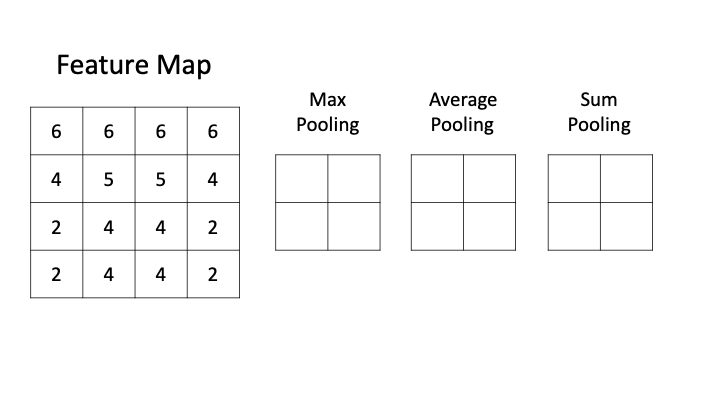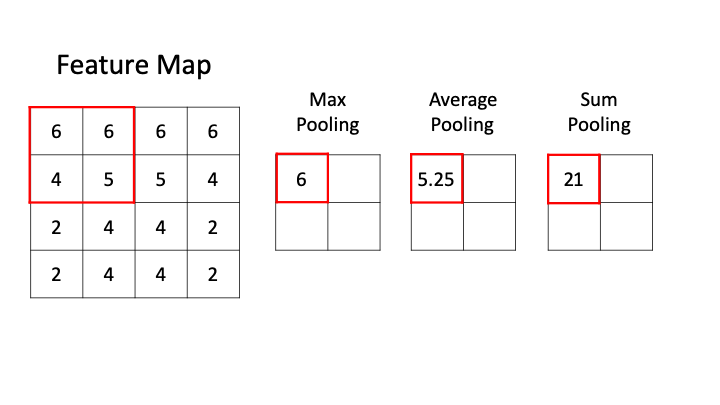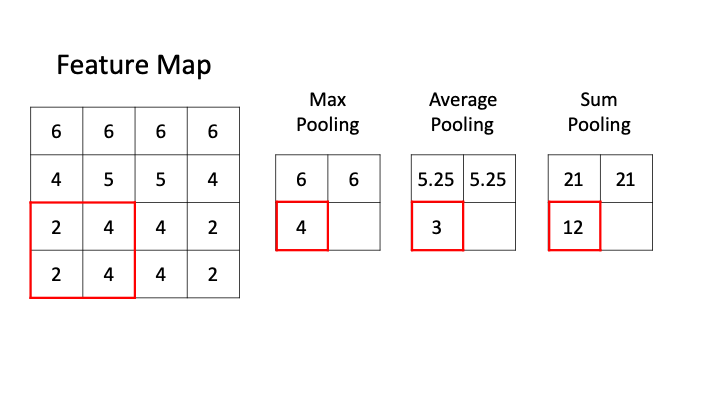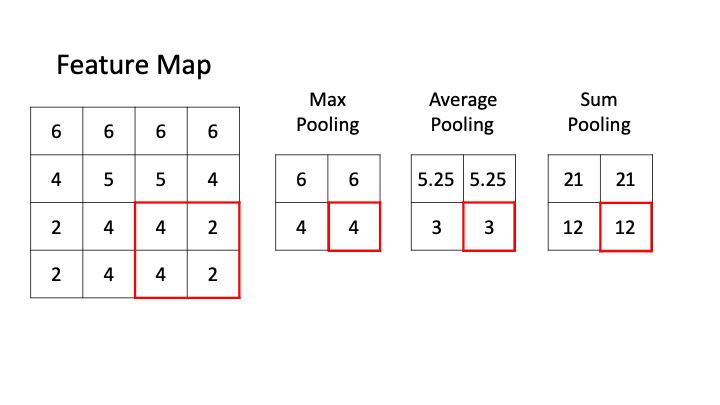
Pooling Layer는 Convolution Neural Network에서 입력 특징 맵의 공간 크기를 줄여 계산량을 감소시키고 중요한 특징을 추출하며 과적합을 방지하는 역하을 하는 레이어이다.
일반적으로 Pooling은 feature map의 크기를 줄이고 중요한 정보를 추려내는데 활용되는 연산이다.
-
Max Pooling : Pooling 영역 내에서 가장 큰 값 하나를 골라 대표값으로 삼는 방법으로 이미지나 feature map에서 뚜렷하게나타나는 패턴을 강조하는데 유리하며 작은 노이즈나 위치 변동의 영향을 줄일 수 있다.
-
Average Pooling : Pooling 영역 내의 모든 값을 더해 평균을 내는 방식이다. 구역 전체의 통계적 특성을 고르게 반영할 수 있고 극단적으로 큰 값이 존재하더라도 이를 완화해 전체 분포를 안정적으로 유지한다.
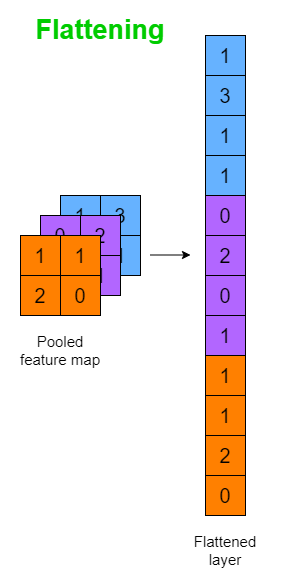
Flatten Layer(평탄화 계층)
- Flatten Layer는 다차원 배열 형태의 입력 데이터를 1차원 배열로 변환하여 주로 Fully Connected Layer에 입력으로 사용할 수 있도록 하는 신경망 레이어이다.
오늘의 회고
- CNN을 중점으로 딥러닝을 학습하였다.