Data 시각화
한 줄 정리
| 한 줄 정리 | 비고 | |
|---|---|---|
| 시각화 | 데이터를 그래프, 히스토그램 등을 사용하여 직관적으로 이해하기 쉽게 표현한 것 | |
| 정형 데이터 | 행과 열로 표현되어 데이터를 메타 데이터 등으로 구조적 접근이 가능한 데이터 | 일반적인 SQL, 표 등 |
| 비정형 데이터 | 정형 데이터와 반대되는 개념으로 사진, 영상 등 구조적으로 접근하기 어려운 데이터 | NoSQL, 이미지, 영상 등 |
| 히스토그램 | 연속형 데이터의 분포를 나타내기 위해 구간으로 나눈 후 각 구간의 빈도수를 막대 그래프로 표현한 것 | |
| 박스 플롯 | 데이터의 분포, 중앙값, 사분위 수, 이상치를 박스와 위스커로 표현한 것 | |
| 범주형 데이터 | 범주(Category)가 정해진 데이터 | 제품의 종류, 고객의 성별, 설문조사 등 |
| 연속형 데이터 | 특정 구간 내에서 이론적으로 무한한 값을 가질 수 있는 데이터 | 몸무게, 키 등 |
| 시계열 데이터 | 시간의 흐름에 따라 일정한 간격 등으로 측정된 연속적인 데이터 | 주식, 날씨, 센서 데이터 등 |
| 이동 평균 | 시계열 데이터에서 장기적인 패턴과 트렌드를 명확하게 구분하기 위해 일정 구간마다 평균값을 계산하는 방법 |
정형 데이터 처리와 비정형 데이터 처리
- 데이터 시각화는 복잡한 데이터나 정보를 그래픽, 차트, 다이어그램 등의 시각적 요소를 사용하여 직관적으로 이해하기 쉽게 표현하는 기술이나 과정
- 데이터 시각화는 데이터를 그래프나 차트와 같은 시각적 형식으로 표현하여 패턴, 추세, 인사이트(똑같은 통계라고 해도 어떻게 해석할 것인가?)를 효과적으로 전달하는 과정을 말한다.
- 데이터 시각화를 사용하는 이유는 복잡한 데이터를 직관적으로 표현하여 패턴과 의미를 쉽게 파악하기 위해서다.
정형 데이터(Structured Data)
- 정형 데이터는 표나 데이터베이스처럼 행(Row)과 열(Column)의 구조를 가진 체계적인 데이터이다.
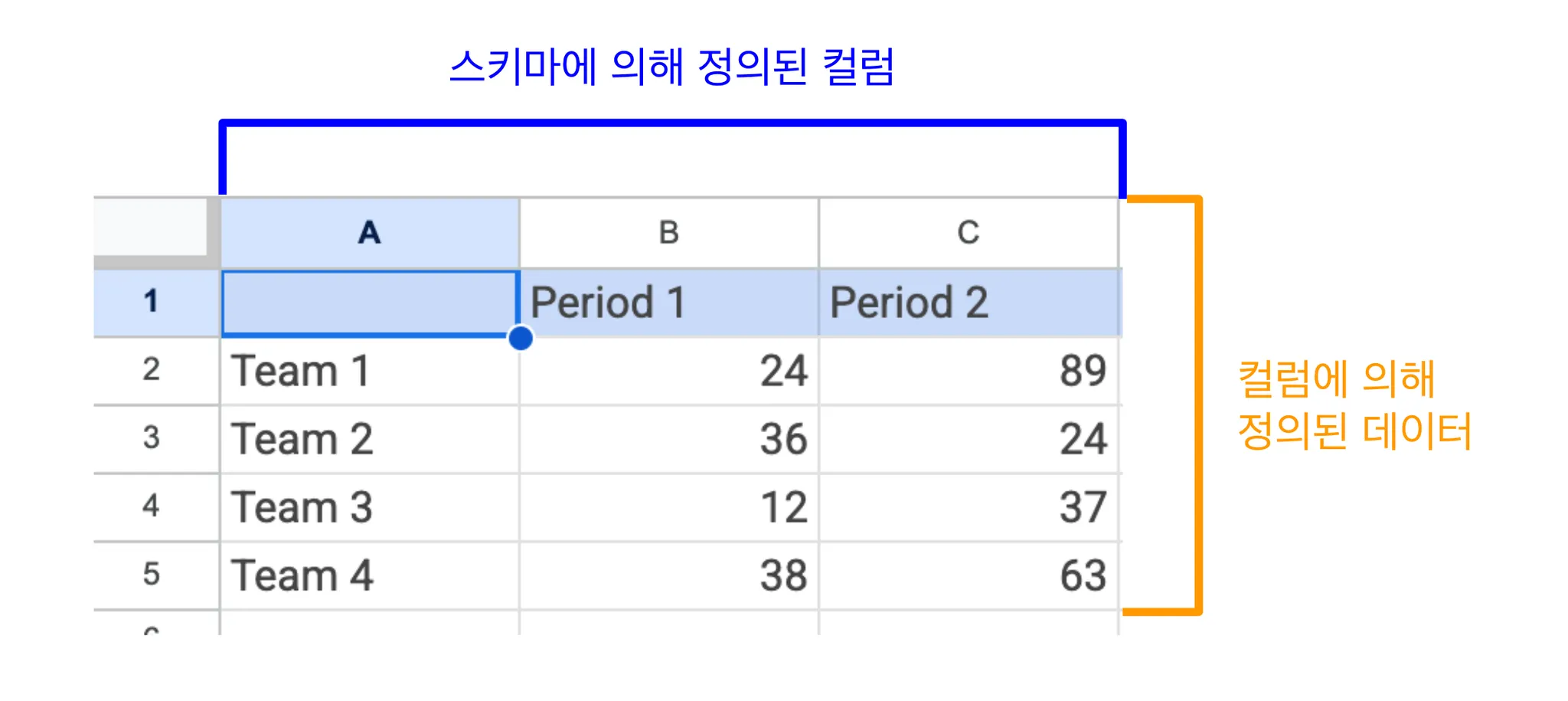
- 정형 데이터는 일반적으로 스키마(Schema)를 기반으로 구성되며, 각 열(Column)은 특정한 데이터 유형(예: 정수, 문자열, 날짜 등)을 가지며, 행은 개별적인 데이터 항목을 나타낸다.
- 정형 데이터는 데이터를 설명하는 추가적인 사위 데이터인 메타 데이터가 있고 데이터와 메타 데이터로 인해 구조적 접근이 가능하다.
- 정형 데이터의 생성
import pandas as pd data = { "ID": range(1, 11), "Name": ["Alice", "Bob", "Charlie", "David", "Eve", "Frank", "Grace", "Hank", "Ivy", "Jack"], "Age": [25, 30, 35, 40, 28, 33, 38, 45, 29, 31], "City": ["Seoul", "Busan", "Incheon", "Daegu", "Daejeon", "Gwangju", "Ulsan", "Jeju", "Suwon", "Changwon"], "Salary": [50000, 55000, 60000, 65000, 52000, 58000, 62000, 70000, 53000, 56000] } df = pd.DataFrame(data) df출력
index ID Name Age City Salary 0 1 Alice 25 Seoul 50000 1 2 Bob 30 Busan 55000 2 3 Charlie 35 Incheon 60000 3 4 David 40 Daegu 65000 4 5 Eve 28 Daejeon 52000 5 6 Frank 33 Gwangju 58000 6 7 Grace 38 Ulsan 62000 7 8 Hank 45 Jeju 70000 8 9 Ivy 29 Suwon 53000 9 10 Jack 31 Changwon 56000 - 정형 데이터의 탐색
# 데이터프레임 정보 확인 print("\n데이터프레임 정보") print(df.info()) # 데이터 샘플 확인 print("\n데이터 샘플 (앞부분)") print(df.head()) # 수치형 데이터 요약 통계량 print("\n수치형 데이터 요약 통계량") print(df.describe()) # 컬럼 확인 print("\n컬럼 목록") print(df.columns)출력
데이터프레임 정보 <class 'pandas.core.frame.DataFrame'> RangeIndex: 10 entries, 0 to 9 Data columns (total 5 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 ID 10 non-null int64 1 Name 10 non-null object 2 Age 10 non-null int64 3 City 10 non-null object 4 Salary 10 non-null int64 dtypes: int64(3), object(2) memory usage: 532.0+ bytes None 데이터 샘플 (앞부분) ID Name Age City Salary 0 1 Alice 25 Seoul 50000 1 2 Bob 30 Busan 55000 2 3 Charlie 35 Incheon 60000 3 4 David 40 Daegu 65000 4 5 Eve 28 Daejeon 52000 수치형 데이터 요약 통계량 ID Age Salary count 10.00000 10.000000 10.000000 mean 5.50000 33.400000 58100.000000 std 3.02765 6.131884 6244.108334 min 1.00000 25.000000 50000.000000 25% 3.25000 29.250000 53500.000000 50% 5.50000 32.000000 57000.000000 75% 7.75000 37.250000 61500.000000 max 10.00000 45.000000 70000.000000 컬럼 목록 Index(['ID', 'Name', 'Age', 'City', 'Salary'], dtype='object') - 데이터 필터링 및 변환
Pandas에서의 필터링 - 정형 데이터 정리 및 가공
Pandas에서의 결측치 처리 - 정렬 및 그룹화
Pandas에서의 그룹화 - 가공된 정형 데이터 저장 및 불러오기
Pandas에서는 다양한 형태의 자료를 읽고 쓰는 기능을 지원한다..read_*()메서드를 이용해 file 뿜낭 아니라 http주소로 된 데이터도 불러올 수 있으며.to_*메서드를 이용해 저장도 가능하다.
비정형 데이터(Unstructured Data)
- 비정형 데이터는 고정된 구조 없이 텍스트, 이미지, 영상, 오디오 등 다양한 형식으로 존재하는 데이터이다.
- 스키마가 없이 일정한 규칙으로 정리되지 않은 데이터이며 체계적인 저장 방식이 아닌 파일 시스템, 클라우드 스토리지, NoSQL(MongoDB 등) 데이터베티스 등에 저장되는 경우가 많다.
- 반정형 데이터(Semi-Structured Data) : 정형 데이터처럼 일부 구조를 가지지만 고정된 스키마 없이 유동적으로 저장되는 데이터이다. 메타 데이터가 일부 있지만 데이터베이스 테이블처럼 엄격한 구조는 없다. 대표적인 예로
.JSON이 있다. - 비정형 데이터를 활용하기 위해서는 정형 데이터로 변환하는 과정이 필요하다.
- 텍스트 데이터를 정형 데이터로 변환(토큰화 및 감성 분석)
- 이미지 데이터를 정형데이터로 변환 (특정 벡터 추출)
시각화 (Matplotlib, Seaborn)
Matplotlib
- Python 환경에서 다양한 형태의 차트와 그래프를 생성할 수 있도록 지원하는 기본적인 데이터 시각화 라이브러리이다. 라인 플롯(line plot), 바 차트(bar chart), 히스토그램(histogram), 산점도(scatter plot) 등 다양한 차트 유형을 지원한다.
- Matplotlib은 Python 환경에서 데이터를 효과적으로 시각화하고 다양한 유형의 그래프를 유연하게 생성 및 커스터마이징할 수 있기 때문이다. 단순한 선 그래프부터 히스토그램, 산점도, 3D 그래프까지 폭넓은 시각화를 지원한다.
- Matplotlib의
pyplot을 사용하며import를 통해 라이브러리를 불러온다. 일반적으로matplotlib.pyplot은plt로 불러오는 것이 관행이다.import matplotlib.pyplot as plt
막대 그래프
- 막대 그래프는 범주형 데이터의 크기 비교를 위해 각 범주를 막대의 길이로 표현하는 시각화 방법
- 막대 그래프는
matplotlib.pyplot의.bar()함수를 사용하여 범주형 데이터의 값을 막대로 표현할 수 있다. - 데이터 정의
import matplotlib.pyplot as plt categories = ['A', 'B', 'C', 'D', 'E'] values = [10, 20, 15, 25, 30] - 기본 막대 그래프
plt.bar(categories, values, color='')를 사용해 기본 막대그래프를 생성할 수 있다.
plt.xlabel('')를 사용해 X축 이름 설정 가능
plt.ylabel('')를 사용해 Y축 이름 설정 가능
plt.title('')를 사용해 그래프 제목 설정
plt.show()를 사용해 생성한 그래프를 화면에 출력
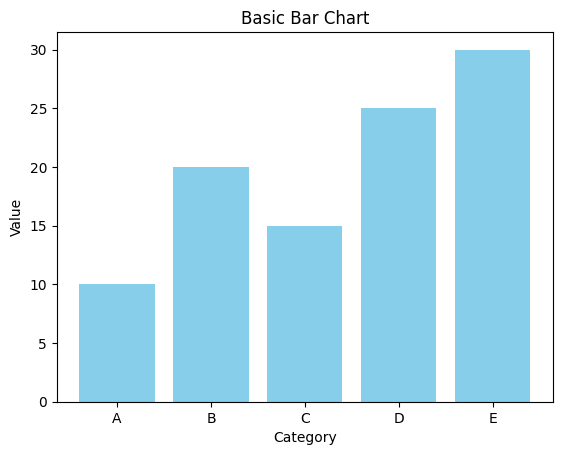
plt.bar(categories, values, color='skyblue') plt.xlabel('Category') plt.ylabel('Value') plt.title('Basic Bar Chart') plt.show()출력
- 가로 방향 막대 그래프
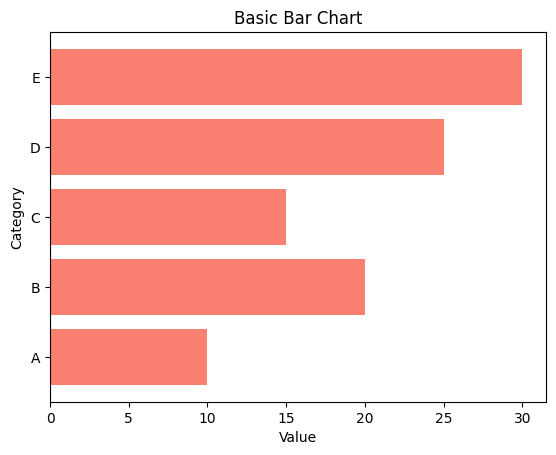
plt.barh()함수를 사용하여 가로 막대 그래프를 생성할 수 있다.plt.barh(categories, values, color='salmon') plt.xlabel('Value') plt.ylabel('Category') plt.title('Basic Bar Chart') plt.show()출력
- 누적형 막대 그래프
plt.bar()에서bottom = ''요소를 추가해 누적해서 그릴 수 있다.plt.bar(categories, values, color='skyblue') plt.bar(categories, values2, bottom=values, color='salmon') plt.xlabel('Category') plt.ylabel('Value') plt.title('Stacked Bar Chart') plt.show()출력
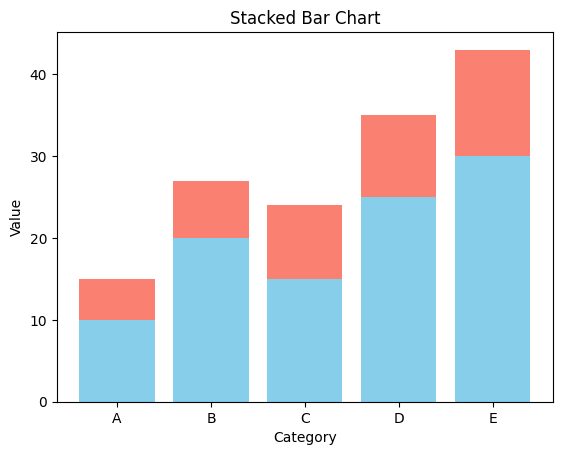
- 그룹형 막대 그래프
plt.bar()에서width을 추가하여 막대 그래프를 설정할 수 있다.import numpas as np x = np.arange(len(categories)) bar_width = 0.4 # 막대의 너비 설정 plt.bar(x - bar_width/2, values, width = bar_width, color='skyblue') plt.bar(x + bar_width/2, values2, width = bar_width, color='salmon') plt.xlabel('Category') plt.ylabel('Value') plt.title('Grouped Bar Chart') plt.show()출력
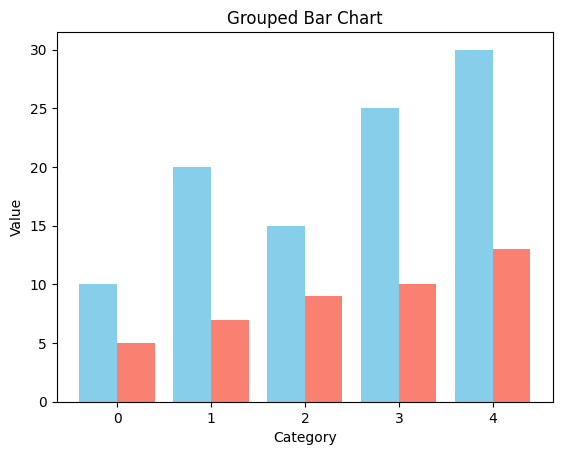
히스토그램
- 히스토그램은 연속형 데이터의 분포를 나타내기 위해 데이터를 구간 단위(bin)으로 나누고 각 구간의 빈도수를 막대로 표현하는 시각화 방법
- 히스토그램에서 빈(bin)은 데이터를 나누는 구간 단위를 의미하며 데이터를 일정한 간격으로 나누고 각 구간에 속하는 데이터 개수를 계산하여 막대의 높이로 나타낸다.
- 히스토그램을 사용하는 이유는 데이터의 분포 형태(대칭성, 치우침, 봉우리 수 등)를 직관적으로 파악하기 위해서이다. 분포의 형태, 봉우리 개수, 범위 등을 파악함으로써 데이터가 어떤 특성을 가지는지를 쉽게 파악할 수 있다.
- 기본 히스토그램
plt.hist()함수를 사용하여 연속형 데이터를 구간별로 나누고 각 구간에 속하는 데이터 개수를 막대로 표현할 수 있다.
plt.hist()안에bins =을 통해 히스토그램의 구간을 나눌 수 있다.import matplotlib.pyplot as plt import numpy as np # 예시를 위한 랜덤 데이터 생성 (정규 분포) data = np.random.randn(1000) # 평균 0, 표준편차 1인 정규 분포에서 1000개의 데이터 추출 # 기본 히스토그램 생성 plt.hist(data, bins=20, color='skyblue', edgecolor='black') plt.xlabel("Value") # X축 라벨 설정 (데이터 범위) plt.ylabel("Frequency") # Y축 라벨 설정 (빈도) plt.title("Basic Histogram") # 그래프 제목 설정 plt.show()출력
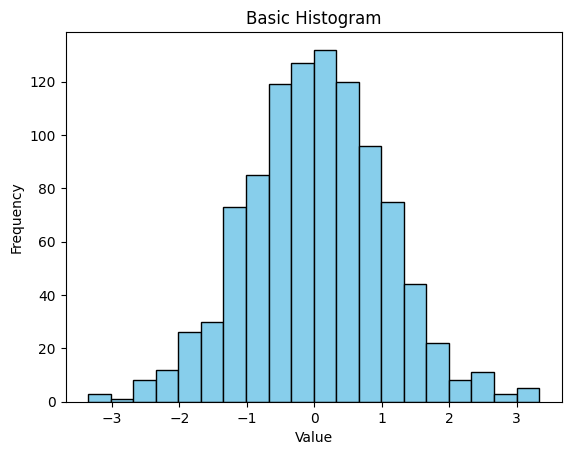
- 누적 히스토그램
plt.hist()안에cumulative = True를 추가하면 누적 빈도 히스토그램을 생성할 수 있다.plt.hist(data, bins=20, cumulative=True, color='salmon', edgecolor='black') plt.xlabel("Value") plt.ylabel("Cumulative Frequency") plt.title("Cumulative Histogram") plt.show()출력
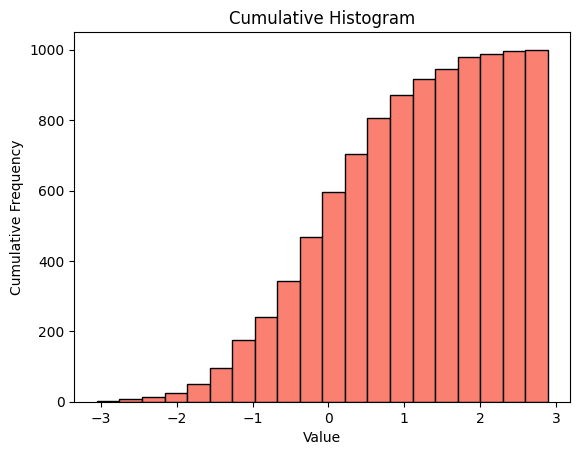
산점도
- 산점도는 변수 간의 관계를 나타내기 위해 각 데이터 점을 좌표 평면에 점으로 표현하는 시각화 방법이다. 일반적으로 하나의 변수 값을 x축, 다른 변수 값을 y축에 배치하여 두 변수 간의 관계를 시각적으로 나타낸다. 데이터가 특정 패턴을 형성하는 경우 변수 간의 상곽관계를 파악할 수 있으며, 분포의 형태나 이상값도 쉽게 확인할 수 있다.
- 산점도는 변수 간의 관계를 시각적으로 표현하여 데이터의 패턴, 이상값, 군집을 직관적으로 파악하기 위해서 사용한다. 데이터를 좌표 평면에 점으로 표시함으로써 변수간의 패턴, 이상값, 상관관계, 군집 등을 한 눈에 확인할 수 있다.
- 산점도는
plt.scatter()메서드를 이용해 그릴 수 있다.
color =는 marker의 색깔,marker =는 marker의 모양,alpha =는 marker의 투명도,s =는 marker의 크기이다.import numpy as np import matplotlib.pyplot as plt x = np.random.randn(50) y = np.random.randn(50) plt.scatter(x, y,color='skyblue', marker='o', alpha=0.7, s=100) plt.xlabel("Random X") plt.ylabel("Random Y") plt.title("Scatter Plot") plt.show()출력
박스 플롯(Box Plot)
- 박스 플롯은 데이터의 분포, 중앙값, 사분위수, 이상치를 시각적으로 나타내는 시각화 방법으로 박스(Box)와 수염(Whisker)로 구성되며 데이터의 최소값, 1사분위(Q1), 중앙값(Q2), 3사분위(3Q), 최대값을 나타낸다. 또한 이상값(Outlier)이 존재할 경우 별도로 표시한다.
- 박스 플롯은 데이터의 중심, 분포, 이상치를 직관적으로 파악하여 분석 과정에서 오류를 최소화하고 정확한 결론을 도출하기 위해 사용된다.
-
박스 플롯의 구성요소
구성요소 설명 박스(Box) 데이터의 1사분위(Q1) ~ 3사분위(Q3)를 나타내며, 데이터의 중앙 50%가 포함되는 영역 중앙값(Median, Q2) 박스 내부의 굵은 선으로, 데이터의 중앙값 1사분위(Q1) 데이터 값들을 작은 순서로 정렬했을 때 25%에 해당하는 값으로, 하위 25%의 데이터를 포함 3사분위(Q3) 데이터 값들을 작은 순서로 정렬했을 때 75%에 해당하는 값으로, 상위 25%의 데이터를 포함 IQR Q3 - Q1 (3사분위 - 1사분위) 로 계산되며, 데이터의 중앙 50%의 범위 수염(Whiskers) Q1 - 1.5 × IQR ~ Q3 + 1.5 × IQR범위 내에서 가장 작은 값과 가장 큰 값을 연결하는 선최소값(Min) Q1 - 1.5 × IQR보다 크거나 같은 가장 작은 값최대값(Max) Q3 + 1.5 × IQR보다 작거나 같은 가장 큰 값이상값(Outliers) 수염(Whiskers)의 범위를 벗어난 값으로 IQR의 1.5배를 초과하는 값, 일반적으로 점으로 표시 - 박스 플롯은
plt.boxplot()메서드를 사용하여 생성 가능하다. 박스 플롯은plt.boxplot()내부에data를 넣고patch_artist = True를 통해 내부를 색칠할 수 있다.
boxprops = dict()를 통해 박스 내부에facecolor = " "를 통해 박수 내부의 색상을,color = " "를 통해 박스 테두리 색깔을 지정할 수 있다.
마찬가지로whiskerprops = dict()에color = " "를 통해 위스커의 색깔을,linewidth =를 통해 두께를 설정할 수 있다.
그 외에capprops = dict()를 통해 박스 끝 선을 조정하고medianprops = dict()를 통해 중앙값 선을 조정할 수 있다.data = np.random.randn(100) plt.boxplot(data, patch_artist=True, boxprops=dict(facecolor="salmon", color="red"), whiskerprops=dict(color="black", linewidth=1.5), capprops=dict(color="lightgreen", linewidth=1), medianprops=dict(color="orange", linewidth=2)) plt.title("Box Plot") plt.ylabel("Values") plt.show()출력
고급 다중 그래프
- 고급 다중 그래프는 하나의 Figure 내에서 여러 개의 그래프를 배치하여 다양한 데이터 관계를 동시에 시각화하는 기법니다. 고급 다중 그래프는 데이터의 흐름, 비교, 상관관계를 한 눈에 파악할 수 있으며 다양한 차트 유형을 조합하여 복합적인 정보를 효과적으로 전달할 수 있다.
- 고급 다중 그래프는 하나의 Figure 내에서 여러 개의 그래프를 배치해 서로 다른 데이터 간의 관계를 한 눈에 비교하고 다각적인 분석을 하기 위해서 사용한다.
- 다중 그래프를 사용하기 위해서는
plt.subplots()를 사용하여 그래프를 배치하고 필요에 따라 공유 축, 스타일 조정, 다양한 시각화 기법을 사용할 수 있다.x = np.linspace(0, 10, 100) y1 = np.sin(x) y2 = np.cos(x) fig, axes = plt.subplots(2, 2, figsize=(10, 8)) # 선 그래프 axes[0, 0].plot(x, y1, color='b') axes[0, 0].set_title("Line Plot") # 산점도 axes[0, 1].scatter(x, y1, color='r') axes[0, 1].set_title("Scatter Plot") # 막대 그래프 axes[1, 0].bar(np.arange(5), [3, 1, 4, 1, 5], color='g') axes[1, 0].set_title("Bar Chart") # 히스토그램 data = np.random.randn(1000) axes[1, 1].hist(data, bins=20, color='purple') axes[1, 1].set_title("Histogram") plt.tight_layout() # 그래프 간 간격 자동 조정 plt.show()출력
벤다이어그램
- 벤 다이어그램은 여러 집합 간의 관계와 교집합을 시각적으로 표현하는 다이어그램이다.
- 벤 다이어그램은
matplotlib.venn()라이브러리를 활용하여venn2()혹은venn3()함수를 사용하여 만들 수 있다.import matplotlib.pyplot as plt from matplotlib_venn import venn2 set_A = {"사과", "바나나", "체리", "망고"} set_B = {"바나나", "망고", "포도", "수박"} # 벤 다이어그램 생성 venn2([set_A, set_B], set_labels=("Set A", "Set B")) plt.title("Basic Venn Diagram") plt.show()출력
Seaborn
- 통계적 데이터 시각화를 쉽게 구현할 수 있도록 고급 스타일과 기능을 제공하는 Python 데이터 시각화 라이브러리로 Seaborn은 Matplotlib을 기반으로 하며 Pandas의 데이터프레임과 잘 호환되도록 설계되어 있어 복잡한 시각화도 간단한 코드로 표현할 수 있다.
- Seaborn을 사용하는 이유는 데이터를 단순히 표현하는데 그치지 않고 변수 간 관계 데이터의 분포, 그룹 간 비교, 통계적 트렌드 등을 직관적으로 파악하기 위해서이다.
seaborn은sns로 불러오는 것이 관례이다.import seaborn as sns
범주형 데이터
- 데이터 시각화에서 범주형 데이터는 정해진 그룹이나 레이블을 가지는 데이터를 의미하며 일반적으로 명목형 또는 순서형 변수로 구성되며 수학적 연산이 불가능하고 시각화 방식이 다르다는 특징이 있다. 예를 들어 제품의 종류, 고객의 성별, 설문조사 응답 등은 모두 범주형 데이터에 해당한다.
- 데이터 시각화에서 범주형 데이터를 사용하는 가장 큰 이유는 그룹 간 차이와 패턴을 직관적으로 비교, 분석하기 위해서이다. 범주형 데이터를 시각화하면 데이터의 패턴을 쉽게 파악하고 그룹 간 차이를 보다 효과적으로 분석할 수 있다.
- 샘플 데이터
import seaborn as sns import matplotlib.pyplot as plt import pandas as pd data = pd.DataFrame({ "Category": ["A", "A", "B", "B", "C", "C", "C", "A", "B", "C"], "Value": [10, 15, 7, 12, 22, 18, 25, 11, 9, 30] }) - Seaborn을 활용한 막대그래프
sns.barplot()을 이용해 범주형 데이터를 막대그래프로 표현할 수 있다.sns.barplot(x="Category", y="Value", data=data) plt.title("Basic Categorical Bar Plot") plt.show()출력
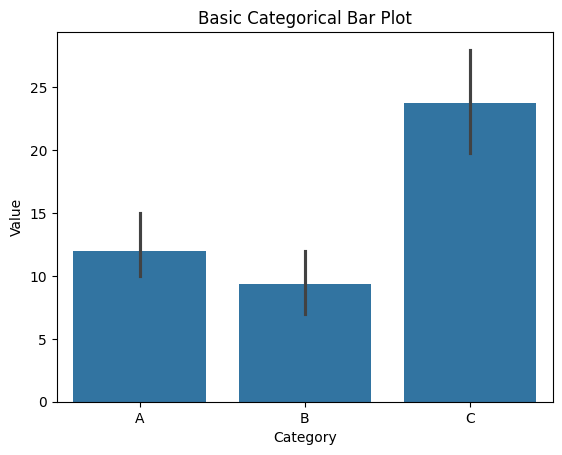
- Seaborn을 활용한 박스 플롯
sns.boxplot()을 이용해 범주형 데이터를 박스 플롯으로 표현할 수 있다.sns.boxplot(x="Category", y="Value", data=data) plt.title("Box Plot for Categorical Data") plt.show()출력
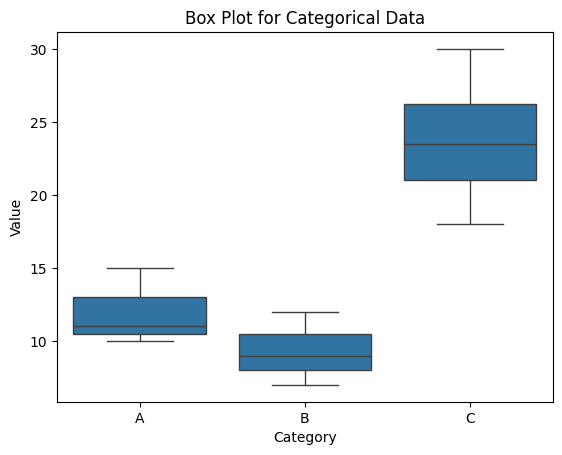
- Seaborn을 활용한 데이터 밀도와 분포(바이올린 플롯)
sns.violinplot()을 이용해 범주형 데이터의 밀도와 분포를 시각적으로 표현하는 바이올린 플롯을 생성할 수 있다.sns.violinplot(x="Category", y="Value", data=data) plt.title("Violin Plot for Categorical Data") plt.show()출력
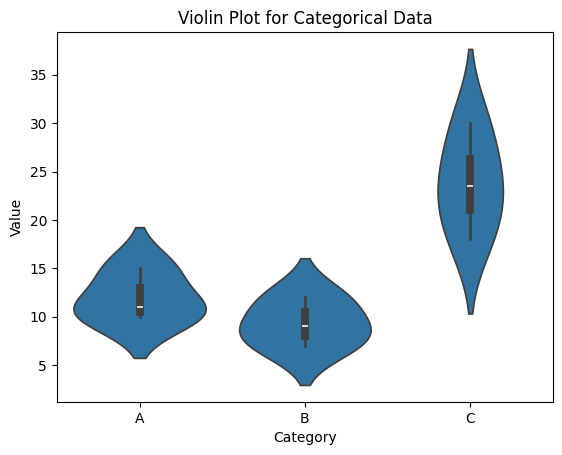
연속형 데이터
- 데이터 시각화에서 연속형 데이터는 특정 구간 내에서 이론적으로 무한한 값을 가질 수 있는 데이터를 말하며 두 데이터 값 사이에 이론적으로 무한한 수의 중간 값이 존재할 수 있다.
Seaborn에서는 연속형 데이터를 시각화할 수 있는 다양한 그래프를 제공하기 때문에 데이터의 분포, 패턴을 직관적으로 분석할 수 있다. - 연속형 데이터를 사용하는 이유는 수치적 관계를 정량적으로 분석하고 미래 변화를 예측하기 위해서이다. 연속형 데이터는 수치적으로 연속된 값을 가지므로 정량적 분석이 가능하며 패턴을 탐색하거나 미래 변화를 예측할 때 주로 사용한다.
- Seaborn을 활용한 히스토그램
sns.histplot()을 이용해 연속형 데이터를 히스토그램으로 표현할 수 있다.
sns.histplot()안에kde = True인자를 넣으면 확률 밀도와 함께 표현이 가능하다.import seaborn as sns import numpy as np import matplotlib.pyplot as plt data = np.random.randn(1000)sns.histplot(data, bins=30, color='skyblue') plt.xlabel("Value") plt.ylabel("Frequency") plt.title("Basic Histogram") plt.show()출력
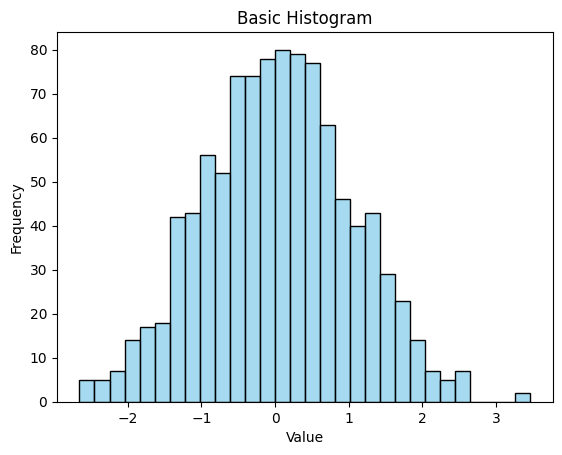
sns.histplot(data, bins=30, kde = True, color='salmon') plt.xlabel("Value") plt.ylabel("Frequency") plt.title("Histogram with KDE") plt.show()출력
- Seaborn을 활용한 선 그래프
sns.lineplot()을 이용해 연속형 데이터를 선 그래프로 표현할 수 있다.x = np.linspace(0, 10, 100) y = np.sin(x) plt.figure(figsize=(8, 6)) sns.lineplot(x=x, y=y, color='royalblue') plt.xlabel("X-axis") plt.ylabel("Y-axis") plt.title("Line Plot") plt.show()출력
- Seaborn을 활용한 산점도
sns.scatterplot()을 이용해 연속형 데이터를 산점도로 표현할 수 있으며sns.regplot()을 이용해 회귀선이 포함된 산점도를 표현할 수 있다.np.random.seed(0) x = np.random.rand(100) * 10 y = x + np.random.randn(100) plt.figure(figsize=(8, 6)) sns.scatterplot(x=x, y=y, color='salmon') plt.xlabel("X-axis") plt.ylabel("Y-axis") plt.title("Scatter Plot") plt.show()출력
plt.figure(figsize=(8, 6)) sns.regplot(x=x, y=y, color='lightgreen') plt.xlabel("X-axis") plt.ylabel("Y-axis") plt.title("Scatter Plot with Regression Line") plt.show()출력
관계 데이터
- 데이터 시각화에서 관계 데이터는 두 개 이상의 변수 간의 상관관계나 패턴을 분석하는 데이터를 의미하며 관계 데이터는 주로 수치형 데이터 간의 상관관계를 분석하는데 활용되며, 산점도, 회귀선이 포함된 산점도, 페어 플롯 등 다양한 시각화 기법으로 표현할 수 있다.
- 관계 데이터를 사용하는 이유는 변수 간의 관계를 파악하여 데이터 기반의 예측, 최적화, 의사 결정을 정확하고 효과적으로 하기 위해서이다. 관계 데이터를 분석하면 특정 변수가 다른 변수에 미치는 영향, 변수 간 상관성, 데이터의 그룹화 가능성 등을 파악할 수 있다.
- 회귀선이 포함된 산점도 등으로 데이터간의 관계를 나타낼 수 있으며
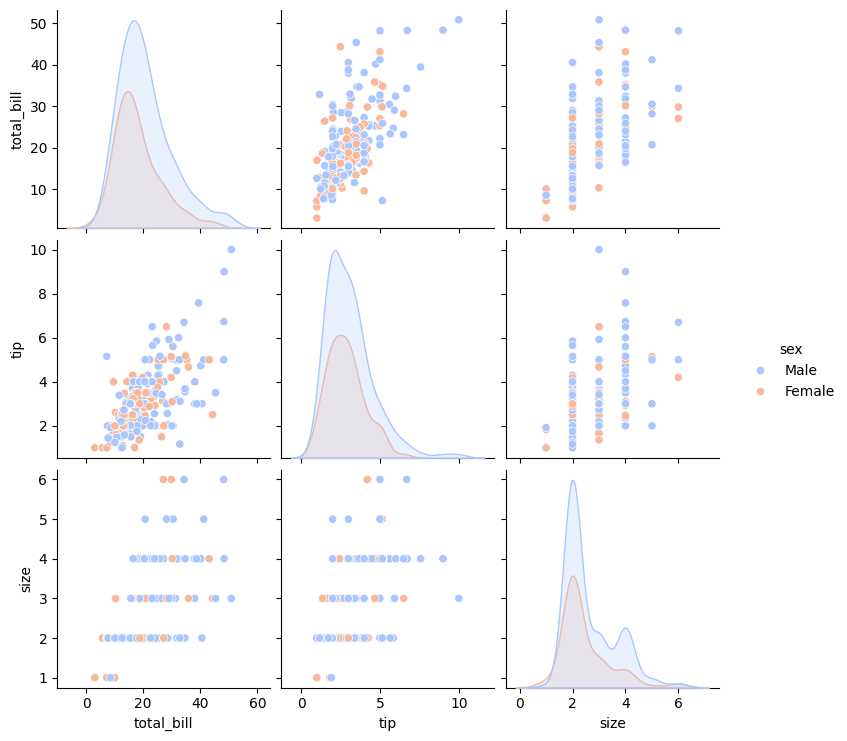
sns.pairplot()을 이용해 여러 변수 간의 관계를 한 번에 시각화할 수 있다.import seaborn as sns import matplotlib.pyplot as plt # 예제 데이터 로드 (Seaborn 내장 데이터셋: tips) tips = sns.load_dataset("tips") # 식당 팁 데이터셋 로드 sns.pairplot(tips, vars=["total_bill", "tip", "size"], hue="sex", palette="coolwarm") plt.show()출력
시계열 데이터 활용
시계열 데이터(Time Series Data)
- 시계열 데이터는 시간의 흐름에 따라 일정한 간격(초, 분, 시간, 일, 월, 년 등)으로 측정된 연속적인 데이터를 말한다.
-
대표적인 시계열 데이터의 예시
예시 설명 주식 가격 변화 특정 기업의 주가가 일정 시간 단위로 측정된 시계열 데이터 날씨 특정 지역의 기온, 강수량, 습도등을 일정 주기로 기록한 기상 관측 데이터 웹사이트/앱 접속 트래픽 웹사이트나 앱에 접속한 사용자 수가 일정 간격 등으로 기록된 데이터 IoT 센서 데이터 제조 공장, 스마트 홈 등에서 센서를 통해 수집되는 각종 환경 데이터 환자 생체 데이터(의료) 환자의 심박수, 혈압, 체온 등을 일정 간격으로 측정한 모니터링 데이터 - 시계열 데이터를 사용하는 이유는 시간에 따른 변화를 분석하여 미래를 예측하고 불확실성을 줄이기 위함이다.
리샘플링
- 리샘플링은 시계열 데이터의 분석을 위해 데이터의 시간 간격을 재조정하여 다운 샘플링하거나 업 샘플링하는 과정을 말한다.
- 합성 데이터(Synthetic data)
인공적으로 생성된 데이터로 실제 세상의 이벤트(real-world events)로 생산되었다. - Sample은 전체 데이터 집합의 특성을 대표할 수 있는 부분 집합이며 Sample을 완벽히 무작위로 추출하는 것이 좋다.
- 리샘플링을 사용하는 이유는 불규칙한 시계열 데이터를 일정한 간격으로 정리하여 패턴과 트렌드를 명확하게 파악하기 위해서이다. 원본 시계열 데이터는 수집 환경에 따라 불규칙한 시간 간격을 가질 수 있으며 너무 세멀하거나 너무 드문 경우 적절한 분석이 어려울 수 있다.
-
리샘플링의 주요 개념
개념 설명 다운 샘플링 기존 데이터보다 더 긴 시간 간격으로 데이터를 집계하는 과정 업 샘플링 기존 데이터보다 더 짧은 시간 간격으로 데이터를 확장하는 과정 고정된 시간 간격으로 변환 리샘플링은 데이터의 시간 간격을 일정한 주기로 변경하는 것으로 데이터가 고정된 간격으로 정렬 집계와 보간 다운 샘플링에서는 시간 간격이 길어지므로 집계 연산이 필요
업 샘플링에서는 시간 간격이 짧아지므로 보간 기법을 활용해 새로운 값을 생성 - 리샘플링은 기본적으로 Pandas의
.resample()메서드를 사용하여 시계열 데이터를 다운샘플링 혹은 업샘플링 할 수 있다. - 샘플 데이터
import pandas as pd import numpy as np # 날짜 범위 생성 (2024년 1월 1일부터 1월 10일까지, 3시간 간격) date_rng = pd.date_range(start="2024-01-01", end="2024-01-10", freq="3h") # 데이터프레임 생성 df = pd.DataFrame({ "datetime": date_rng, "value": np.random.randint(10, 100, size=len(date_rng)) }) # datetime을 인덱스로 설정 df.set_index("datetime", inplace=True) print(df.head().reset_index())출력
datetime value 0 2024-01-01 00:00:00 93 1 2024-01-01 03:00:00 17 2 2024-01-01 06:00:00 82 3 2024-01-01 09:00:00 71 4 2024-01-01 12:00:00 23 - 다운 샘플링 (시간 간격 축소)
기존 데이터보다 긴 시간 간격으로 데이터를 집계하는 과정으로.resample()에 업샘플할 시간 간격을 추가하면 된다. 샘플 데이터가 3시간 단위 이므로"D"를 입력해 하루 간격으로 업샘플 할 수 있으며.mean()을 사용해 평균으로 집계할 수 있다.df_daily = df.resample("D").mean() print(df_daily.head())출력
value datetime 2024-01-01 41.125 2024-01-02 52.000 2024-01-03 54.875 2024-01-04 63.000 2024-01-05 63.625 - 업 샘플링 (시간 간격 확대)
기존 데이터보다 더 짧은 시간 간격으로 데이터를 집계하는 과정으로.resample()에 다운샘플할 시간 간격을 추가하면 된다. 샘플 데이터가 3시간 단위 이므로"H"를 입력해 1시간 간격으로 다운 샘플할 수 있다..asfreq()를 이용해 기존 값이 없는 곳은NaN으로 입력하고 보간법은 추후에 설명한다.df_hourly = df.resample("h").asfreq() print(df_hourly.head().reset_index())출력
datetime value 0 2024-01-01 00:00:00 93.0 1 2024-01-01 01:00:00 NaN 2 2024-01-01 02:00:00 NaN 3 2024-01-01 03:00:00 17.0 4 2024-01-01 04:00:00 NaN -
보간법(Interpolation) 업 샘플링 후 결측값(
NaN)이 발생하면 이를 보간하여 채울 수 있으며 보간법은 데이터의 특성이 달라질 수 있으므로 그 목적에 맞는 방법을 선택해야 한다. 보간은 일반적으로df.interpolate()을 이용해 보간할 수 있다.보간법 메서드 설명 특징 선형 보간 df.interpolate(method = "linear")두 인접한 값 사이를 직선으로 연결하여 NaN값을 채움데이터가 일정한 증가/감수 경향을 가질 때 유용 전방 채우기 df.interpolate(method = "ffill")NaN값을 바로 이전 값으로 채움이전 값이 유지되는 데이터에서 사용 후방 채우기 df.interpolate(method = "bfill")NaN값을 바로 다음 값으로 채움빠른 응답이 필요한 데이터에서 사용 다항식 보간 df.interpolate(method = "polynomial", order = n)다항식 회귀를 이용하여 보간 곡선형 패턴이 잇는 경우 적합하지만 과적합 위험이 존재 스플라인 보간 df.interpolate(method = "spline", order = n)스플라인 보간법을 이용하여 부드러운 곡선으로 채움 곡선형 패턴이 자연스러워야 할 때 유용 시간 보간 df.interpolate(method = "time")시간 간격을 고려하여 보간 시계열 데이터에서 시간 흐름을 유지할 때 유용 제곱 보간 df.interpolate(method = "quadratic")2차 곡선(포물선) 형태로 보간 데이터가 곡선 형태로 변화하는 경우 적합 이동평균
- 데이터 시각화에서 이동평균은 시계열 데이터의 변동성을 완화하고 장기적인 추세를 파악하기 위해 일정 구간의 평균값을 계산하는 기법을 의미
-
이동평균은 시계열 데이터에서 변동성을 줄이고 장기적인 패턴과 트렌드를 명확하게 분석하기 위해서 사용한다. 원본 데이터는 단기 요인에 의해 급격한 변동이 발생하기 쉬워 흐름을 파악하기 어렵기 때문이다.
이유 설명 변동성(Noise) 감소 원본 데이터는 단기 변동이 잦아 패턴 파악이 어려울 수 있어 이동평균은 이런 변동을 부드럽게 하여 전체 흐름을 쉽게 분석하게 해준다. 장기적인 트렌드 분석 단기적 요인으로 인해 급격한 변화가 있을 경우, 장기 추세를 파악하기 어려울 수 있어 이동평균을 사용하면 데이터를 부드럽게 조정해 장기적인 흐름을 강조할 수 있다. 이상 탐지 및 변동성 분석 갑작스러운 값의 변화(이상치)가 발생했는지 식별하는데 유용하다. 이동평균과 원본 데이터를 비교하면 특정 지점에서 급격한 변화가 있었는지 쉽게 확인할 수 있다. 예측 모델링에서 활용 머신러닝 및 시계열 예측 모델에서 중요한 전처리 방법으로 이동평균을 통해 노이즈를 줄이면 더 신뢰도 높은 입력 데이터를 생성할 수 있다. - 단순 이동평균(SMA)
단순 이동평균은 윈도우 내 모든 값을 동일한 가중치로 평균을 계산하는 방식이다.# 데이터: 10, 20, 30, 40, 50 첫 번째 이동평균: (10 + 20 + 30) / 3 = 20.0 두 번째 이동평균: (20 + 30 + 40) / 3 = 30.0 세 번째 이동평균: (30 + 40 + 50) / 3 = 40.0- 계산이 직관적이고 단순하다.
- 최근 데이터의 변화를 신속하게 반영하지 못할 수 있다.
- 장기적인 흐름을 분석하는데 적합하다.
- 지수 이동평균(EMA)
지수 이동평균은 최근 데이터에 더 높은 가중치를 부여하여 변동에 더 민감하게 반응하는 방식이다.# 데이터: 10, 20, 30, 40, 50 첫 번째 EMA: 10.0 (초기값) 두 번째 EMA: (20 * α) + (10 * (1 - α)) = 15.0 세 번째 EMA: (30 * α) + (15 * (1 - α)) = 22.5 네 번째 EMA: (40 * α) + (22.5 * (1 - α)) = 31.3 다섯 번째 EMA: (50 * α) + (31.3 * (1 - α)) = 40.6- 최근 데이터의 변화를 빠르게 반영한다.
- 노이즈를 줄이면서도 신속한 반응이 필요한 경우 유용하다.
- 금융 시장에서 주가 변동 분석 등에 자주 사용된다.
- 가중 이동평균(WMA)
가중 이동평균은 최근 값에 더 큰 가중치를 부여하되, 지수 이동 평균보다 선형적인 방식으로 가중치를 적용하는 방법이다.# 데이터: 10, 20, 30, 40, 50 첫 번째 WMA: (10 * 0.1) + (20 * 0.3) + (30 * 0.6) = 25.0 두 번째 WMA: (20 * 0.1) + (30 * 0.3) + (40 * 0.6) = 36.0 세 번째 WMA: (30 * 0.1) + (40 * 0.3) + (50 * 0.6) = 46.0- 단순 이동평균보다 최근 데이터의 가중치를 높여 빠른 반응을 제공한다.
- 지수 이동평균보다 선형적으로 변동을 반영한다.
- 특정 구간 내에서 가중치를 조절하여 트렌드를 분석할 때 유용하다.
금융 데이터
- 데이터 시각화에서 금융 데이터는 주식 가격, 거래량, 환율, 금리 등 금융 시장에서 발생하는 시계열 기반의 데이터를 의미한다. 금융 데이터는 시간의 흐름에 따라 변동하는 연속형 데이터로 시장 움직임을 분석 및 예측하는데 중요한 역할을 한다. 금융 데이터는 크게 가격 데이터와 거래 데이터로 구분할 수 있다.
- 금융 데이터를 사용하는 이유는 자본의 흐름을 분석하여 경제 활동을 에측하고 최적의 의사결정을 내리기 위해서이다. 금융 데이터는 경제 활동을 분석하고 미래를 예측하는 핵심 자료로 활용된다.
SciPy
- SciPy(Scientific Python)는 과학 계산과 통계 분석을 위한 고급 수학 함수와 알고리즘을 제공하는 Python 라이브러리이다. SciPy는 NumPy를 기반으로 구축되었으며 다양한 수학적 함수와 알고리즘을 제공하여 과학, 공학, 데이터 분석 분야에서 폭넓게 활용된다.
- SciPy는 단순한 수학 연산을 넘어 최적화, 보간, 선형대수, 신호처리, 확률 분포 및 통계 분석, 미적분 계산, FFT 변환 등과 같은 고급 과학 계산 기능을 지원한다.
정규 분포
- 정규 분포는 데이터가 평균을 중심으로 좌우 대칭을 이루며 종형 곡선을 따르는 확률 분포이다. 정규 분포는 자연 현상과 다양한 실험 데이터에서 빈번하게 나타나는 분포이며, 통계 분석 및 머신러닝에서 가장 중요한 확률 분포 중 하나이다.
- 정규 분포는 평균과 표준 편차에 의해 결정되는 확률 분포이며 데이터가 평균을 중심으로 분포하는 중요한 통계적 모델이다.
- 정규 분포를 사용하는 이유는 많은 데이터가 정규 분포를 따르며 분석과 예측을 단순하고 정확하게 할 수 있기 때문이다.
-
표준 정규 분포와 Z-점수 변환
\[Z = (x - μ) / σ\]
정규 분포를 표준화하면 평균이0, 표준 편차가1인 분포가 되며 이를 표준 정규 분포라고 한다. 표준 정규 분포에서 Z-점수(Z-score)변환을 통해 원본 데이터를 표준화할 수 있다.
기술 통계(Descriptive Statistics)
- 기술 통계는 데이터를 요약, 정리하여 중앙 경향성, 산포도, 분포 형태 등의 지표를 계산하고 시각적으로 표현하는 분석 기법이다. 복잡한 데이터를 수치화해 한 눈에 파악할 수 있도록 도와주며 데이터의 패턴과 분포를 이해하고 이상값을 식별하는데 유용하다.
- 기술 통계를 사용하는 이유는 복잡한 데이터를 정리하고 요약하여 쉽게 이해할 수 있도록 하기 위해서이다.
가설 검정
- 가설 검정은 표본을 기반으로 통계적 가설의 참과 거짓을 검정하여 결론을 도출하는 과정이라는 의미이다. 관찰된 데이터가 단순 우연인지 실제로 의미 있는 차이나 효곽가 존재하는지를 판단하는 절차이다.
- 가설 검정은 보이는 차이가 유연이 아니라 통계적으로 유의미한 차이인지 검증하기 위해서 사용한다. 데이터를 시각화하면 패턴과 차이를 직관적으로 이해하기 쉬워지지만 그래프에서 보이는 차이가 실제로 의미있는 것인지 확인하려면 통계적 검증이 필요하다.
-
가설 검정은 기본 적으로 두 가지 가설을 세우는 것에서 시작된다.
개념 설명 귀무가설(Null Hypothesis, $H_0$) 기본적으로 참이라고 가정하는 가설로 연구자가 반증하고자하는 대상 대립가설(Alternative Hypothesis, $H_1$) 검정하고자 하는 가설로 귀무가설과 반대되는 주장 1종 오류(Type I Error) 실제로 귀무가설이 참인데 이를 잘못 기각하는 오류 2종 오류(Type II Error) 실제로 대립가설이 참인데 귀무가설을 기각하지 않는 오류
통계적 시각화
- 통계적 시각화는 데이터의 분포, 관계, 추세 등을 효과적으로 분석하기 위해 통계적 기법을 활용하여 그래프나 차트로 표현하는 과정을 말한다. 단순한 시각화와 달리 통계적인 요약 및 분석을 포함하여 데이터의 패턴과 특성을 보다 깊이 있게 탐색하는 것이 목적이다.
- 통계적 시각화를 사용하는 이유는 데이터의 패턴과 분포를 직관적으로 파악하여 정확한 해석과 신뢰성 있는 분석을 하기 위해서이다. 데이터 분석에서 정확한 해석을 위해서는 평균, 표준 편차, 분산과 같은 수치적 통계 값만으로는 충분하지 않다.
오늘의 회고
- 데이터 시각화에 대해 잘 배울 수 있었으며
Matplotlib과Seaborn을 이용한 시각화 방법을 배울 수 있었다. 그 외에Scipy부분에서는 ADsP에서 공부한 내용으로 다시 한 번 복습할 수 있는 기회가 되었다.